It’s quite simple to configure git for your development team. There are some good tutorials which show you step by step how to implement gitflow best practices in your company. But what if you are managing source code in your own repository and have to push it to customer repository? It’s still quite simple just add one more step to your gitflow. But what if customer repository could be changed by other teams (customers developers or other software vendors). One of our project team was struggling with this problem and worked out interesting solution.
In most of our team projects so far we’ve been the only software provider. We worked on our own repositories using quite a few different flows, trying to apply the best one to each case. During one of our latest projects, we had to provide the source code of our application to our client’s repository, however, we did not want to share our whole git history as we did not find it necessary. That is why we only moved the code between repositories after each release. The gitflow we used at that moment is presented on the first of below pictures. We used “Master” branch for our development and “Release” branch for versioning releases for testing and eventually for production. The colorful branches are obviously features and bugfixes, while the arrows explain how the code moved between branches and repositories during releases. Since our and our client’s repositories had no common root, merging the branches was out of the question and we had to use mechanisms like git format-patch or git cherry-pick to move the code.
Here’s an example how it worked from the start of the development to the production release:
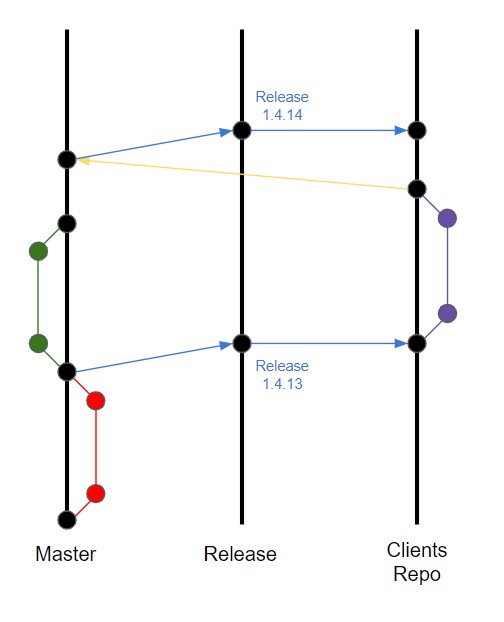
- Developer starts working on a bugfix/feature and creates a branch on master branch (red branch in the picture)
- Developer commits his changes and then creates a merge (pull) request
- Another developer or technical project leader reviews the code and eventually merges it into master
- Master branch is merged into release branch and a release version is created (blue arrow)
- At the same time the code is moved to client’s repository
This approach worked fine as long as the project had only one test environment and our team was the only software provider. However, when another teams appeared in the project and started working on our client’s repository things got a bit more complicated. The biggest problem was that we updated the above mentioned repository only during releases, which meant that the other software company often worked on outdated code (purple branch on the image above), which led to plenty of conflicts while merging their code with ours. Since there was no common root in the repositories, using the tools mentioned before such as git-patches and cherrypicks was also quite bothersome. In the end the developer preparing a release with the other company’s changes spent a lot of time on git operations – enough for us to change the approach.
We decided to change our client’s repository by having three branches in it – one for developing changes (called “Develop” – the equivalent of our old master), one for production release candidates which were tested on the newly created pre-production environment and the last one containing production code (master). Next we simply pushed those three branches onto our repository and started working on them, more or less the same way as we did before. The biggest difference was that both we and our client were working on the same main branch (it’s up to developers to keep their branches up to date with the develop branch). The branches were almost always in sync between repositories (we simply pushed to two remotes during feature or bugfix branch merges and also, since we only pushed commits that were a result of a merge onto our clients repository, the full git history of our changes was on our side). Hotfixes were created directly on Master branch and then merged into develop branch to keep everything up to date.
Let’s take a look at the example, from start of the development to the production release:
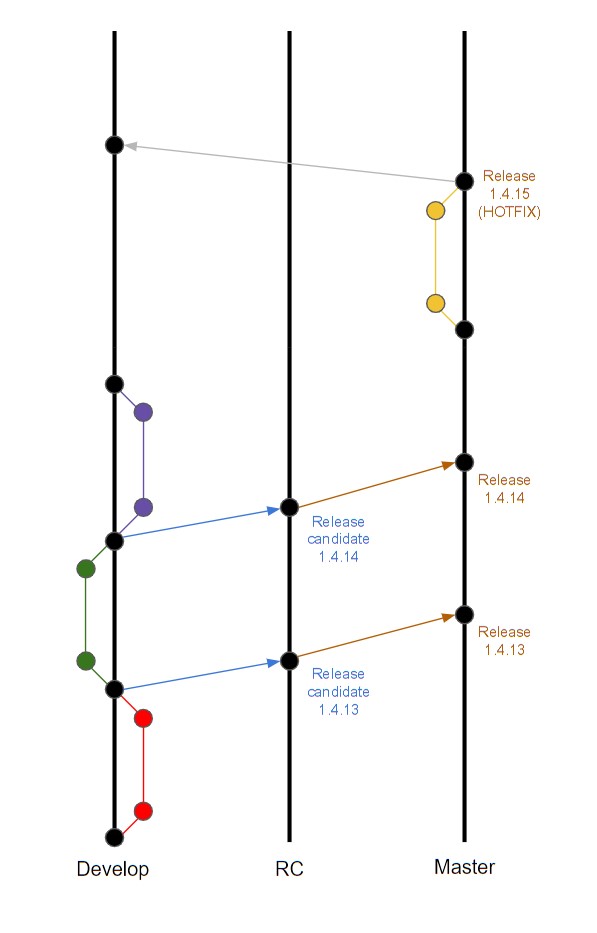
- Developer starts working on a feature or bugfix and creates a branch on develop branch
- After finishing coding, developer rebases his branch on top of develop branch to catch up with changes made in between either by us or the other company (as long as there are no conflicts this can be skipped, however, when they do appear it’s easier for a person who created the code to solve them than the person who will be preparing a release).
- Developer commits his code and creates a pull/merge request
- Another team member does code review, eventually merging the feature branch into develop
- The person merging the branch pushes develop branch onto our client’s repository so that the other company keeps up to date
- Develop branch is merged into RC branch and a release candidate version is created
- After testing on pre-production environment, the very same package as release candidate is put on production as a release – RC branch is then merged into Master branch
The solution we came up with seems a lot more flexible and easy to use – the time to create a release was reduced significantly as we used simple git merges to create them. As a result there are fewer conflicts to handle as both software providers are working on more or less the same branch. So far it has been working flawlessly for us.