
The simple truth is that IT systems are only as beneficial, as they are stable. Even the best service won’t matter much if the users can’t access it, which makes stability the most important factor during the design and development phases.
Unplanned downtime can be quite costly for your company due to lost productivity, lost revenue, and additional expenses. According to Gartner, the average cost is $5,600 per minute, so an hour of unavailability can mean losing north of $300,000. Downtime costs are lower for small and medium-sized businesses and bigger for huge corporations, and they can also vary depending on the industry. On the other hand, the smaller the company, the less money it has to burn, so you can say that stability is always an important and costly factor. Thus, it’s no surprise availability is often mentioned as one of the most important things when it comes to evaluating network services.
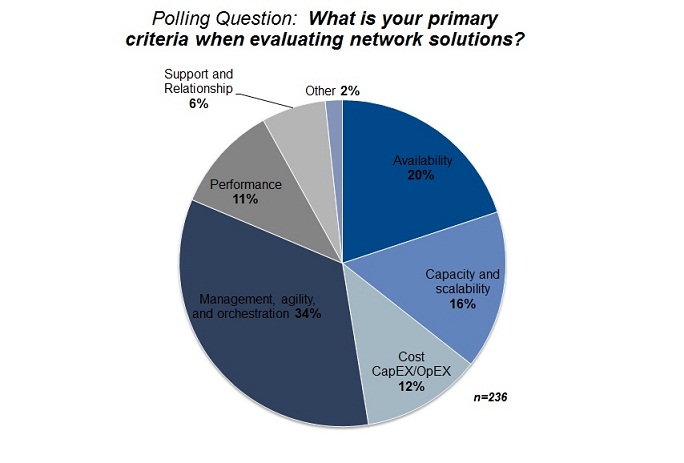
20% of respondents mentioned Availability as the primary concern – this shows us the importance of preventing unplanned network downtime. Source: Gartner.
Companies want to do what they can to minimize downtime. If you’re worried about this issue and don’t know how to proceed, here are a couple of tips coming from our experience as developers of custom, enterprise-grade systems.
Before we focus on steps you can make to fix the problem, let us first mention some of the things that can cause system downtime:

Cloud platforms like AWS or GCP are one of the best ways to ensure good system stability. Most professional, enterprise-grade services of this kind offer specific guarantees when it comes to uptime. And development companies that offer cloud migration services can design your architecture properly and employ safeguards to make sure everything runs as well as it possibly can.
It’s not 100% certainty, but often it’s not that far off – SLAs (Service Level Agreements) usually offer availability values well above 90%.
Many cloud providers also give us access to services like queues, messaging platforms, databases, and so on, which provide you HA and replication out-of-the-box, with automatic daily backups. These services are maintained by these companies. With these benefits, a large part of the responsibility for system uptime is not on your team’s side.
These things make the cloud a good way to overcome many potential downtime issues. And the best part? You don’t need to focus your attention on these things. You can concentrate on doing your job, working with your team, and offering the best products and services, while top-grade specialists (i.e. both the cloud provider and the cloud developers) make sure your system is stable.
Of course, the cloud can also offer your company many other pros – you can read about the various benefits of cloud vs on-premise in one of our guides.
Also when using a cloud platform you can schedule upscaling of your system when it’s necessary. Do you predict that peak traffic will appear on weekend afternoons? You can schedule rising additional nodes to your Kubernetes cluster so that it’s easier to upscale the number of pods. The system will be able to deal with more users without any issues. After peak time, the environment will cool down to a smaller scale to decrease the cost.
And last but not least, the cloud is not the perfect remedy that’ll provide you with infinite uptime. You need to remember to properly plan the architecture of your system, use the right elements from the cloud and, sadly, keep in mind that even the biggest cloud providers sometimes have to deal with a downtime event.
[post_frame text=”Schedule a call” link=”#contact”]Do you need help with migrating to cloud?[/post_frame]
Using multiple instances of your application is necessary if you want to keep it up. The easiest way is to use containers like Docker with orchestration software like Kubernetes or OpenShift. Orchestrators placed in clusters of more than one instance give you the possibility to scale up horizontally and also keep the system alive when a part of your infrastructure fails.
For example, you can have a Kubernetes setup based on the AWS cloud, which will be placed on two nodes, but with an autoscaling trigger set to attach another node whenever, CPU pressure will stay above 75% for a long enough time. On Kubernetes, you can configure spawning more pods with the application, depending on a metric (requests per minute, for example). To monitor and optimize such configurations, leveraging a solution such as the DORA metrics dashboard can provide insights into deployment frequency, lead time, and recovery metrics, helping teams enhance performance and reliability across the system.
Also, thanks to more than one node, your application will be kept alive when a part of the cluster fails. Kubernetes tries to balance placing pods between instances in the cluster. However, there’s one important thing: your auto-scaling has to be fast. You don’t want help to arrive when it’s too late.
Zero-downtime deployments are another benefit of using many instances and orchestration. You’ll be able to roll out a new version of an application using the Rolling Update or Blue-Green strategy, which assures you that at least one instance of your service will work. Also if deployment of the new version fails, with an orchestrator you can easily roll back to the previous version that still works.
Containers, orchestrators, and multi-instance approach quickly bring us to the idea of microservices. But you have to remember that this architecture isn’t always the perfect cure for every issue. With divided and separated domains you also will get transaction difficulties and sometimes you’ll need to do a lot more work to implement new functionalities. On the other hand, with properly implemented microservices the downtime of a part of your system won’t affect the other parts, which will be independent and able to stay functional.
Improving deployments and reducing risks connected to them is yet another way to minimize system downtime. There’s no better way to do that than implementing CI/CD (Continuous Integration and Continuous Delivery). By using these practices you can automate the release of updates, as well as the testing process (both when it comes to the new features and so-called regression testing of existing parts of the system). CI/CD allows you to make these processes almost seamless. If you gain enough confidence in your tools and team, you can even start deploying directly to production – push updates to your system without causing any downtime at all.
Preparing scripts that deploy automatically can protect you from human mistakes. The most obvious one is forgetting one of the deployment steps or making a mistake of some kind during one of them. Using automated scripts assures you that every new deployment works the same way as the previous ones.
Measuring one of the four DORA metrics, deployment frequency can also help you prevent system downtime. By tracking how often new code changes are successfully deployed to production, teams can identify potential issues and address them before they cause downtime.

Backups won’t prevent a crisis from happening, but when it does happen, they will make returning things to normal much easier, quicker, and less expensive. In general, it’s a good idea to have at least three copies of your data, and one of them should be stored outside of your normal IT infrastructure. It’s also important to create such backups regularly to make sure the data is up-to-date and minimize the impact of your system going down. Maintaining backups can be a part of your CI/CD pipeline.
The more often you make backups, the better the RTO factor (Recovery Time Objective – the extent to which the interruption affects your system’s operation) will be when you need to recover your system. The best data backup approach is constant replication which may cause close to zero data loss when a system crash happens. However, this approach also has a downside – when you have a problem with data corruption, only periodical backups will be able to save you because replicated data will probably be corrupted too.
Backup environments are a good way to improve system uptime, especially if you combine cloud and on-premise platforms. You can use cold or warm copies of your production environment but keep them on another platform (for example, you place the main environment on AWS and keep the backup copy on-premise). With good traffic routing like domain-level health checks (available on AWS Route53, for example) when the cloud platform has issues, you can easily route traffic to the backup platform. Thanks to this you don’t need to depend on the cloud provider’s SLA. Even when one of the cloud supplier’s data centers is down, your application can stay fully functional. This approach is very expensive (you have to pay for the unused environment) and requires constant data replication but you can achieve an amazing level of uptime.

No matter what you do, your company will sometimes experience downtime events because some factors are outside your reach (for example, you can’t control the weather and prevent natural disasters). This means it’s very important to create proper procedures for such a situation. You need to make sure your staff knows how to respond to a system outage – what steps to take, who to contact, and so on. Preparation is crucial in such cases – proper planning can save you a lot of money (and prevent a headache or two).
You should perform load testing on your core IT systems – check if the infrastructure can process the requests and perform well during typical use cases. Load testing will also allow you to get ready for various crisis scenarios, such as a partial resource failure.
During load testing, you can track bottlenecks and be aware what is the ceiling of performance in the system. Bottlenecks should be optimized through many techniques like algorithm optimization, caching, or even changes in architecture or configuration. The earlier you track where issues might happen, the less chance of failure you’ll face. It’s a good idea to perform these kinds of tests regularly, and fix issues right after finding them.
The fact that your IT infrastructure works well in the first months of your business activity doesn’t mean it’ll automatically continue to do so down the line. You should always make sure your system is designed to be properly scalable so that you can expand its capabilities without too many issues, and it can continue to do its job after your company grows. Forward-thinking and future-proof technologies can go a long way toward preventing unnecessary system downtime. Nowadays, scalability is usually ensured by proper cloud configuration – you can read more about that in a case study of cloud migration consulting that allowed our client to scale up to over 60M monthly views.
When you design algorithms and functions, make sure the system can work no matter how much data it processes. You may be tempted to use algorithms with a bad complexity factor, and they might work fine for one user, maybe for ten of them… but when thousands of people use your application at the same time it will become very inefficient and slow. That, in turn, will surely cause a crash and a system failure.
Relying on too many systems and technologies is never a good idea – in fact, often it’s a road to disaster. You can encounter bugs, glitches, and stability problems, not to mention an excessive, needless level of complexity. You should make sure you use compatible solutions – ideally several technologies from the same vendor.
A good example is storing files in your system. You can do it in a BLOB (Binary Large Object – basically storing a lot of data as one, big file) in the database. But storing them directly on a hard drive is a better approach. The best way, however, is to cache them in a CDE (a Common Data Environment you can share your data in), especially a distributed one, which is provided in cloud platforms like CloudFront on AWS.
If you use the first approach – BLOB – you will have slow queries to DB and rapidly increasing size of tables, but technically everything will be in one place. The second idea will give you faster transfer and the lightest queries. The CDE is the best option because it will offload all traffic from your application to the cloud provider’s infrastructure point located as close as possible to the requestor.

Like any electronic device, computer hardware won’t work forever. As years go by, it wears out or simply becomes obsolete – no longer powerful and modern enough to properly handle new software solutions. This is why system upgrades are very important.
It’s a good idea to constantly monitor your equipment, make sure it’s clean, receives a proper, stable power output, and doesn’t overheat. Additionally, it’s equally important to understand when an old, trusty server should be retired and replaced with a new machine. This kind of investment might seem unnecessary at times but putting it off for too long might have severe consequences.
Of course, you can also shift the burden of hardware maintenance to a cloud provider by deciding on a cloud solution.
Creating software is not the end of the road – solutions also need to be properly maintained to function without issues. Maintenance is a continuous process and it’s a topic in and of itself. We’ve already covered it in one of our previous articles: System maintenance: Why IT companies don’t want to offer you such services – if you’re not sure what has to be done, and how to go about it, we encourage you to check that blog post out.
It’s something that many companies ignore to their detriment. Cybersecurity is very important and should never be neglected. In a way, this is a problem that can be overcome by fixing many different issues (including a lot of the things mentioned in this article). However, there’s one additional thing you can do, and that’s a security audit by a specialized, third-party company. It’s a great way to increase cybersecurity awareness in your team and expose potential issues you might not be aware of and ensure that everything is being done correctly. For example, this can include checking if an IP is using a VPN, enabling businesses to enhance their monitoring capabilities and strengthen defenses against potential malicious activities.
If any security issue happens it can result in data leakage (which is very bad because of law regulations and losing the trust of clients) or even corrupt your data or overload systems. One way of preventing this is patching every hole in the system that was detected by an audit.

But active prevention is as important as removing bugs. You should have mechanisms like firewalls and blacklists to prevent attackers from trying to breach the system. Services like AWS WAF are designed to block requests which might be DDoS attacks or even scan the payload to detect if someone is trying an SQL injection. When something like this is detected, the service immediately blocks the IP address and can raise alerts through an email or SMS gateway.
However, you can go one step further by preventing cyberattacks with automated pen testing. With a penetration test, you’ll try to breach your own systems like you were a hacker. If the automated system can get past your security features, then that means other malicious hackers can, too. You’ll need to patch these vulnerabilities immediately.
Taking care of your system downtime is – obviously – very important. Thankfully there’s a myriad of ways to the effects it has on your business. With some strategic planning and some forward-thinking investments, you can make sure your company will be bulletproof when it comes to system downtime – or at the very least it won’t needlessly burn money when an issue of this kind occurs.
If you need consultations or professional help, know that Pretius has a lot of experience with designing efficient and safe system architectures. Drop us a line at hello@pretius.com or use the contact form below – we’ll see what we can do to help.
System downtime is a period during which – for one reason or another – an IT system isn’t available to users. Planned downtime is a part of the system’s normal life cycle, whereas unplanned downtime is a result of some kind of an issue that has to be resolved (and quickly, because system failures generate costs).
Many things can cause system downtime – from hardware failures, human errors, power outages, and cyberattacks, ending with bad design and/or configuration.
If you want to know your yearly uptime percentage, calculate the number of hours in a year (usually 24×365=8760), check for how many hours your system ran without problems during that year, then divide the latter by the former, and multiple the result by 100 to get a percentage uptime value. Downtime value is whatever is left when you deduct your uptime percentage from 100%. For example, for a service that was unavailable for 20 hours in a given year, the uptime value is 99,78%, and the downtime percentage is 0,22%.




