
[Uwaga] Ten artykuł został pierwotnie przygotowany w języku angielskim i został przetłumaczony na język polski.
Odkąd platforma Java przeszła na sześciomiesięczny cykl wydawniczy, przestaliśmy zadawać sobie odwieczne pytania typu „Czy Java umrze w tym roku?” lub „Czy warto migrować do nowej wersji?”. Mimo 28 lat od pierwszego wydania, Java wciąż kwitnie i pozostaje popularnym wyborem jako główny język programowania dla wielu nowych projektów.
Java 17 była znaczącym kamieniem milowym, ale teraz to Java 21 zajęła jej miejsce jako kolejna wersja o długim wsparciu (LTS). Dla Java developerów kluczowe jest bycie na bieżąco ze zmianami i nowymi funkcjonalnościami, które przynosi ta wersja. Zainspirowany przez mojego kolegę Darka, który szczegółowo opisał funkcje Javy 17 w swoim artykule, postanowiłem omówić JDK 21 w podobny sposób (przeanalizowałem również funkcje Javy 23 w kolejnym tekście, więc zachęcam do lektury).
JDK 21 składa się łącznie z 15 JEP-ów (JDK Enhancement Proposals). Pełną listę możesz sprawdzić na oficjalnej stronie Javy. W tym artykule wyróżnię kilka JEP-ów z Javy 21, które moim zdaniem zasługują na szczególną uwagę. Są to:
Bez zbędnej zwłoki, zagłębmy się w kod i sprawdźmy te nowości.
Funkcja String Templates jest wciąż w fazie preview. Aby jej użyć, musisz dodać flagę –enable-preview do argumentów kompilatora. Zdecydowałem się jednak o niej wspomnieć mimo statusu preview. Dlaczego? Ponieważ irytuje mnie za każdym razem, gdy muszę pisać komunikat logowania lub zapytanie SQL zawierające wiele argumentów albo rozszyfrowywać, który placeholder zostanie zastąpiony danym argumentem. String Templates obiecują pomóc mi (i Tobie) właśnie w tym obszarze.
Jak mówi dokumentacja JEP, celem String Templates jest „uproszczenie pisania programów w Javie poprzez ułatwienie wyrażania ciągów znaków (strings), które zawierają wartości obliczane w czasie wykonywania (run time)”.
Sprawdźmy, czy naprawdę jest to prostsze.
„Stary sposób” polegał na użyciu metody formatted() na obiekcie String:
var msg = "Log message param1: %s, pram2: %s".formatted(p1, p2);
Teraz, dzięki StringTemplate.Processor (STR), wygląda to następująco:
var interpolated = STR."Log message param1: {p1}, param2: {p2}";
Przy krótkim tekście, takim jak powyższy, zysk może nie być aż tak widoczny – ale uwierz mi, gdy w grę wchodzą duże bloki tekstu (JSONy, zapytania SQL), nazwane parametry bardzo Ci pomogą.
Java 21 wprowadziła nową hierarchię kolekcji (Java Collection Hierarchy). Spójrz na poniższy diagram i porównaj go z tym, czego prawdopodobnie uczyłeś się na zajęciach z programowania. Zauważysz, że dodano trzy nowe struktury (zaznaczone kolorem zielonym).
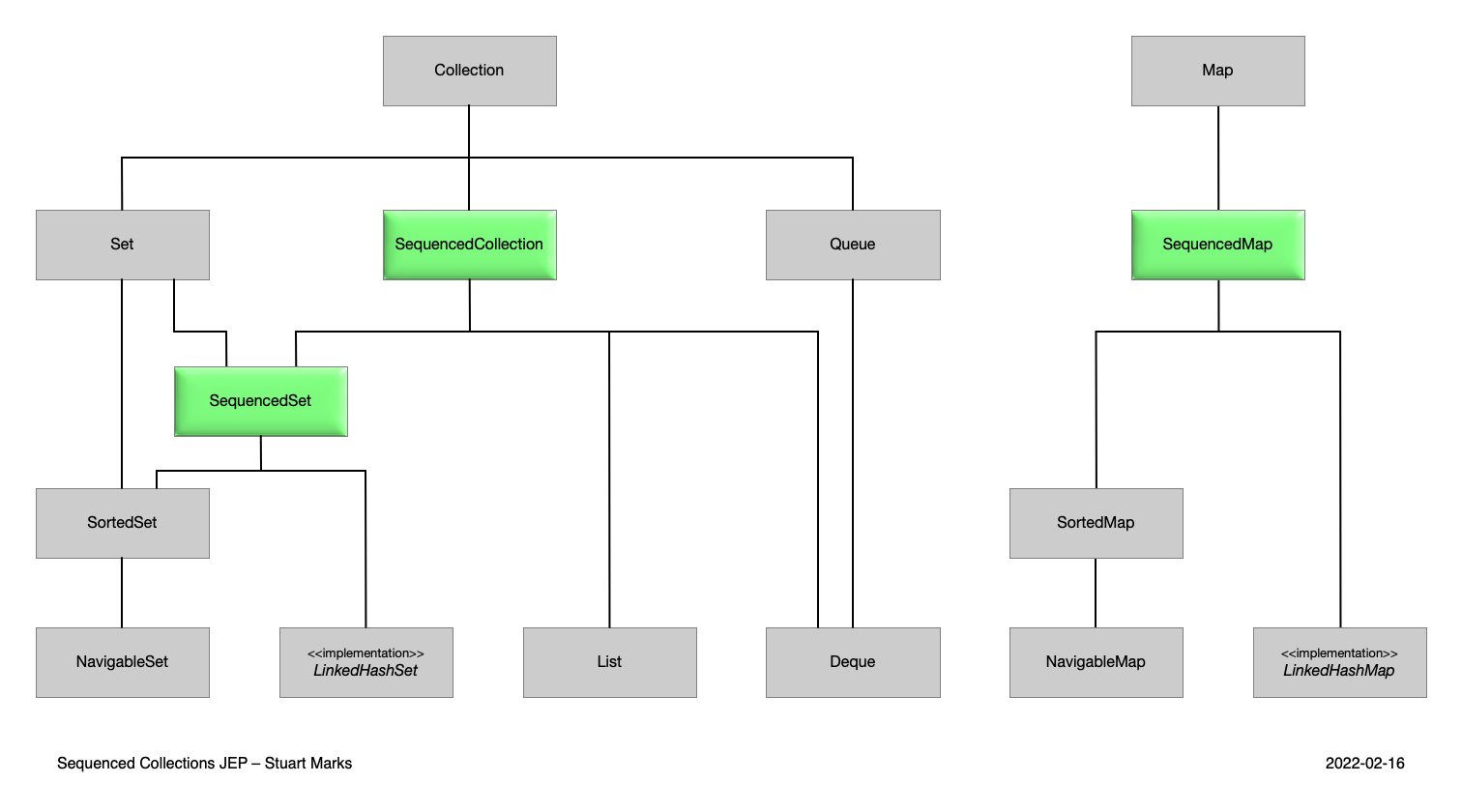
Image source: JEP 431.
Sequenced collections wprowadzają nowe wbudowane API w Javie, usprawniając operacje na uporządkowanych zbiorach danych. To API pozwala nie tylko na wygodny dostęp do pierwszego i ostatniego elementu kolekcji, ale także umożliwia wydajne przechodzenie (traversal), wstawianie w określonych pozycjach oraz pobieranie pod-sekwencji. Te ulepszenia sprawiają, że operacje zależne od kolejności elementów są prostsze i bardziej intuicyjne, poprawiając zarówno wydajność, jak i czytelność kodu podczas pracy z listami i podobnymi strukturami danych.
Oto pełny listing interfejsu SequencedCollection:
public interface SequencedCollection<E> extends Collection<E> {
SequencedCollection<E> reversed();
default void addFirst(E e) {
throw new UnsupportedOperationException();
}
default void addLast(E e) {
throw new UnsupportedOperationException();
}
default E getFirst() {
return this.iterator().next();
}
default E getLast() {
return this.reversed().iterator().next();
}
default E removeFirst() {
var it = this.iterator();
E e = it.next();
it.remove();
return e;
}
default E removeLast() {
var it = this.reversed().iterator();
E e = it.next();
it.remove();
return e;
}
}
Zatem teraz, zamiast:
var first = myList.stream().findFirst().get(); var anotherFirst = myList.get(0); var last = myList.get(myList.size() - 1);
Możemy po prostu napisać:
var first = sequencedCollection.getFirst(); var last = sequencedCollection.getLast(); var reversed = sequencedCollection.reversed();
Mała zmiana, ale moim zdaniem to bardzo wygodna i użyteczna funkcja.
Ze względu na podobieństwo Pattern Matching dla switch oraz Record Patterns, opiszę je razem. Record Patterns to świeża funkcja – zostały wprowadzone w Javie 19 (jako preview). Z drugiej strony, Pattern Matching dla switch jest poniekąd kontynuacją rozszerzonego wyrażenia instanceof. Wprowadza nową składnię dla instrukcji switch, która pozwala łatwiej wyrażać złożone zapytania zorientowane na dane.
Zapomnijmy na chwilę o podstawach OOP na potrzeby tego przykładu i ręcznie zdekonstruujmy obiekt pracownika (employee jest klasą typu POJO).
Przed Javą 21 wyglądało to tak:
if (employee instanceof Manager e) {
System.out.printf("I’m dealing with manager of %s department%n", e.department);
} else if (employee instanceof Engineer e) {
System.out.printf("I’m dealing with %s engineer.%n", e.speciality);
} else {
throw new IllegalStateException("Unexpected value: " + employee);
}
A gdybyśmy mogli pozbyć się brzydkiego instanceof? Cóż, teraz możemy, dzięki potędze Pattern Matching z Javy 21:
switch (employee) {
case Manager m -> printf("Manager of %s department%n", m.department);
_case Engineer e -> printf("I%s engineer.%n", e.speciality);
default -> throw new IllegalStateException("Unexpected value: " + employee);
}
Mówiąc o instrukcji switch, możemy również omówić funkcję Record Patterns. Podczas pracy z rekordem (Java Record), pozwala ona na znacznie więcej niż w przypadku standardowej klasy Java:
switch (shape) { // shape is a record
case Rectangle(int a, int b) -> System.out.printf("Area of rectangle [%d, %d] is: %d.%n", a, b, shape.calculateArea());
case Square(int a) -> System.out.printf("Area of square [%d] is: %d.%n", a, shape.calculateArea());
default -> throw new IllegalStateException("Unexpected value: " + shape);
}
Jak pokazuje kod, dzięki tej składni pola rekordu są łatwo dostępne. Co więcej, możemy dodać dodatkową logikę do naszych instrukcji case:
switch (shape) {
case Rectangle(int a, int b) when a < 0 || b < 0 -> System.out.printf("Incorrect values for rectangle [%d, %d].%n", a, b);
case Square(int a) when a < 0 -> System.out.printf("Incorrect values for square [%d].%n", a);
default -> System.out.println("Created shape is correct.%n");
}
Podobną składnię możemy zastosować w instrukcjach if. Również w poniższym przykładzie widać, że Record Patterns działają dla rekordów zagnieżdżonych:
if (r instanceof Rectangle(ColoredPoint(Point p, Color c),
ColoredPoint lr)) {
//sth
}
Funkcja Virtual Threads jest prawdopodobnie najbardziej gorącym tematem w całej Javie 21 – a przynajmniej tą nowością, na którą programiści Javy czekali najbardziej. Jak mówi dokumentacja JEP (podlinkowana w poprzednim zdaniu), jednym z celów wirtualnych wątków było „umożliwienie aplikacjom serwerowym napisanym w prostym stylu 'thread-per-request’ skalowania się przy bliskim optymalnemu wykorzystaniu sprzętu”. Czy oznacza to jednak, że powinniśmy migrować cały nasz kod używający java.lang.Thread?
Najpierw przyjrzyjmy się problemowi z podejściem, które istniało przed Javą 21 (właściwie od pierwszego wydania Javy). Możemy przyjąć w przybliżeniu, że jeden java.lang.Thread konsumuje (zależnie od systemu operacyjnego i konfiguracji) około 2 do 8 MB pamięci. Jednak kluczową kwestią jest to, że jeden wątek Java jest mapowany 1:1 na wątek jądra (kernel thread). W przypadku prostych aplikacji webowych, które stosują podejście „jeden wątek na żądanie”, łatwo obliczyć, że albo nasza maszyna zostanie „zabita” przy wzroście ruchu (nie będzie w stanie obsłużyć obciążenia), albo będziemy zmuszeni do zakupu urządzenia z większą ilością pamięci RAM, co zwiększy nasze rachunki w AWS.
Oczywiście wirtualne wątki nie są jedynym sposobem na rozwiązanie tego problemu. Mamy programowanie asynchroniczne (frameworki takie jak WebFlux czy natywne Java API jak CompletableFuture). Jednak z jakiegoś powodu – być może przez „nieprzyjazne API” lub wysoki próg wejścia – te rozwiązania nie są aż tak popularne.
Virtual Threads nie są nadzorowane ani harmonogramowane przez system operacyjny. Ich planowaniem zajmuje się JVM. Podczas gdy realne zadania muszą być wykonywane w wątku platformy (platform thread), JVM wykorzystuje tzw. carrier threads – w istocie wątki platformy – do „noszenia” dowolnego wirtualnego wątku, gdy nadejdzie czas jego wykonania. Virtual Threads są zaprojektowane jako lekkie i zużywają znacznie mniej pamięci niż standardowe wątki platformy.
Poniższy diagram pokazuje, jak wirtualne wątki są powiązane z wątkami platformy i systemu operacyjnego:
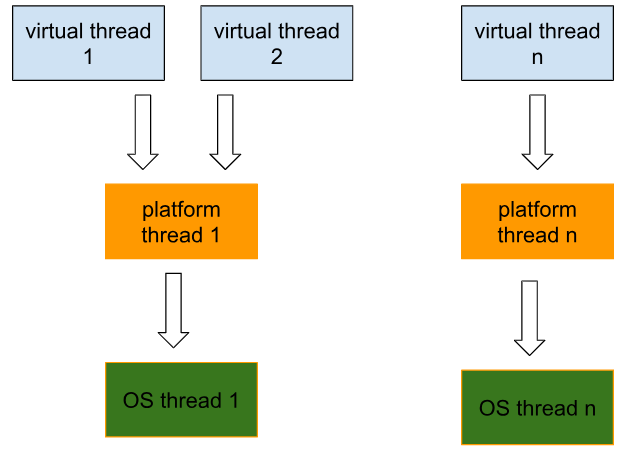
Aby zobaczyć, jak wirtualne wątki są używane przez wątki platformy, uruchommy kod, który startuje (1 + liczba rdzeni procesora, w moim przypadku 8 rdzeni) wirtualnych wątków.
var numberOfCores = 8; //
final ThreadFactory factory = Thread.ofVirtual().name("vt-", 0).factory();
try (var executor = Executors.newThreadPerTaskExecutor(factory)) {
IntStream.range(0, numberOfCores + 1)
.forEach(i -> executor.submit(() -> {
var thread = Thread.currentThread();
System.out.println(STR."[{thread}] VT number: {i}");
try {
sleep(Duration.ofSeconds(1L));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}));
}
Wynik wygląda następująco:
[VirtualThread[#29,vt-6]/runnable@ForkJoinPool-1-worker-7] VT number: 6 [VirtualThread[#26,vt-4]/runnable@ForkJoinPool-1-worker-5] VT number: 4 [VirtualThread[#30,vt-7]/runnable@ForkJoinPool-1-worker-8] VT number: 7 [VirtualThread[#24,vt-2]/runnable@ForkJoinPool-1-worker-3] VT number: 2 [VirtualThread[#23,vt-1]/runnable@ForkJoinPool-1-worker-2] VT number: 1 [VirtualThread[#27,vt-5]/runnable@ForkJoinPool-1-worker-6] VT number: 5 [VirtualThread[#31,vt-8]/runnable@ForkJoinPool-1-worker-6] VT number: 8 [VirtualThread[#25,vt-3]/runnable@ForkJoinPool-1-worker-4] VT number: 3 [VirtualThread[#21,vt-0]/runnable@ForkJoinPool-1-worker-1] VT number: 0
Zatem wątki platformy ForkJonPool-1-worker-X są naszymi wątkami nośnymi (carrier threads), które zarządzają naszymi wirtualnymi wątkami. Widzimy, że wirtualne wątki numer 5 i 8 używają tego samego wątku nośnego o numerze 6.
Ostatnią rzeczą dotyczącą Virtual Threads, którą chcę Ci pokazać, jest to, jak mogą one pomóc w przypadku blokujących operacji I/O.
Ilekroć wirtualny wątek napotka operację blokującą, taką jak zadania I/O, JVM wydajnie odłącza go od bazowego wątku fizycznego (wątku nośnego). To odłączenie jest krytyczne, ponieważ zwalnia wątek nośny do uruchamiania innych wirtualnych wątków zamiast pozostawania w stanie bezczynności w oczekiwaniu na zakończenie operacji blokującej. W rezultacie pojedynczy wątek nośny może multipleksować wiele wirtualnych wątków, których liczba może iść w tysiące, a nawet miliony, zależnie od dostępnej pamięci i natury wykonywanych zadań.
Spróbujmy zasymulować to zachowanie. W tym celu wymusimy, aby nasz kod używał tylko jednego rdzenia procesora, z tylko 2 wirtualnymi wątkami – dla większej przejrzystości.
System.setProperty("jdk.virtualThreadScheduler.parallelism", "1");
System.setProperty("jdk.virtualThreadScheduler.maxPoolSize", "1");
System.setProperty("jdk.virtualThreadScheduler.minRunnable", "1");
Wątek 1:
Thread v1 = Thread.ofVirtual().name("long-running-thread").start(
() -> {
var thread = Thread.currentThread();
while (true) {
try {
Thread.sleep(250L);
System.out.println(STR."[{thread}] - Handling http request ....");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
);
Wątek 2:
Thread v2 = Thread.ofVirtual().name("entertainment-thread").start(
() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
var thread = Thread.currentThread();
System.out.println(STR."[{thread}] - Executing when 'http-thread' hit 'sleep' function");
}
);
Wykonanie:
v1.join(); v2.join();
Wynik:
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request .... [VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request .... [VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request .... [VirtualThread[#23,entertainment-thread]/runnable@ForkJoinPool-1-worker-1] - Executing when 'http-thread' hit 'sleep' function [VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request .... [VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request .... [VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request .... [VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request .... [VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request .... [VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
Zauważamy, że oba wirtualne wątki (long-running-thread i entertainment-thread) są obsługiwane tylko przez jeden wątek platformy, którym jest ForkJoinPool-1-worker-1.
Podsumowując, ten model pozwala aplikacjom Java osiągać wysoki poziom współbieżności i skalowalności przy znacznie niższych kosztach operacyjnych niż tradycyjne modele wątków, gdzie każdy wątek mapuje się bezpośrednio na pojedynczy wątek systemu operacyjnego. Warto zaznaczyć, że wirtualne wątki to rozległy temat, a to, co opisałem, to tylko niewielki ułamek. Gorąco zachęcam do zgłębienia wiedzy o harmonogramowaniu, przypiętych wątkach (pinned threads) i wewnętrznych mechanizmach VirtualThreads.
Opisane powyżej funkcje uważam za najważniejsze w Javie 21. Większość z nich nie jest tak przełomowa jak niektóre rzeczy wprowadzone w JDK 17, ale wciąż są bardzo użyteczne i stanowią miłe zmiany typu QOL (Quality of Life).
Nie powinieneś jednak lekceważyć innych ulepszeń w JDK 21 – bardzo zachęcam do przeanalizowania pełnej listy i dalszego eksplorowania wszystkich nowości. Na przykład, rzeczą którą uważam za szczególnie godną uwagi, jest Vector API, które pozwala na obliczenia wektorowe na niektórych wspieranych architekturach CPU – co wcześniej nie było możliwe. Obecnie znajduje się ono w fazie inkubatora/eksperymentalnej (dlatego nie opisywałem go tutaj szczegółowo), ale niesie ze sobą wielką obietnicę dla przyszłości Javy.
Ogólnie rzecz biorąc, postęp, jaki Java poczyniła w różnych obszarach, sygnalizuje ciągłe zaangażowanie zespołu w poprawę wydajności i efektywności w wymagających aplikacjach.
Jeśli interesuje Cię Java, koniecznie sprawdź nasze inne artykuły:
Oto odpowiedzi na kilka powszechnych pytań dotyczących JDK 21, jak również natywnego interfejsu i funkcji Javy.
Java SE (Java Platform, Standard Edition) to podstawowa platforma do tworzenia i wdrażania aplikacji Java na komputerach stacjonarnych i serwerach.
To funkcja w fazie preview, która pozwala programom Java współdziałać z danymi i kodem poza środowiskiem uruchomieniowym Java. API to umożliwia programom Java wywoływanie natywnych bibliotek i przetwarzanie natywnych danych w sposób bezpieczniejszy niż w przypadku JNI. API to narzędzie do bezpiecznego dostępu do obcej pamięci i kodu oraz wydajnego wywoływania obcych funkcji.
Jednym z kluczowych aspektów jest code review (możesz użyć narzędzi AI do code review, aby uczynić ten proces nieco mniej czasochłonnym).
Dynamiczne ładowanie (dynamic loading) w Javie odnosi się do ładowania klas lub zasobów w czasie wykonywania (runtime), a nie podczas początkowego uruchamiania programu.
Współbieżność strukturalna (structured concurrency) w Javie to podejście, które organizuje procesy współbieżne w kontrolowany sposób, mając na celu poprawę łatwości utrzymania, niezawodności i obserwowalności kodu wielowątkowego.




