Faceted search is popular technique used in online retailers. Users can search for product using multiple filters, called facets, narrowing result list in each step. In addition to that, filters can show number of products matching each facets for selected conditions. Facets without results can be hidden.
Most facets use product information, such as: type, brand, price, color, weight, etc. There can also be product type specific facets. For example you can search for laptops by processor, RAM, disk size, screen size.
Faceted search is also useful in business applications. Besides simple attributes, we can create facets based on complex business rules, such as: calculated customer segment, exceeded payment deadline, customers qualified for vindication.
In this blog post I show how to create simple faceted search application and how to handle complex business conditions. Examples use MyBatis persistence framework, but they are easily translated to other SQL query frameworks.
SQL faceted search
Let’s create simple faceted search for online shop. Consider this simple database schema:
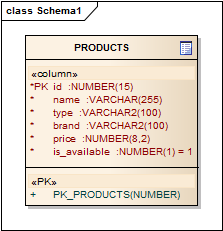
In this simple example, we can extract several facets:
- type – product type filter can be presented as selectable list of types with number of products for each type
- brand – brand can be presented as select box with number of products for each brand
- price – vertical range widget; minimum and maximum prices should reflect actual values from PRODUCTS table
- is_available – single selectable facet with number of products
- not_available – single selectable facet with number of products
Then we create criteria class for our facets.
|
1
2
3
4
5
6
7
8
9
10
11
|
public class ProductCriteria {
private Collection<String> types;
private Collection<String> brands;
private BigDecimal minPrice;
private BigDecimal maxPrice;
private boolean available;
private boolean notAvailable;
...
}
|
We can select multiple types, so criteria object takes collection of types. For range conditions I’m using pair of field: minPrice and maxPrice.
Next step is to create MyBatis mapper file to execute query for list of products. I’m using separate productCriteria block, so it can be later reused.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
<sql id=“productCriteria”>
<if test=“criteria.types != null && !criteria.types.isEmpty()”>
and type in <foreach collection=“criteria.types” open=“(“ close=“)” separator=“, “ item=“item”>#{item}</foreach>
</if>
<if test=“criteria.brands != null && !criteria.brands.isEmpty()”>
and type in <foreach collection=“criteria.brands” open=“(“ close=“)” separator=“, “ item=“item”>#{item}</foreach>
</if>
<if test=“criteria.minPrice != null”>
and price >= #{criteria.minPrice}
</if>
<if test=“criteria.maxPrice != null”>
and price <= #{criteria.maxPrice}
</if>
<if test=“criteria.available”>
and is_available = 1
</if>
<if test=“criteria.notAvailable”>
and is_available = 0
</if>
</sql>
<select id=“searchProducts” parameterType=“map” resultType=“Product”>
select id, name, type, brand, price, is_available
from products
<trim prefix=“WHERE” prefixOverrides=“and |or “>
<include refid=“productCriteria”/>
</trim>
</select>
|
In addition to product list, we must also calculate values for our facets.
Unfortunately several select queries are needed. Each query uses conditions from ProductCriteria with one condition cleared. For example typesCount would have criteria.types == null.
Type facet uses group by statement to select product counts for each type:
|
1
2
3
4
5
6
7
8
|
<select id=“typesCount” parameterType=“map” resultType=“GroupCount”>
select type, count(*)
from products
<trim prefix=“WHERE” prefixOverrides=“and |or “>
<include refid=“productCriteria”/>
</trim>
group by type
</select>
|
Brand facet works analogously to type:
|
1
2
3
4
5
6
7
8
|
<select id=“brandsCount” parameterType=“map” resultType=“GroupCount”>
select brand, count(*)
from products
<trim prefix=“WHERE” prefixOverrides=“and |or “>
<include refid=“productCriteria”/>
</trim>
group by brand
</select>
|
Price uses min and max functions:
|
1
2
3
4
5
6
7
|
<select id=“priceMinMax” parameterType=“map” resultType=“MinMax”>
select min(price), max(price)
from products
<trim prefix=“WHERE” prefixOverrides=“and |or “>
<include refid=“productCriteria”/>
</trim>
</select>
|
Is_available and not_available can also use group by:
|
1
2
3
4
5
6
7
8
|
<select id=“availableCount” parameterType=“map” resultType=“GroupCount”>
select is_available, count(*)
from products
<trim prefix=“WHERE” prefixOverrides=“and |or “>
<include refid=“productCriteria”/>
</trim>
group by is_available
</select>`
|
UI uses returned information to properly display each facet.
Complex facets
In business applications facets are not always that simple. Let’s take a look at some more complicated example:
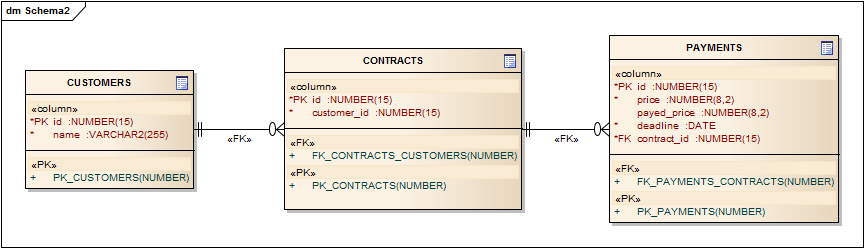
Customer can have multiple contracts. For each contract there can be multiple payments and each payment has several fields:
- price – how much customer should pay us
- payed_price – how much customer has payed
- deadline – due date for payment
There could be many search facets for customers, but let’s focus on more interesting ones in order of complexity:
- customers with pending payments – tells us which customers have payments that weren’t payed
- customers with outstanding payments – tells us which customers have pending payments after deadline
- customers for vindication – tells us which customers have outstanding payments with cumulative value of more then 500 and exceeded deadline of 2 months
As shown in previous example, we need 2 things for facet implementation: SQL condition which narrows list of customers and customer count for facet. The second one is easy if we can implement the first one, so let’s focus on SQL condition. For customers with pending payments we need to select all customers that have contracts that have payments with payed_price < price. This could be written in following sql query:
|
1
2
3
4
5
6
7
8
|
selectid,name
from customers cust
where exists(
select * from contracts c
join payments p on (p.contract_id = c.id)
where p.price > p.payed_price
and cust.id = c.customer_id
)
|
Instead of exists we could use in statement, but the problem remains that we have to deal with sub-query. For more complex facets there could be many more joins for one facet condition. And all selected facets conditions goes to where query. So basically query complexity can grow really fast.
Data denormalization
Fortunately there is a way to deal with any complex facets without sacrificing query performance. Idea is to create additional table with data for complex facets. This additional data already exists in the database in many different tables, so we are duplicating information to have easier access. The main problem of data denormalization is keeping all duplicates in sync. But sometimes it is the only way to have satisfactory performance of select queries.
Here’s example of additional table, which keeps data for our complex facets:
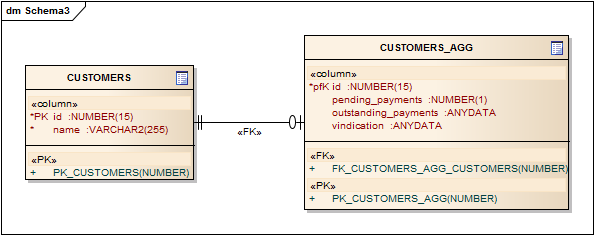
Table CUSTOMERS_AGG (aggregates) contains aggregated data from other tables for our facets. Pending_payments facet is just boolean value. I will deal with other facets later, so column types are left unspecified.
With this new table our select query is simpler:
|
1
2
3
4
|
selectid,name
from customers cust
join customers_agg ca on (cust.id = ca.id)
where pending_payments = 1
|
Complexity does not change when we add conditions for other facets. We would still have only one join, we only add simple conditions to where statement.
As I said earlier, we should keep our duplicated data in sync, so we need additional query to select current data for our aggregate table. To get value for pending_payments facet of one customer, we can use following query:
|
1
2
3
4
|
select count(*) from contracts c
join payments p on (p.contract_id = c.id)
where p.price > p.payed_price
and cust.id = v_customer_id
|
For v_customer_id, when count(*) is greater then 0, we can set CUSTOMERS_AGG value to 1.
How and when to update the aggregates table?
Aggregate table should be updated when there is any change in source data for our facet. In our case we should update aggregates in following situations:
- insert, delete on CONTRACTS table
- insert, update, delete on PAYMENTS table
We have several ways to update aggregates table.
Database triggers
Database triggers are a very powerful way for updating aggregate data. When there is a change in CONTRACTS or PAYMENTS table, customer aggregate procedure is called. In this way, data is always in sync. It doesn’t matter if update is executed from database or application. Downside is slower updates, because of aggregate procedure complexity. Sometimes triggers generate multiple updates for the same customer if multiple rows are updated in the same transaction.
Synchronous application updates
Synchronous application updates can be done at the end of transaction. In this way we can collect all of the changes in whole transaction and recalculate aggregates for each customer only once. Unfortunately updates outside of application do not execute aggregate procedure.
Asynchronous application updates
When aggregate update is very slow we can create asynchronous application updates. One way to do it is to mark rows to be updated from database triggers. Later application asynchronously updates invalid aggregate rows. Unfortunately there is some time between source data update and aggregate update. In this time we are showing old data. The upside is that aggregate procedure does not impact other transactions. When we use database triggers to mark obsolete rows, updates from outside of the application also eventually cause aggregate updates.
Time-dependent conditions
Other two facets outstanding_payments and vindication can be put into temporal facet category. The problem with temporal facets is that it is more difficult to create aggregates for them.
Let’s say that customer does not have any outstanding payments. This information can be false in the next day. Recalculating facets every day is rather wasteful.
Fortunately, instead of storing information about current facet state, we can calculate date from which this facet will be active. So in our CUSTOMERS_AGG table, temporal facets will have column type of date:
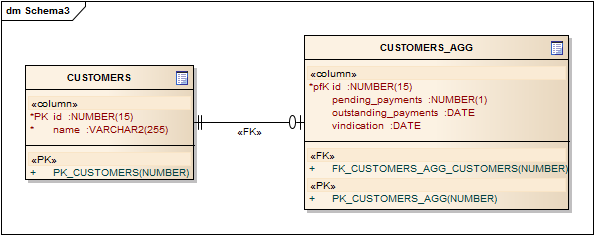
Now we can check current facet value based on current date:
|
1
2
3
4
|
selectid,name
from customers cust
join customers_agg ca on (cust.id = ca.id)
where outstanding_payments <= sysdate
|
Updating temporal facet aggregate is a little more difficult. We must find the minimum date that this facet is active:
|
1
2
3
4
|
select min(p.deadline) from contracts c
join payments p on (p.contract_id = c.id)
where p.price > p.payed_price
and cust.id = v_customer_id
|
And what about vindication facet? We should find minimum date that is later then 2 months then deadline date of payments with sum of not payed value exceeding 500. I leave this query as an exercise to the reader.
Summary
Faceted search is a powerful way to filter data by categories interesting to users. Besides basic conditions used in online retailer applications, we can create facets based on complex business rules. In this article I have shown how to create faceted search in SQL (relational) database using MyBatis persistence framework. I’ve also shown how to optimize faceted search performance by creating data aggregates and how to implement temporal facets with values changing in time.