
[Uwaga] Ten artykuł został pierwotnie przygotowany w języku angielskim i został przetłumaczony na język polski.
W ostatnich latach architektura mikroserwisowa wysunęła się na prowadzenie w większości rozwiązań programistycznych i w wielu przypadkach jest najczęściej wybieraną architekturą, od której zaczynamy rozwój projektu. Warto jednak zadać sobie pytanie, czy zawsze jest to optymalny wybór. Co więcej, jeśli wybierasz mikroserwisy jako zestaw zasad, których chcesz się trzymać, czy na pewno jesteś świadomy konsekwencji tego wyboru?
Moim zdaniem mikroserwisy oferują dwie główne korzyści:
Niestety, w większości przypadków, gdy wybierana jest architektura mikroserwisowa, zespół kończy z tak zwanym „rozproszonym monolitem”. Jeśli na początku pracy polegasz na silnych zależnościach między usługami lub bazami danych, a ostatecznie wdrażasz 90% usług jednocześnie, powinieneś przyznać, że łatwiej byłoby to zrobić jako pojedynczą jednostkę wdrożeniową. Zmniejszyłoby to wysiłek związany z implementacją, automatyzacją i utrzymaniem mikroserwisów, pozwalając skupić się intensywnie na problemach biznesowych.
Krótko mówiąc, musisz pamiętać, że styl architektury mikroserwisowej nie jest prosty i niesie ze sobą dużą złożoność technologiczną. Nie strzelaj z armaty do wróbla! Uruchamianie klastra Kubernetes dla jednej aplikacji lub usługi nie ma sensu, ponieważ koszty infrastruktury i wszystkich konfiguracji przewyższą koszty rozwoju. Istnieją inne „prostsze” rozwiązania chmurowe, np. AWS ECS, AWS Fargate, AWS Beanstalk, a nawet EC2 + prosty Load Balancing (inni dostawcy chmury mają podobne rozwiązania).
Poniżej przedstawiam kilka heurystyk, które mogą pomóc w podjęciu decyzji, którą architekturę wybrać.
| Czego potrzebujesz? | Mikroserwisy | Monolit |
| Niezależne jednostki wdrożeniowe | Tak, ale tylko przy dobrej separacji logicznej | Tak |
| Prosta i szybka do zbudowania infrastruktura | Nie | Tak |
| Dynamiczne skalowanie | Tak | Nie |
| Autonomia logiki biznesowej | Tak – jeśli poprawnie podzielimy domeny | Tak – jeśli poprawnie podzielimy domeny |
| Dynamiczne skalowanie poziome konkretnych komponentów | Tak | Nie |
| Autonomia technologiczna | Tak | Nie |
| Niezależne zespoły deweloperskie | Tak | Nie |
| Szybki start projektu (kick-off) | Nie | Tak |
Termin „monolit” jest często używany jako synonim przestarzałych aplikacji (legacy). Poprzez odpowiednie zaprojektowanie aplikacji monolitycznej (właściwy dobór architektury wewnętrznej), można zdecydowanie skrócić start projektu, nie wykluczając ewentualnych zmian w przyszłości. Wciąż możesz przejść na mikroserwisy. W tym miejscu przydaje się podejście modularnego monolitu – a w szczególności podejście „monolith first”. Jeśli nie wiesz, jaki zakres będzie miał projekt w nadchodzących latach i nie wiesz, jak szybko będzie rósł, rozpoczęcie od dobrze ustrukturyzowanej aplikacji monolitycznej może być dobrym pomysłem.
Co oferuje Modularny Monolit?
Oczywiście istnieje wiele innych czynników, które mogą wpłynąć na wybór architektury systemu. Biorąc jednak pod uwagę te, o których wspomniałem powyżej, lepiej nie zaczynać projektu z założeniem, że będzie on oparty na mikroserwisach. Jeśli nie masz pewności, jak cały system będzie wyglądał za 2–3 lata, zazwyczaj lepiej wybrać architekturę modularną. Zaczynasz od dobrze zaplanowanego monolitu, a następnie – w razie potrzeby – stopniowo przekształcasz go w monolit modularny.
Warto również pamiętać o dostępnych, prostych rozwiązaniach, które w ogóle nie wymagają architektury systemowej – takich jak rozwiązania serverless, AWS Lambda itp. Mogą one dobrze sprawdzić się w przypadku stosunkowo prostych, niezbyt skomplikowanych problemów.
W Pretius skupiamy się na projektach długoterminowych i długim cyklu życia (utrzymanie i rozwój), dlatego trwałość i rozszerzalność są dla nas zazwyczaj bardzo ważne. Wybór architektury systemu często sprowadza się do metody wdrażania i w konsekwencji infrastruktury, na której system jest uruchamiany.
Jednak z perspektywy programistów, infrastruktura i wdrażanie aplikacji powoli stają się tematami drugorzędnymi – istnieją specjaliści na dedykowanych stanowiskach (np. inżynierowie DevOps), którzy podejmują ważne decyzje i dbają o te problemy. My po prostu chcemy, aby system był dobrze utrzymany, działał bez problemów i nie generował długu technologicznego/biznesowego. Aby tak się stało, musimy skupić się na kodzie aplikacji.
Gdy już zdecydujesz się na architekturę systemu, nadszedł czas, aby skupić się na architekturze poszczególnych aplikacji. Niestety, większość projektów opiera się na warstwach (architektura n-warstwowa). W przypadku złożonych projektów efekt końcowy jest zazwyczaj taki sam → Wielka Kula Błota (Big Ball of Mud – przykład na poniższym zrzucie ekranu).
Źródło obrazu: Medium.
Nie jest to zły wybór dla prostych aplikacji typu CRUD lub kilku/kilkunastu usług, ale kiedy próbujesz ująć złożoną logikę w taki schemat, szybko okazuje się, że sieć zależności zaczyna powodować poważne problemy. Dobrym pomysłem jest posiadanie świadomości istnienia różnych stylów i poznanie ich bardziej szczegółowo.
Style architektury aplikacji:
Warto dodać, że style te można mieszać i dopasowywać. Nie trzeba fiksować się na konkretnym rozwiązaniu, ale po prostu wybierać narzędzia, które ułatwią życie. Dotyczy to również architektury systemu. Na przykład, jeśli okaże się, że w systemie mikroserwisowym musisz stworzyć większą (np. monolityczną) aplikację, nie powinieneś na siłę próbować dopasować jej do architektury mikroserwisowej. Zamiast tego wybierz architekturę wewnętrzną, podziel ją na oddzielne moduły / domeny biznesowe, a tym samym zmniejsz koszty pracy DevOps/konfiguracyjnej.
Przy wyborze architektury można również spróbować znaleźć kompromis. Mówiąc szczerze, coś takiego jak „złoty środek” nie istnieje – ale można się do niego zbliżyć. Przed wyborem konkretnego stylu architektonicznego warto zebrać kilka metryk dotyczących projektowanego systemu. Im więcej informacji będziesz mieć do dyspozycji, tym bardziej wiarygodna będzie Twoja decyzja.
Płytki system łatwo rozpoznać, ponieważ jego interfejs użytkownika w pełni odzwierciedla struktury w bazie danych i w kodzie aplikacji (→ CRUD). Nie ma tu złożonych integracji ani skomplikowanych algorytmów. Z kolei główną cechą systemów głębokich jest to, że od momentu interakcji użytkownika do efektu końcowego odbywa się szereg niewidocznych dla niego operacji – mniej lub bardziej złożonych. Wyszukiwarka Google czy system do procesowania wniosków leasingowych to dobre przykłady systemów głębokich.
Trudno mówić o zasadach wyboru architektury – lepszym terminem wydają się być „heurystyki”, które mogą skierować nas ku konkretnemu wyborowi.
Dla płytkich, nieskomplikowanych systemów tworzonych przez mały zespół, można wybrać prostsze architektury, np. aplikacje warstwowe i monolityczne. Kiedy jednak od początku wiadomo, że złożoność będzie wysoka, projekt będzie trwał latami i wymagał pracy dużych lub wielu zespołów, kluczowy będzie odpowiedni podział aplikacji i dążenie do separacji odpowiedzialności. Można to osiągnąć zarówno w architekturze mikroserwisowej, jak i we wspomnianym wcześniej modularnym monolicie. Istnieją również aspekty techniczne, które należy wziąć pod uwagę przy wyborze konkretnego stylu.
Stary dobry brainstorming – lub jego nowsza forma, event storming – to jedne z narzędzi, których można użyć do stworzenia wstępnego zarysu modułów/usług. Celem takich ćwiczeń jest uformowanie wstępnego zarysu domen – lub ich braku – w danym biznesie. Następnie powinieneś być w stanie oszacować wielkość systemu. Poniżej znajduje się przykład pierwszego zarysu domen/modułów po analizie diagramu obiektów (oznaczonych kolorami).
Model bazy danych jest często zaniedbywany, gdy zespoły wybierają architekturę dla swojego projektu. Dzielą usługi na mniejsze lub większe, uruchamiają je w chmurze i budują całą otoczkę związaną z produkcją mikroserwisów, ale nadal projektują bazę danych tak, jakby była częścią dużej splątanej aplikacji monolitycznej. To nie jest dobre podejście – jeśli zdecydujesz się na mikroserwisy, baza danych musi odzwierciedlać logiczny podział, który zastosowałeś w warstwie aplikacji. Wiązanie usług na poziomie bazy danych jest jednym z głównych problemów we współczesnych architekturach mikroserwisowych, prowadzącym do Wielkiej Kuli Błota (pokazanej na jednym z powyższych obrazków) i późniejszych trudności w utrzymaniu.
Jeśli nie możesz pozwolić sobie na oddzielne bazy danych dla każdej usługi, podział na schematy wystarczy na początek. Schematy sprawdzą się również w modularnych monolitach. Jeśli chodzi o warstwę danych w mikroserwisach, powinieneś korzystać z możliwości, jakie one oferują – mianowicie powinieneś dopasować typ bazy danych do modelu biznesowego, a nie odwrotnie. Przy odrobinie wysiłku wszystko można spłaszczyć do modelu relacyjnego, ale swoboda architektury mikroserwisowej pozwala nam tego nie robić.
Powszechnym sposobem projektowania bazy danych jest tworzenie struktur w oparciu o dane, które musimy zebrać (np. na podstawie informacji otrzymanych od klienta). Dobrym ćwiczeniem jest próba zaprojektowania modelu danych w oparciu o funkcjonalności, które aplikacja musi spełniać. Wynikowy model jest zazwyczaj znacznie „cieńszy” niż pierwotne założenia i okazuje się w pełni wystarczający.
W wielu projektach Pretius wykorzystywaliśmy narzędzie MyBatis do komunikacji z bazą danych. Pozwala to zachować 100% kontroli nad tym, co dzieje się w bazie, ale ma też często niezauważalny efekt uboczny – Anemiczny Model Domenowy (Anemic Domain Model). Pisanie złożonych instrukcji SQL często zniechęca programistów do tworzenia złożonych relacji wewnątrz modelu po stronie kodu aplikacji. Inną konsekwencją tego jest odejście od paradygmatu programowania obiektowego (brak enkapsulacji, logika w serwisach).
Prawie każdy deweloper może nauczyć się i obsługiwać rozwiązania takie jak MyBatis (oraz inne alternatywy, jak np. Hibernate), więc są one jak najbardziej warte rozważenia. Są to jednak tylko narzędzia i nie zwolnią Cię z obowiązku myślenia o skutkach ubocznych i konsekwencjach Twoich decyzji.
Jeśli chodzi o komunikację w architekturze mikroserwisów, preferowane jest podejście Asynchronous By Default (domyślnie asynchroniczne), ale z pewnością nie da się w pełni uniknąć korzystania z REST lub innej synchronicznej formy komunikacji (gRPC, SOAP itp.). Technologia to jedno, ale są ważniejsze pytania, które powinieneś sobie zadać. Dlaczego się komunikujesz? Czy te wywołania REST są konieczne? Czy logika została odpowiednio odseparowana do innego modułu/usługi?
Często mikroserwisy stają się siecią wzajemnych połączeń – mówiąc obrazowo, wszystko rozmawia ze wszystkim. Jest to zazwyczaj konsekwencja złego podziału/dekompozycji na domeny i jest już poważną wskazówką, że zbudowałeś rozproszony monolit, a nie mikroserwisy.
Problem ten nie ogranicza się tylko do komunikacji na poziomie aplikacji/usług. Musisz pamiętać, że te same zasady obowiązują na poziomie kodu – Usług, Fasad, Klas czy pakietów. W obu przypadkach warto zapoznać się z koncepcją Low coupling, High cohesion (niska zależność, wysoka spójność). Komunikacja w kontekście technicznym zazwyczaj nie jest problemem, ale transakcje rozproszone, sagi, kompensacje i fallbacki (które są czasem konsekwencją architektury rozproszonej) już tak. To jest obszar, na którym należy się skupić.
Kilka wzorców komunikacji w systemach rozproszonych, które powinieneś znać:
Struktura projektu powinna być ściśle powiązana z wybraną architekturą systemu i aplikacji. Oprócz komponentów, które powinny być wspólne, na przykład w ramach wymagań DevOps (dotyczy architektury systemu), wewnętrzna struktura samej aplikacji będzie determinowana przez wybraną architekturę aplikacji.
Poza architekturami, w celu zachowania lepszej czytelności kodu w kontekście biznesowym, można zastosować podejście „package by feature” (pakietowanie według funkcjonalności). Pomysł polega na umieszczaniu kodu zgrupowanego w pakietach dla konkretnej domeny/funkcjonalności/obszaru, a nie – jak to zazwyczaj bywa – podzielonego na pakiety techniczne, tj. kontrolery, serwisy, mappery itp.
Szczerze mówiąc, nie zalecam tworzenia szkieletów aplikacji, które można ponownie wykorzystać wewnątrz firmy. Istnieją darmowe narzędzia, takie jak Spring Initializr, za pomocą których można stworzyć taki zarys projektu w kilka sekund, więc lepiej rozważyć każdy przypadek niezależnie. Kopiowanie czegoś z innych projektów może prowadzić do długu technologicznego od samego początku – ponieważ nawet nie sprawdzasz, czy dostępna jest nowsza/lepsza opcja.
Jednak po wybraniu struktury dobrze jest się jej trzymać przez cały projekt, aby zachować spójność i przejrzystość.
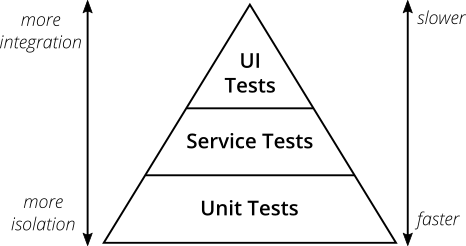
Źródło obrazu: Martin Fowler.
Piramida testów (zrzut ekranu powyżej) nie ma w pełni zastosowania w przypadku architektur rozproszonych. Oprócz testowania w ramach jednej jednostki wdrożeniowej, należy zapewnić testowanie na styku tych jednostek, ponieważ trzeba założyć, że taka komunikacja będzie obecna. Tak więc, oprócz standardowych testów integracyjnych między modułami/usługami, można również stosować Testy Kontraktowe jako część testowania API między modułami (dodatkowe informacje na ten temat dostępne są tutaj).
Również piramida testów będzie wyglądać inaczej w zależności od modułu. W przypadku płytkich modułów (powiedzmy CRUD) nie ma sensu przeprowadzać wszystkich rodzajów testów, ponieważ w końcu po prostu będziesz sprawdzać to samo kilka razy – główną różnicą będzie sposób wywoływania testów. Dla głębokich, złożonych modułów, gdzie logika biznesowa może być skomplikowana i rozbudowana, testy jednostkowe są kluczowe. Integracja modułów będzie z kolei wymagała więcej testów integracyjnych niż jednostkowych. Testcontainers to świetne narzędzie do testów integracyjnych, a jeśli chcesz wiedzieć, jak skutecznie go używać razem z Liquibase, sprawdź mój poprzedni artykuł: Testcontainers + Liquibase: Ułatw sobie testy integracyjne.
Architektura rozproszona (mikroserwisowa) będzie wymagała odpowiedniej metody zbierania logów aplikacji. Usługi mogą istnieć w środowisku produkcyjnym w wielu instancjach i działać na zupełnie różnych maszynach fizycznych. W rezultacie logowanie się na serwer i ręczne przeszukiwanie logów w plikach tekstowych staje się czasochłonne, a czasem może być wręcz niemożliwe. Rozwiązaniem tego problemu jest wdrożenie scentralizowanego magazynu logów, takiego jak dokumentowa baza danych, w której logi ze wszystkich aplikacji wchodzących w skład systemu będą gromadzone za pomocą narzędzi pomocniczych. Oprócz scentralizowanego magazynu logów, zainteresować Cię mogą narzędzia do replikacji danych, które pomagają zachować spójność danych (i ich dostępność w systemach rozproszonych).
Standardem rynkowym dla realizacji opisanego powyżej wymagania jest obecnie zestaw trzech narzędzi (ELK stack):
Konkretna baza danych i narzędzie do wizualizacji logów będą zależeć od projektu. Dwie najbardziej prawdopodobne opcje wymieniono w powyższych punktach.
Poniższy diagram przedstawia uproszczony przepływ logów ze stron internetowych/aplikacji do silnika bazy danych.
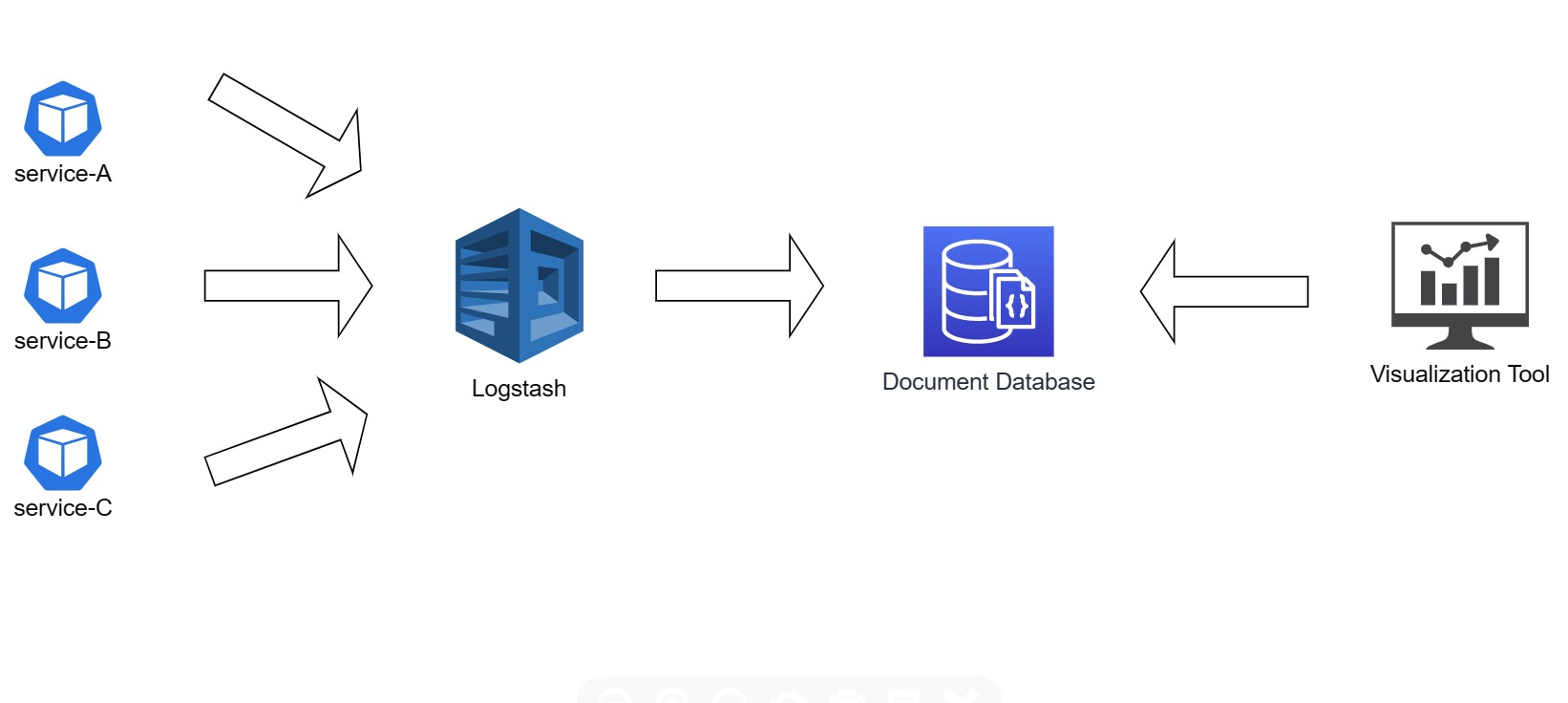 Z Logstash można zintegrować się poprzez REST API, co pozwala na korzystanie z niego niezależnie od języka programowania użytego w aplikacji. Jeśli nie jest możliwe bezpośrednie zintegrowanie aplikacji z Logstashem, istnieje możliwość skorzystania z narzędzia Beats odpowiedzialnego za pobieranie logów z plików tekstowych, ich parsowanie, a następnie przesyłanie do narzędzia Logstash.
Z Logstash można zintegrować się poprzez REST API, co pozwala na korzystanie z niego niezależnie od języka programowania użytego w aplikacji. Jeśli nie jest możliwe bezpośrednie zintegrowanie aplikacji z Logstashem, istnieje możliwość skorzystania z narzędzia Beats odpowiedzialnego za pobieranie logów z plików tekstowych, ich parsowanie, a następnie przesyłanie do narzędzia Logstash.
Jedną z konsekwencji stosowania architektury mikroserwisowej jest dość wysoka złożoność technologiczna. Aplikacje są rozproszone na wielu maszynach fizycznych, system może składać się z dziesiątek aplikacji i różnych komponentów wspierających. Dlatego bardzo ważnym aspektem w utrzymaniu systemów rozproszonych jest ich ciągły monitoring, czyli sprawdzanie kondycji systemu. Dzięki temu, gdy zauważymy awarię lub błąd systemu, jesteśmy w stanie maksymalnie skrócić czas reakcji.
Paradoksalnie, aby zapanować nad rosnącą złożonością architektury, musimy wdrożyć jeszcze więcej narzędzi, które nam w tym pomogą.
Te same narzędzia są wykorzystywane dla wszystkich rodzajów metryk i alertów i mogą być zintegrowane z dowolnego języka programowania.
Aplikacje są często budowane w architekturze warstwowej. Rozumiem przez to techniczny podział na pakiety typu: controllers, services, model itp. W kodzie model jest zazwyczaj prostym mapowaniem kolumny bazy danych na pola w POJO (brak relacji, tylko referencja przez ID). Logika biznesowa natomiast jest w pełni zaimplementowana w pakietach „services”. Taki podział nie jest błędny, ale może działać nieco gorzej w dużych projektach.
Problemy architektury n-warstwowej:
Oto kilka różnych podejść, które można zastosować zamiast warstw:
Podział logiczny na poziomie architektury systemu to nie koniec – często zapominamy o separacji w samych aplikacjach. Rzadko kiedy jeden serwis równa się jednej funkcjonalności. Należy również wydzielać domeny i subdomeny (może być ich wiele), które razem tworzą konkretną usługę lub aplikację. Zasady komunikacji między nimi powinny być podobne do tych stosowanych na poziomie architektury systemu: ustalone API, komunikacja przez interfejsy, enkapsulacja itp.
Oferta jest zazwyczaj przygotowywana przez inną osobę (lub zespół) niż ta, która zajmuje się wdrożeniem. Z tego powodu warto zaangażować stronę trzecią do szybkiej walidacji propozycji architektury na etapie ofertowania. Cross-check na pewno się opłaci, niezależnie od Twojego doświadczenia.
Przede wszystkim warto sprawdzić, czy projekt architektoniczny nie jest zbyt rozbudowany (overkill) w stosunku do potrzeb klienta. Jeśli zaczniesz od mikroserwisów jako pierwszego pomysłu, łatwo możesz wybrać coś o wiele za skomplikowanego. Na przykład, musisz zaprojektować jedną, raczej małą aplikację (jedna domena, kilka funkcjonalności), ale dopasowujesz do niej architekturę mikroserwisową uruchomioną na Kubernetesie, ze stosem ELK, monitoringiem itp. Czy naprawdę chcesz robić coś takiego przy jednej aplikacji, jeśli nie wiesz, jakie są plany na przyszły rozwój projektu?
Możesz również napotkać sytuację odwrotną – Twoja propozycja będzie niewystarczająca dla potrzeb klienta. Zdarzy się to prawdopodobnie rzadziej, ponieważ w ofertach wszystko jest zazwyczaj planowane z solidnym marginesem – ale jeśli tak się stanie, będziesz musiał znaleźć dobre argumenty na poparcie swojego podejścia. Dobrym pomysłem jest również ograniczenie się do architektury systemu na etapie oferty i pozostawienie architektury aplikacji na etap wdrożenia.
Co jeśli zrezygnujemy z mikroserwisów, a rok później okaże się, że są one jednak potrzebne? Jeśli zbudujesz aplikację monolityczną z odpowiednią strukturą i podziałem na domeny i subdomeny, zmiana architektury nie powinna wymagać rewolucji – będzie to po prostu naturalne przejście, które można przeprowadzić bez nadmiernego wysiłku.
Decyzje w tych obszarach będą ściśle zależeć od wymagań klienta – trudno tu zdefiniować sztywne zasady postępowania. Niektóre elementy, na które należy zwrócić uwagę:
Niezależnie od wybranego typu architektury systemu, aplikacja powinna być w stanie obsłużyć ruch określony przez klienta i być gotowa na ewentualne „nieoczekiwane” skoki. Trzeba uważać, aby nie wpaść w pułap „przedwczesnej optymalizacji”, ale jeśli masz już konkretne wymagania, musisz dostosować do nich rozwiązanie od samego początku.
Kilka rzeczy do rozważenia:
Najlepszy scenariusz to taki, w którym klient jest w stanie zdefiniować konkretne metryki dotyczące wydajności systemu, takie jak liczba logowań na godzinę, X wizyt na konkretnej stronie w czasie X, 10 przetworzonych wniosków leasingowych, 100 wyszukiwań ofert na minutę itp. Na podstawie takich metryk można przygotować odpowiednie testy i właściwie dostosować system.
Należy tutaj wziąć pod uwagę dwa aspekty:
Jak widać, system modularny może służyć jako dobra alternatywa dla mikroserwisów lub tradycyjnej architektury monolitycznej. Każde z tych podejść ma swoje zalety i ograniczenia. Które powinieneś rozważyć w swoim projekcie? Będzie to zależeć całkowicie od charakteru systemu, nad którym będziesz pracować. Aby nieco ułatwić tę decyzję, zapoznaj się z poniższymi tabelami podsumowującymi główne wady i zalety.
| Mikroserwisy | |
| Zalety | Wady |
|
|
| Monolit | |
| Zalety | Wady |
|
|
| Modularny Monolit | |
| Zalety | Wady |
|
|
Przeanalizuj swoje potrzeby, porozmawiaj z zaufanymi członkami zespołu i wybierz architekturę, która najlepiej posłuży projektowi – nie tylko dzisiaj, ale jutro, a nawet za wiele lat.
W Pretius mamy ponad 15 lat doświadczenia w budowaniu skalowalnych rozwiązań programistycznych dla dużych przedsiębiorstw. Jeśli więc chcesz skonsultować swoje pomysły, napisz do nas na adres hello@pretius.com lub skorzystaj z poniższego formularza kontaktowego. Wstępne konsultacje są zawsze bezpłatne.
Dodatkowo, jeśli potrzebujesz więcej informacji na temat wzorców projektowych i architektonicznych, oto kilka źródeł, które warto przeczytać:
Oto odpowiedzi na popularne pytania dotyczące modularnej architektury oprogramowania.
Architektura mikroserwisowa oferuje liczne korzyści, takie jak natywne wsparcie dla chmury (cloud native), fizyczna separacja modułów, skalowanie poziome, luźne powiązanie, autonomia wdrożeniowa i technologiczna, płynne CI oraz możliwość współpracy wielu zespołów nad niezależnymi komponentami.
Modularny monolit łączy niektóre aspekty monolitu i architektury mikroserwisowej. Pozwala na zachowanie prostoty wdrożenia przy jednoczesnym logicznym podziale na autonomiczne domeny biznesowe.




