In many companies XLSX files (file format that is created by MS Excel 2003+) are used as a standard report data carrier. In some cases this files even replaces simple tables in databases. But almost always there comes a time when these Excel files / data needs to be uploaded to a new system or needs to be share it via web application. In case of web applications which are developed in Oracle APEX, such a requirement appears extremely often – after all one of the main APEX ideas is to migrate business processes from spreadsheets to web.
The most common solution is converting XLSX file to CSV format and then uploading data from file to a database table using custom PL/SQL procedure. This is a simple and proven way, but due to the low flexibility is only suitable for loading files with fixed and predictable data format (the number of columns and their data types). In case of adding new column to the file or deletion of existing, we are forced to modify loading process and / or the target table. If we want to give user the ability to share data in a form of a report, then we have to also remember about update of APEX application.
It doesn’t change the fact, that there is a need of importing data directly from XLSX files and our customers won’t stop asking for it. So if there is a need, we must find a solution, right?
SELECT * FROM employees.xlsx ?
A perfect situation would be a possibility of choosing which data from XLSX file we want to load and which not. Or we could just preview what is in the file that was attached by user, without need of parsing data and loading it to temporary table. With a helping hand comes AS_READ_XLSX packege. I found it on Amis Technology Blog, where you can find some of its basic usage examples.
Package AS_READ_XLSX enables us to draw data directly from the BLOBs inserted into database. It is also possible to query files which are on the filesystem. To parse XML files it uses standard Oracle library. I tested it – it works also on XE database edition.
Sample query might look like this:
|
1
2
3
|
select
*
from table( as_read_xlsx.read( as_read_xlsx.file2blob( ‘DOC’, ‘Book1.xlsx’ ) ) ); /* for file “Book1.xlsx” which resides in dictionary “DOC” */
|
or
|
1
2
3
|
select
*
from table( as_read_xlsx.read( v_blob ) ); /* where “v_blob” is a variable that contains BLOB with XLSX file */
|
As a result of such query we will get flattened tree structure of XML file:
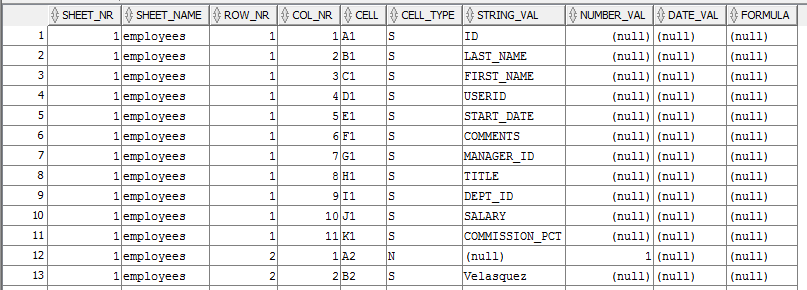
As we can see, there is all information we need: number and sheet name, number of a row, number of a column, cell address, data type and the data of appropriate database type. That’s something, but this is not yet the report we’d expect.
Reporting by pivoting
Using a bit of SQL acrobatics, we can make the above data become more readable. For this purpose, we will use the PIVOT function.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
with xlsx as (
select
ROW_NR,
COL_NR,
case CELL_TYPE
when ‘S’ then STRING_VAL
when ‘N’ then to_char(NUMBER_VAL)
when ‘D’ then to_char(DATE_VAL, ‘YYYY-MM-DD HH24:MI:SS’)
else FORMULA
end CELL_VAL — to make PIVOT works we have to have one data type for this column – in our case CHAR
from (select *
from table( as_read_xlsx.read( (select blob_content from XLSX_FILES where id = :P2_FILE_ID ),’employees’ ) )))
select ad.* fromxlsx
PIVOT
( max(CELL_VAL)
FOR COL_NR in (1 as ID,2 as LAST_NAME,3 as FIRST_NAME,4 as USERID,5 as START_DATE,6 as COMMENTS,7 as MANAGER_ID,8 as TITLE,9 as DEPT_ID,10 as SALARY,11 as COMMISSION_PCT )) ad
where row_nr >1 ; /* we want to omit headers row */
|
If everything is written correctly, we should see report like this:
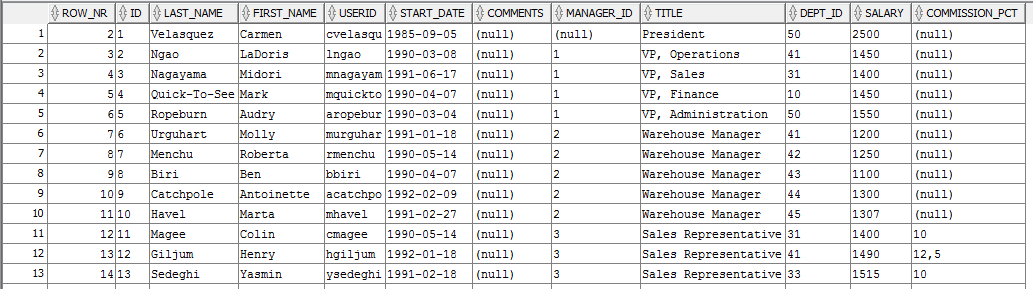
Having a report in this state, we are only one step before loading data to target table or creating report in APEX. And we achieve this without processing BLOB 🙂
Report in APEX
For our example, let’s assume that we want to report based on the first sheet of loaded XLSX file. For simplicity, assume that the first row contains column headers and data is in basic tabular form.
- Firstly, we create a simple form in order to filter our report. It will contain only one item – list of values with uploaded files list.
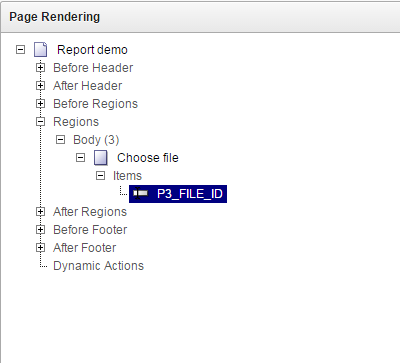
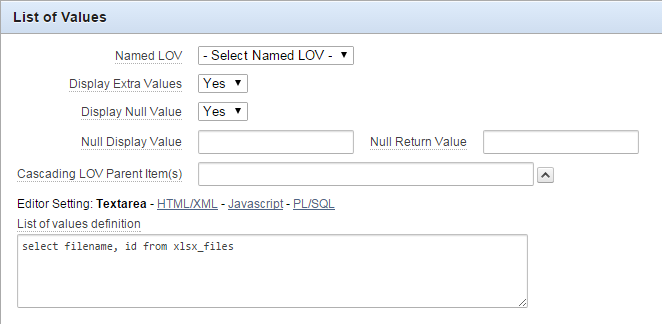
- Because we want to become independent of the number and names of columns in the XLSX file, we must have recourse to PL/SQL code. It will help us to dynamically build a query, namely the list of columns in PIVOT clause.
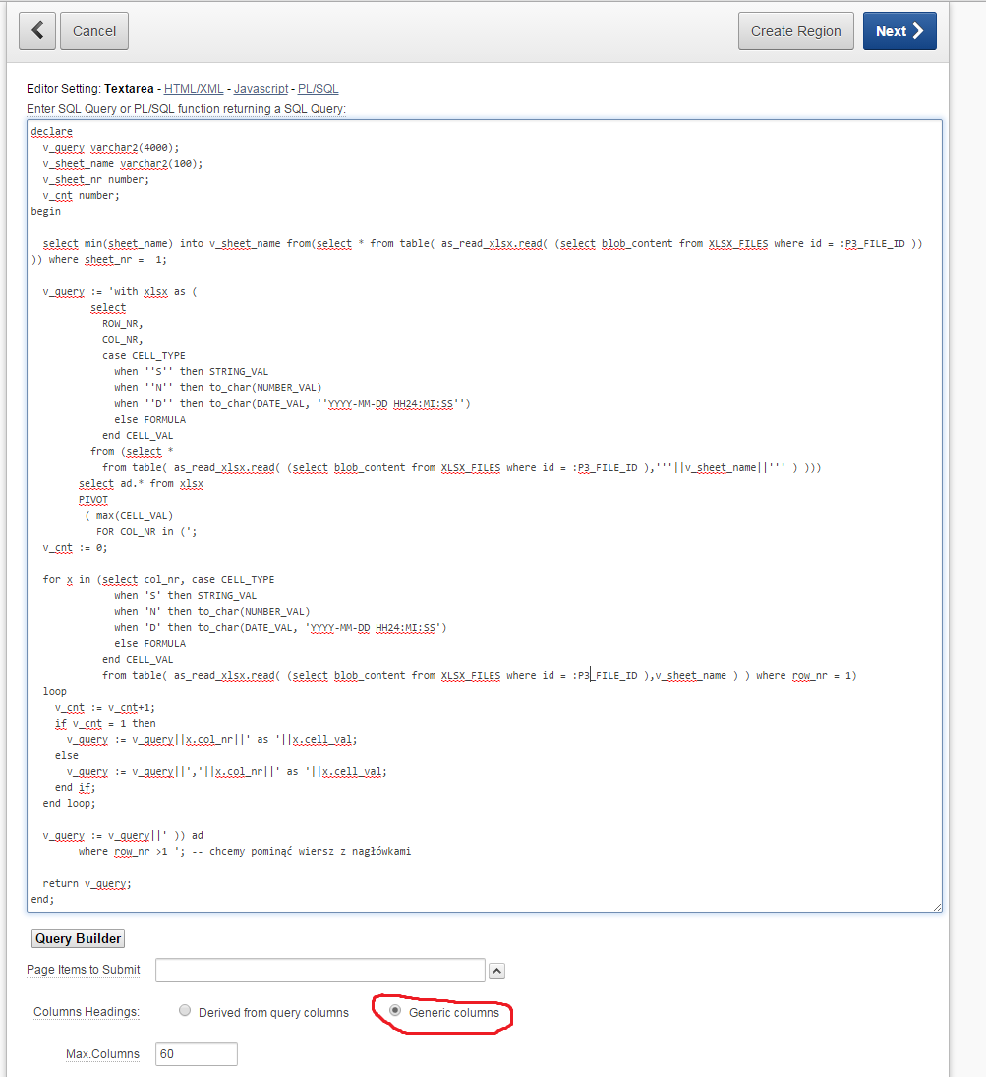
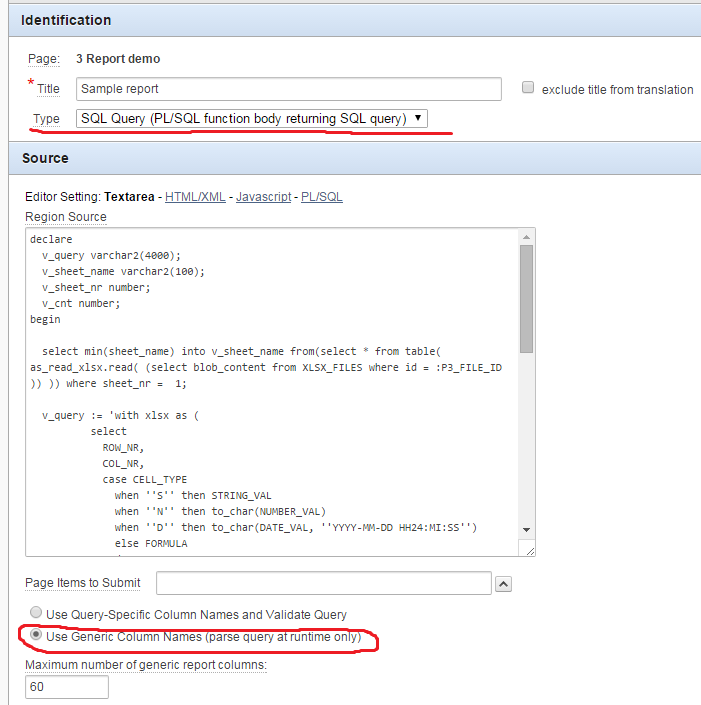
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849declarev_query varchar2(4000);v_sheet_name varchar2(100);v_sheet_nr number;v_cnt number;beginselect min(sheet_name) intov_sheet_namefrom(select * from table( as_read_xlsx.read( (select blob_content from XLSX_FILES where id = :P2_FILE_ID )) )) where sheet_nr = 1;v_query := ‘with xlsx as (selectROW_NR,COL_NR,case CELL_TYPEwhen ‘‘S’‘ then STRING_VALwhen ‘‘N’‘ then to_char(NUMBER_VAL)when ‘‘D’‘ then to_char(DATE_VAL, ‘‘YYYY-MM-DD HH24:MI:SS’‘)else FORMULAend CELL_VALfrom (select *from table( as_read_xlsx.read( (select blob_content from XLSX_FILES where id = :P3_FILE_ID ),’”||v_sheet_name||”‘ ) )))select ad.* from xlsxPIVOT( max(CELL_VAL)FOR COL_NR in (‘;v_cnt := 0;for x in (select col_nr, case CELL_TYPEwhen ‘S’ then STRING_VALwhen ‘N’ then to_char(NUMBER_VAL)when ‘D’ then to_char(DATE_VAL, ‘YYYY-MM-DD HH24:MI:SS’)else FORMULAend CELL_VALfrom table( as_read_xlsx.read( (select blob_content from XLSX_FILES where id = :P3_FILE_ID ),v_sheet_name ) ) where row_nr = 1)loopv_cnt := v_cnt+1;if v_cnt = 1 thenv_query := v_query||x.col_nr||‘ as ‘||x.cell_val;elsev_query := v_query||‘,’||x.col_nr||‘ as ‘||x.cell_val;end if;end loop;v_query := v_query||‘ )) adwhere row_nr >1 ‘; /* we want to omit headers row */return v_query;end; - Using the above code, we create a report. It has to be a classic report for two reasons. Firstly, in interactive report we can’t use PL/SQL code to generate query. And secondly, we need the ability to choose “Use Generic Column Names (parse query at runtime only)” option, because before running PL/SQL code we won’t know the number and names of the columns.
- Now, we just add a button to do a submit and we are ready to test this report.
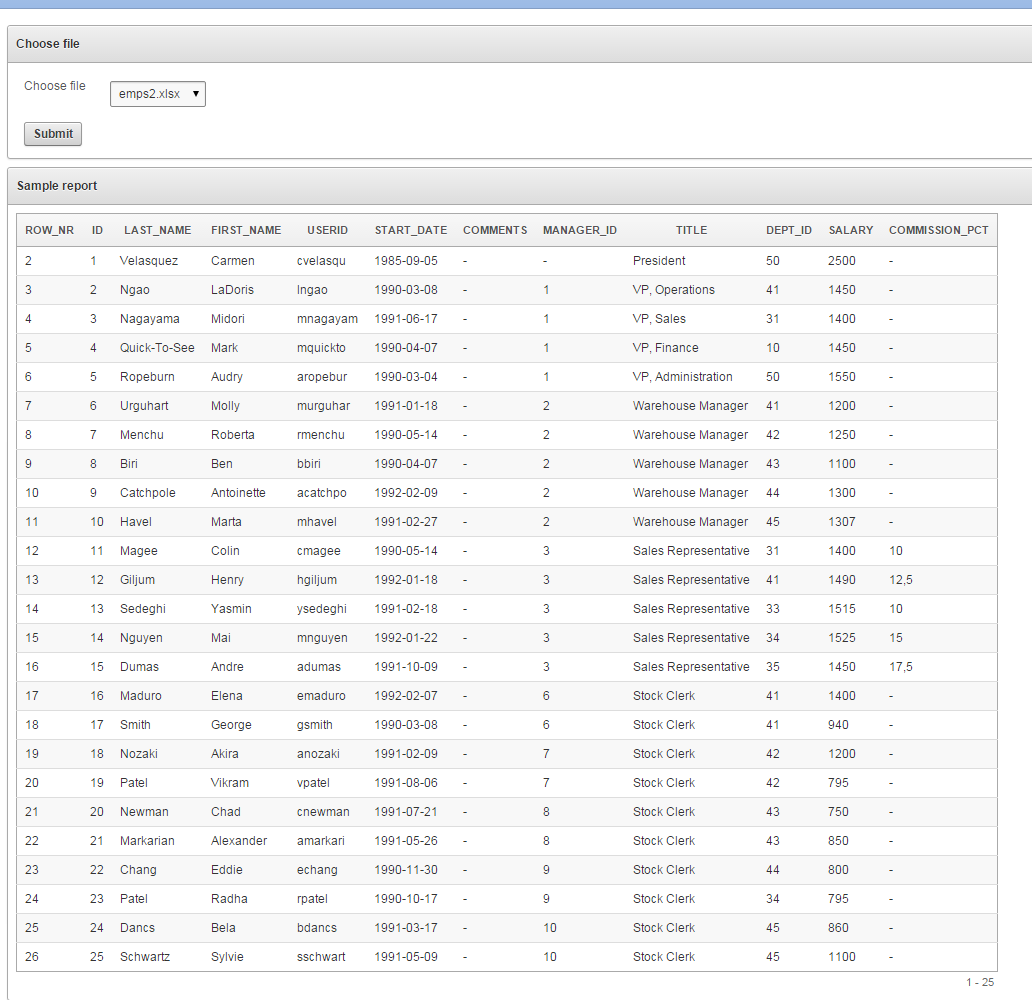
- Finished report should look like this
Limitations
Main limitations of this method are related to its main advantage, that is reading data directly from XLSX file. Because we are working on uploaded file, not on data in database tables, we can’t use many of database goodies such as indexes. Operations on data types are more difficult, cause using PIVOT function forces us to unification of returned data types – in above example it’s CHAR. What’s more, all operations are performed inside memory, so it can happen that trying to open a very large file we will fill the entire pool of memory. Additionaly, this mechanism will scale poorly – the bigger the file will be, the longer it will take to get results. The structure of data inside the file is also important. If data in spreadsheet is scattered instead of being in table form, then displaying it on report will be a challenge.
Summary
This method works well in case of sharing relatively small files in form of compact tabular reports, in which number of rows won’t exceed few hundreds. Another use case is previewing of data from file that user just have uploaded before it is inserted into database table. This package can also be used in process of transferring data from XLSX file to database table. However, if you want to process bigger files, you should consider pre-loading “raw” data to some kind of staging table before doing PIVOT transformation for further operations on data.
I attach a sample APEX application. Its functionality is very limited, but it allows to check how to implement file uploading process, pre-viewing of “raw” data from file and sample report with dynamic PIVOT clause and option to choose from which file and sheet display data. Application contains installation script, which creates any needed objects including AS_READ_XLSX package. If you want to download only package click here. I added to it one change, that APEX forced me to make. When APEX checks if query is valid, it inserts NULL into every bind variable. This resulted in hanging database session every time I wanted to create a report.
For demonstration purpose I assumed that uploaded files will be of simple structure: the data begins from A1 cell and first row contains column headers. You can download my demo file here. I used this file in above examples.