
[Uwaga] Ten artykuł został pierwotnie opublikowany w marcu 2021 r., ale w lutym 2024 r. został zaktualizowany o nową treść – w dużej mierze napisany od nowa.
[Uwaga] Ten artykuł został pierwotnie przygotowany w języku angielskim i został przetłumaczony na język polski.
Ten poradnik skupia się na konfiguracji Liquibase dla bazy danych Oracle, ale proces i organizacja plików są podobne w przypadku wszystkich innych baz danych obsługiwanych przez Liquibase.
Oto repozytorium GitHub, w którym znajdziesz pliki, których używam w poniższych przykładach.
Czy ręcznie wykonujesz skrypty na swojej bazie danych? A może marnujesz czas na sprawdzanie skryptów bazy danych otrzymanych od zespołu?
Czy po tym wszystkim łączysz skrypty w jeden plik i wykonujesz je w każdym środowisku? Co z błędami wdrożeniowymi? Czy kiedykolwiek spędziłeś godziny sprawdzając, kto i dlaczego zmienił coś w bazie danych?
Możesz usprawnić to wszystko za pomocą Liquibase.
Ale co, jeśli nie możesz teraz wdrożyć całego procesu CI/CD lub polityka firmy nie pozwala na uruchamianie skryptów w określonych środowiskach? To dla Liquibase również nie problem.
Używając Liquibase, możesz:
Dzięki temu zyskasz:
W serii artykułów pokażę Ci, jak zautomatyzowaliśmy proces zmian w bazie danych w Pretius przy użyciu Liquibase i GIT – zacznijmy od tego podstawowego poradnika.
Liquibase to narzędzie typu open-source napisane w Javie. Ułatwia definiowanie zmian w bazie danych w formacie, który jest znany i wygodny dla każdego użytkownika. Następnie automatycznie generuje SQL specyficzny dla danej bazy danych.
Zmiany w bazie danych (każda zmiana nazywana jest changeset) są zarządzane w plikach zwanych changelogs. Moje przykłady będą oparte na changesetach napisanych w SQL – to najprostszy sposób na rozpoczęcie automatyzacji procesu zmian w bazie danych Oracle.
Teraz omówmy kilka podstawowych terminów i szczegółów, które pomogą Ci zrozumieć, jak działa Liquibase i co robi.
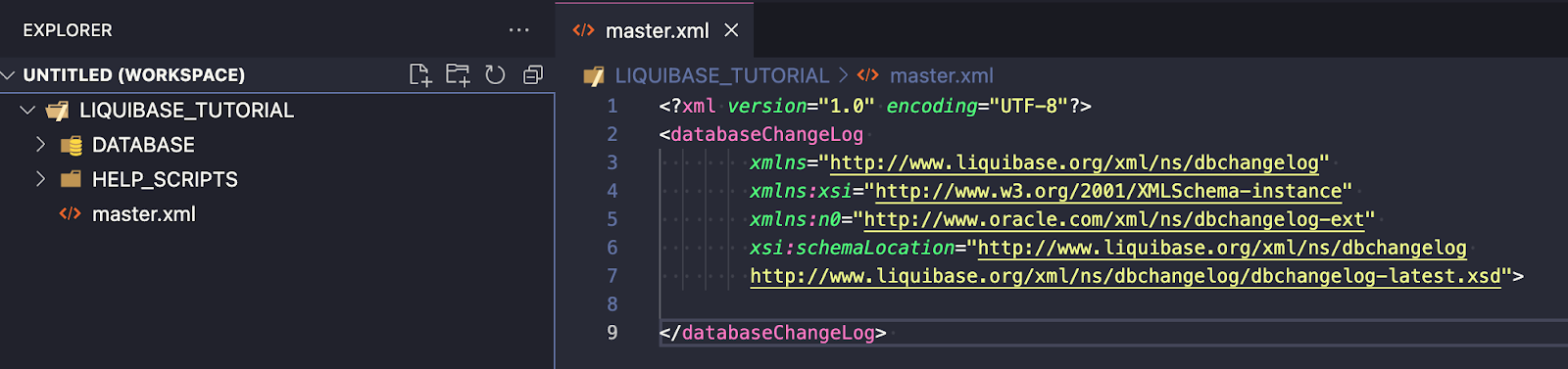
Liquibase używa plików changelog (w formatach SQL, XML, YAML lub JSON), aby wylistować zmiany w bazie danych w kolejności sekwencyjnej. Oto przykład changelogu:
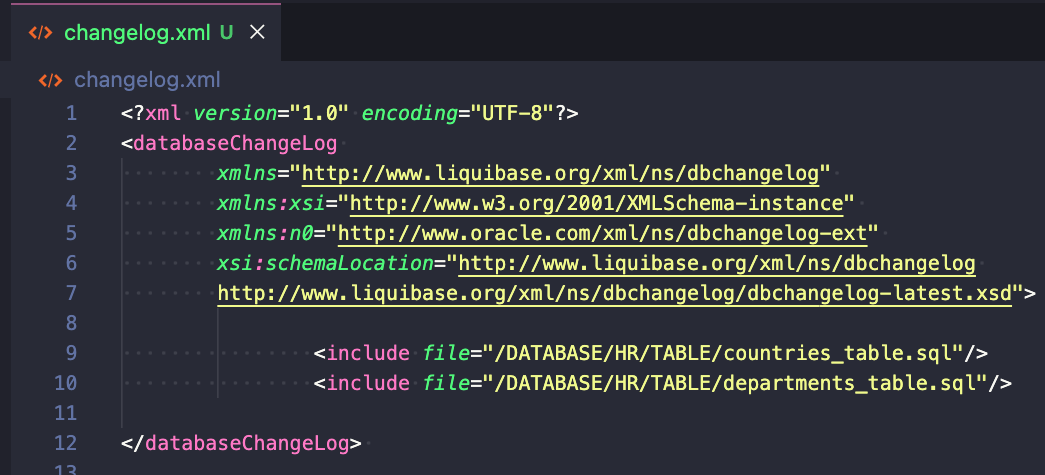
Powyższy przykład zawiera ścieżkę do dwóch innych changelogów (tabele countries i departments ).
Zmiana w bazie danych nazywana jest changeset. Istnieje wiele typów changesetów, które można zastosować w bazie danych, takich jak tworzenie tabeli, dodawanie klucza głównego lub tworzenie paczki (package).
Plik departments_table.sql to changelog zawierający dwa changesety:
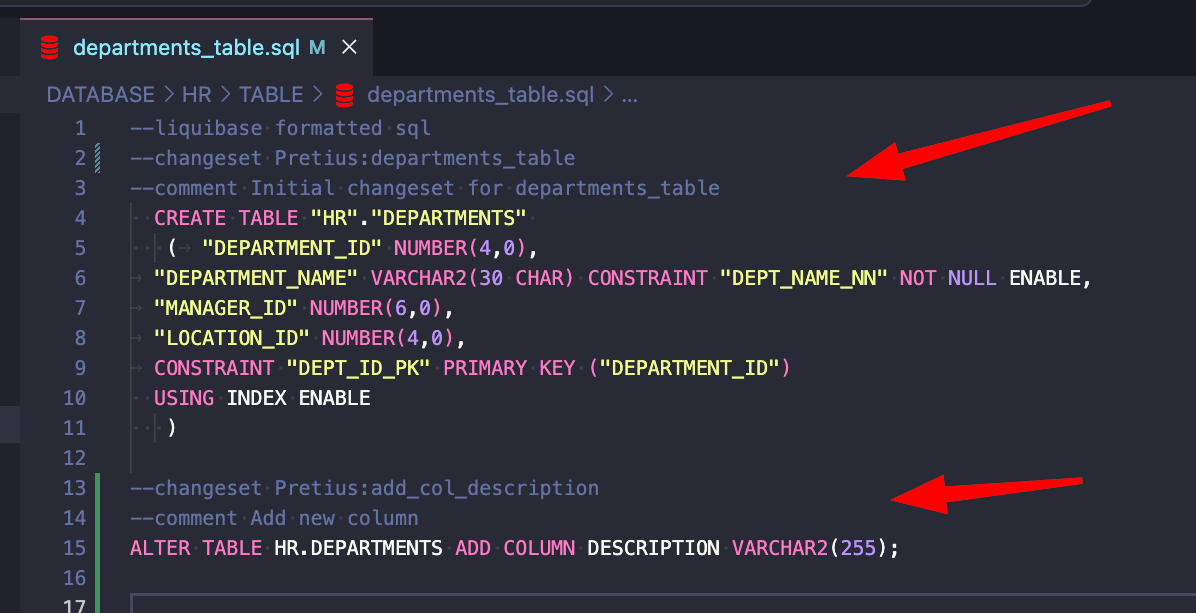
Legenda:
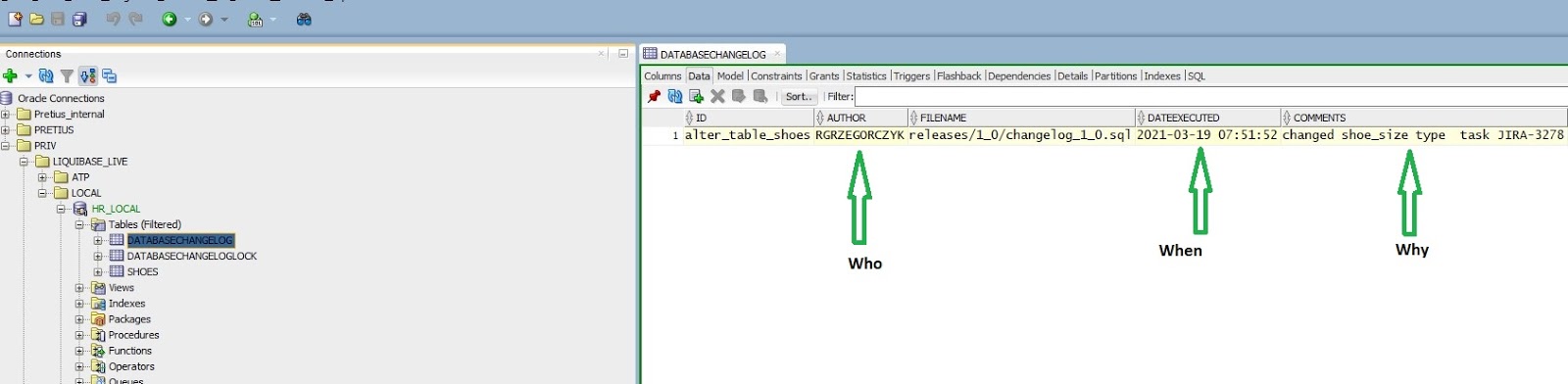
Changeset jest unikalnie identyfikowany przez atrybuty autor oraz id , a także ścieżkę do pliku changelog.
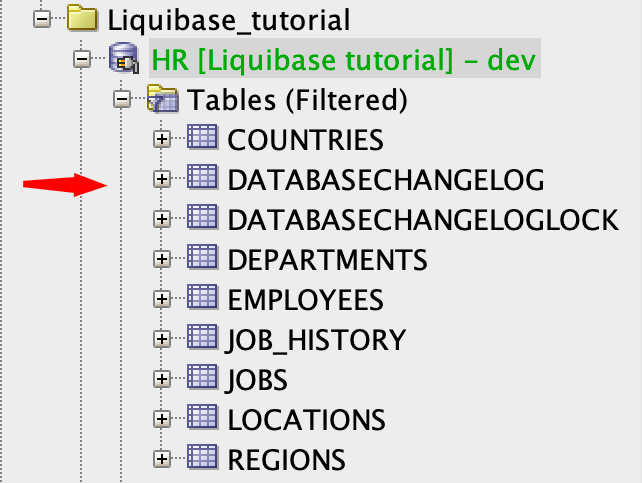
Liquibase używa tabeli DATABASECHANGELOG do śledzenia, które changesety zostały uruchomione. Jeśli tabela nie istnieje w bazie danych, Liquibase tworzy ją automatycznie.
Liquibase utworzy również tabelę DATABASECHANGELOGLOCK . Będzie ona używana do tworzenia blokad, aby uniknąć jednoczesnego uruchamiania Liquibase w Twojej bazie danych.
To wszystko, jeśli chodzi o podstawy. Dowiesz się więcej, czytając ten poradnik i analizując pokazane przykłady.
Początkowy proces instalacji jest dość prosty. Nie będę go opisywał w tym artykule, ale mam kilka wpisów na moim blogu Hashnode, które przeprowadzą Cię przez to krok po kroku:
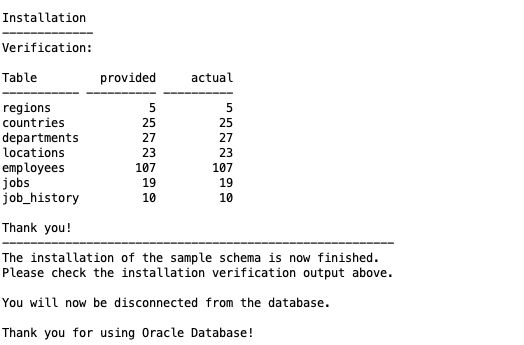
Teraz pokażę Ci, jak skonfigurować wszystko dla Twojego istniejącego projektu. Będziesz musiał wykonać kilka kroków.
Zaleca się, aby środowiska były identyczne przed użyciem Liquibase. Zazwyczaj zalecam dwa sposoby, aby to osiągnąć.
Jeśli uważasz, że różnice między Twoimi bazami danych są ogromne i niekontrolowane, powinieneś użyć Oracle Data Pump:
Ewentualnie, jeśli przypuszczasz, że bazy danych są niemal identyczne i nie zajmie to dużo czasu, możesz po prostu zrobić wszystko ręcznie.
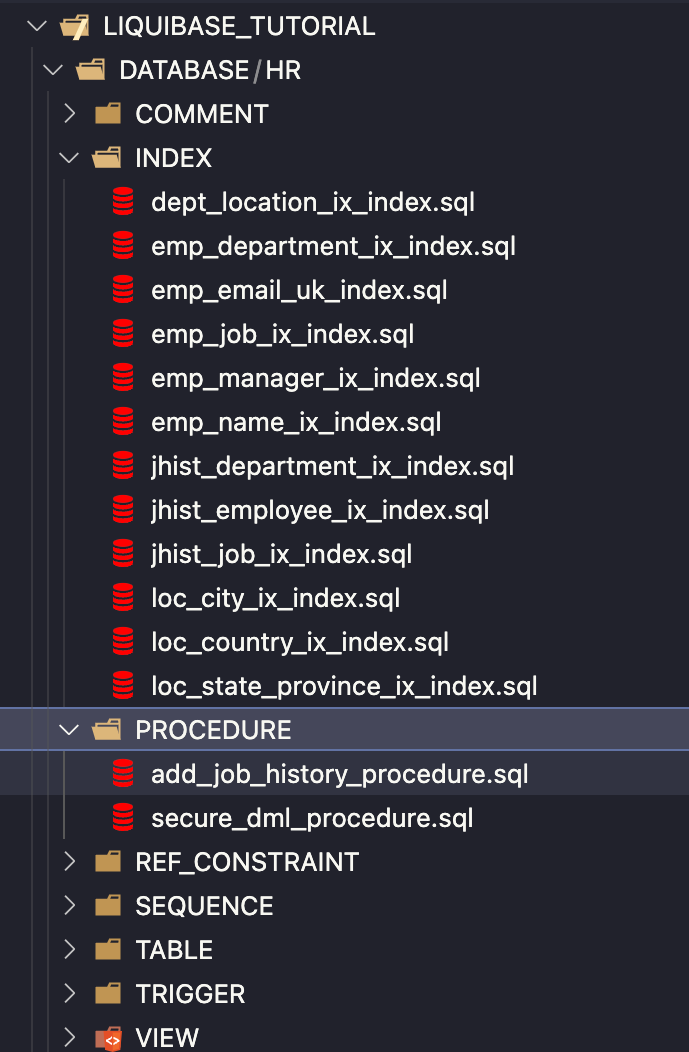
Utworzyłem folder DATABASE/HR/, którego użyję do przechwycenia mojego bieżącego schematu ze środowiska HR_DEV . Użyję do tego SQLcl Liquibase.
Przejdź do folderu [TWÓJ_ROOT_REPOZYTORIUM]/DATABASE/HR/ . W moim przykładzie jest to LIQUIBASE_TUTORIAL/DATABASE/HR/. Połącz się z bazą danych HR_DEV.
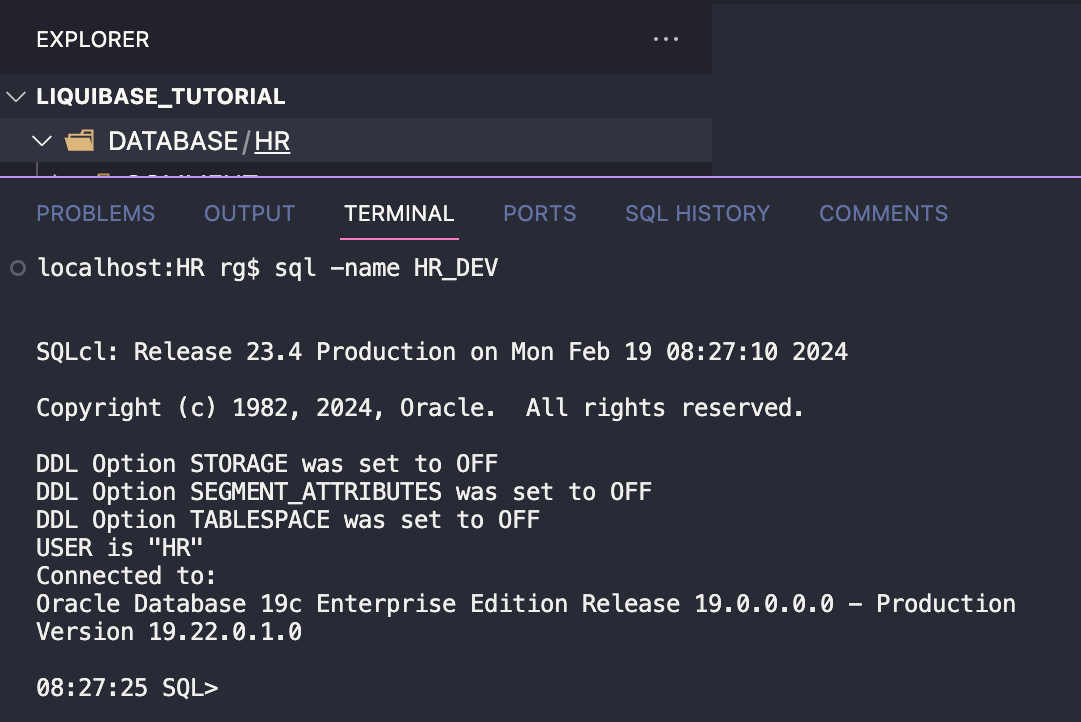
Aby przechwycić wszystkie obiekty mojego schematu HR , możesz użyć polecenia generate-schema:
liquibase generate-schema -split -sql
W zależności od rozmiaru bazy danych może to potrwać od kilku minut do nawet 1-4 godzin.
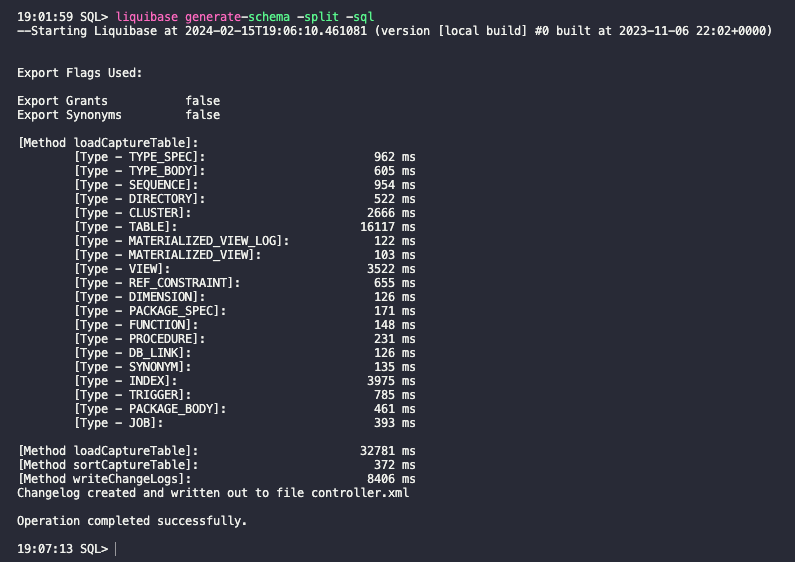
SQLcl Liquibase automatycznie wygenerował wszystkie obiekty mojego schematu w osobnych folderach. Pliki zostały wygenerowane w formatach XML i SQL.
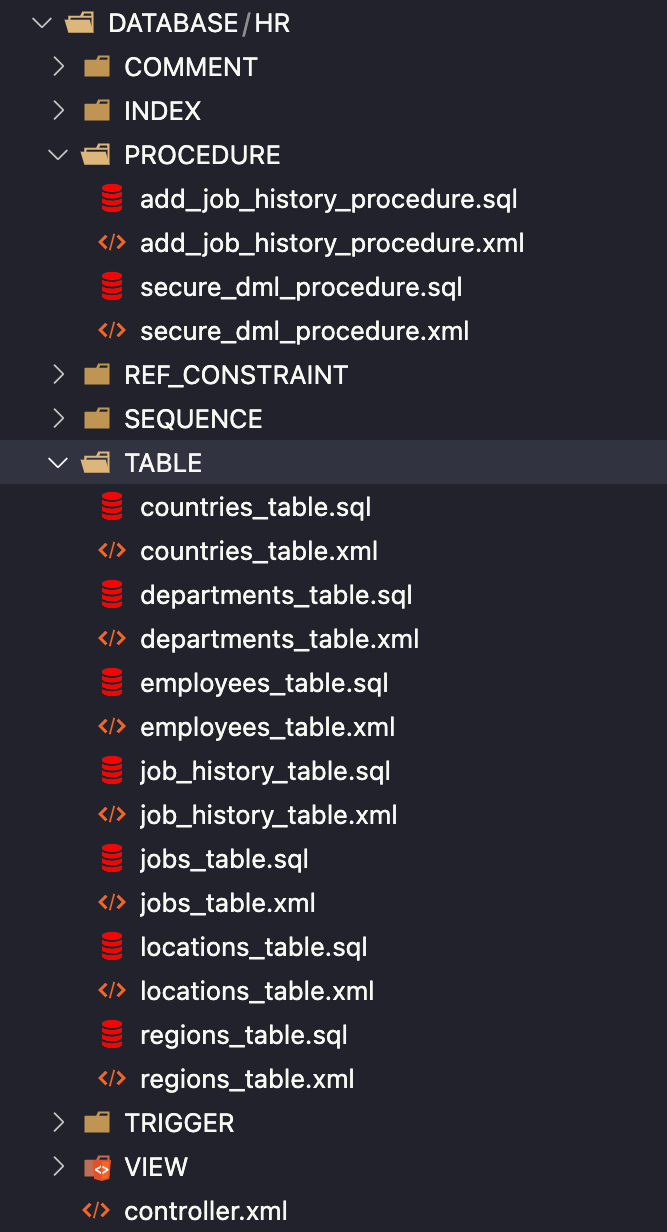
Format XML jest świetny i oferuje znacznie więcej funkcjonalności Liquibase – ale nie będę go używać w tym poradniku (więcej o formatach XML przeczytasz w dokumentacji). Dlatego muszę usunąć wszystkie wygenerowane pliki XML. Można to zrobić na dwa sposoby.
Ponownie, jeśli nie masz wielu plików, możesz zrobić wszystko ręcznie. Alternatywnie możesz użyć załączonego skryptu PowerShell, który zrobi to za Ciebie, jeśli Twoja baza danych jest duża:
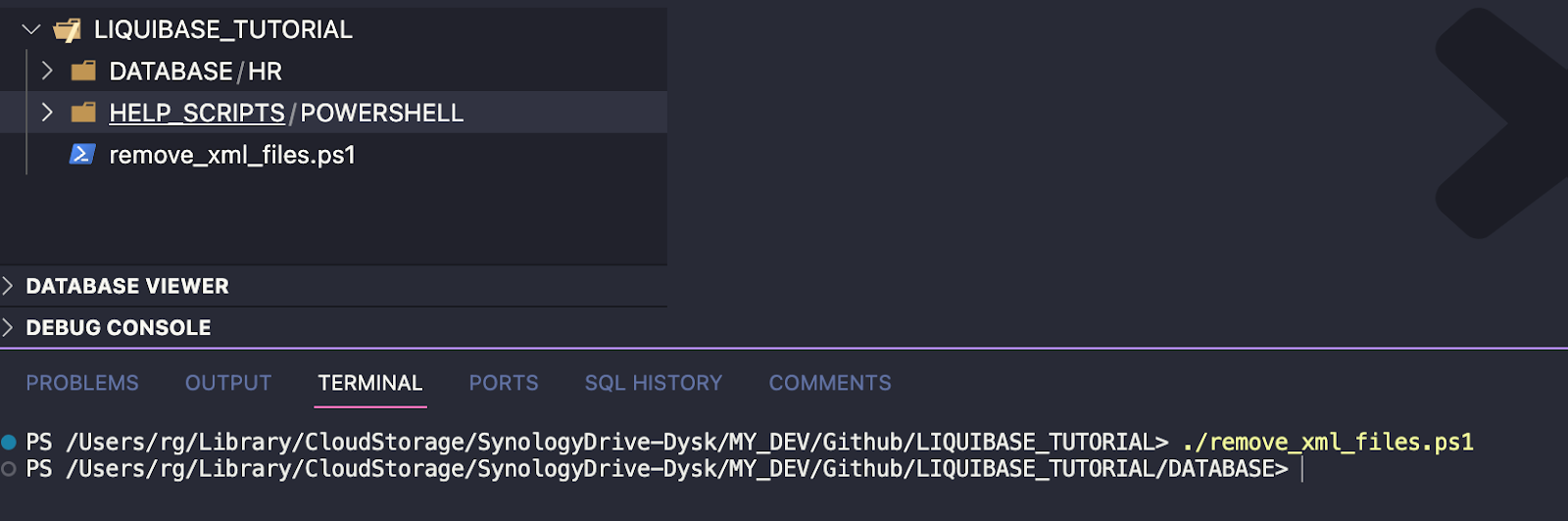
W efekcie w osobnych folderach mam tylko pliki SQL.
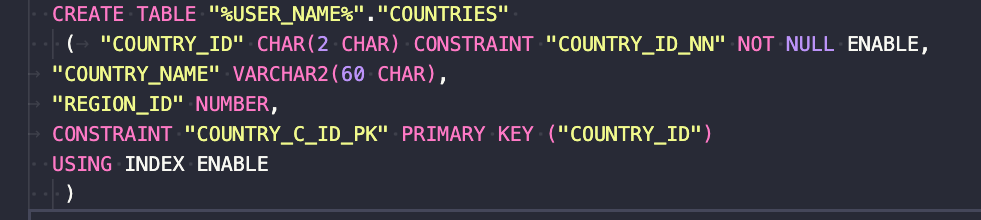
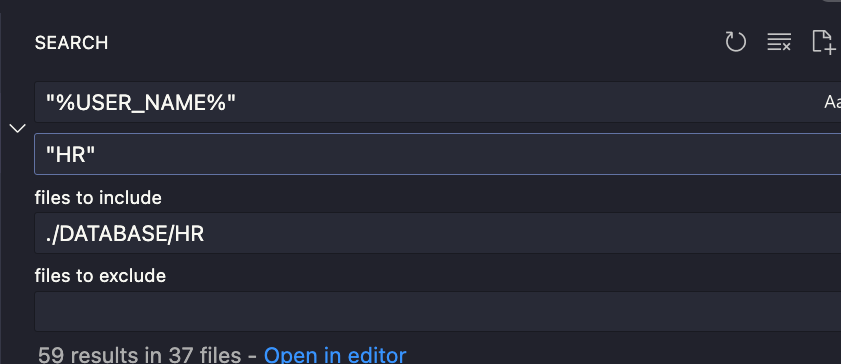
Dostosuj automatycznie wygenerowane pliki SQL do dalszego użytku z Liquibase – usuń string „%USER_NAME%” (to prawdopodobnie problem w SQLcl 23.4 – do potwierdzenia) ze wszystkich plików SQL i zastąp go swoją nazwą schematu.
Jeśli pracujesz z istniejącym projektem, musisz dodać składnię Liquibase do wszystkich automatycznie wygenerowanych plików SQL. Możesz to zrobić ręcznie lub użyć mojego skryptu PowerShell, który zrobi to za Ciebie.
![]()
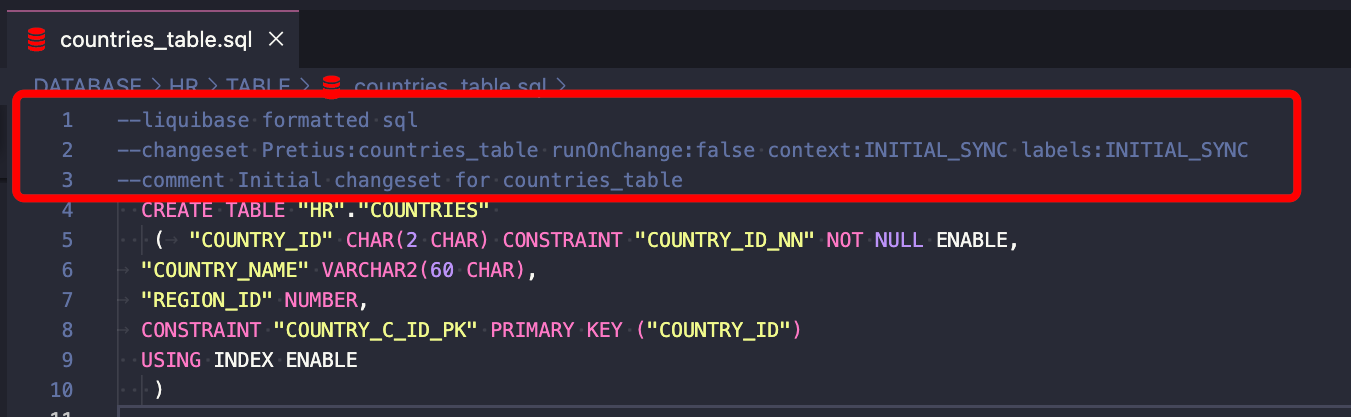
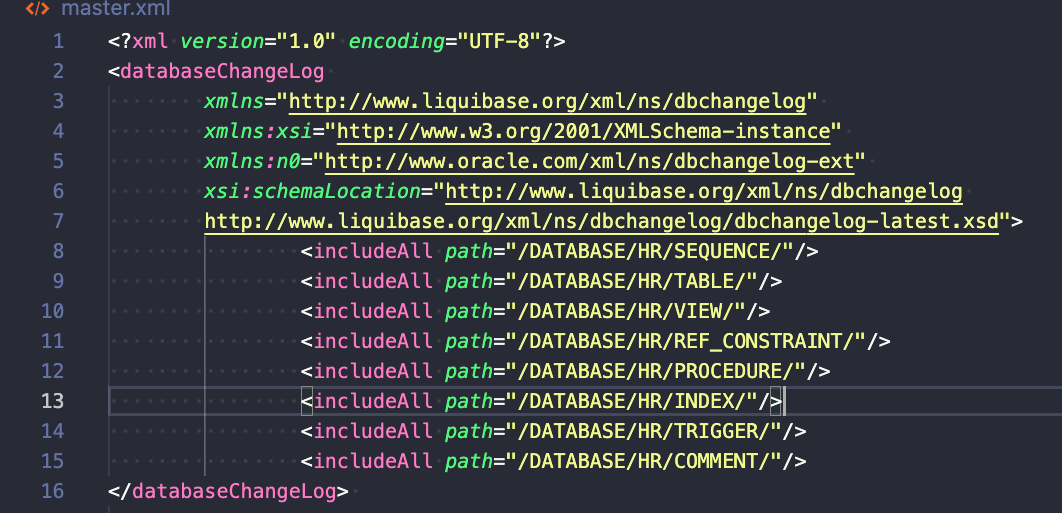
Teraz stwórzmy changelogi, aby kontrolować Twoje repozytorium obiektów. Ten krok jest niezbędny zarówno dla istniejących, jak i nowych projektów.
Legenda:
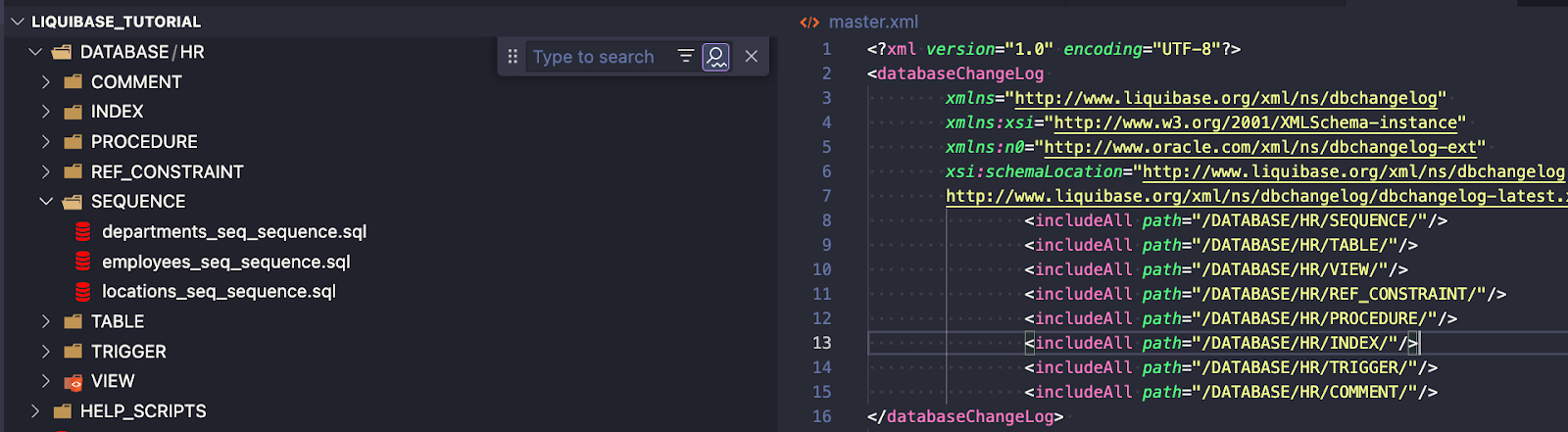
Aby pokazać, jak używać includeFile, przygotowałem przykład dla wszystkich moich procedur wewnątrz folderu /DATABASE/HR/PROCEDURE/:
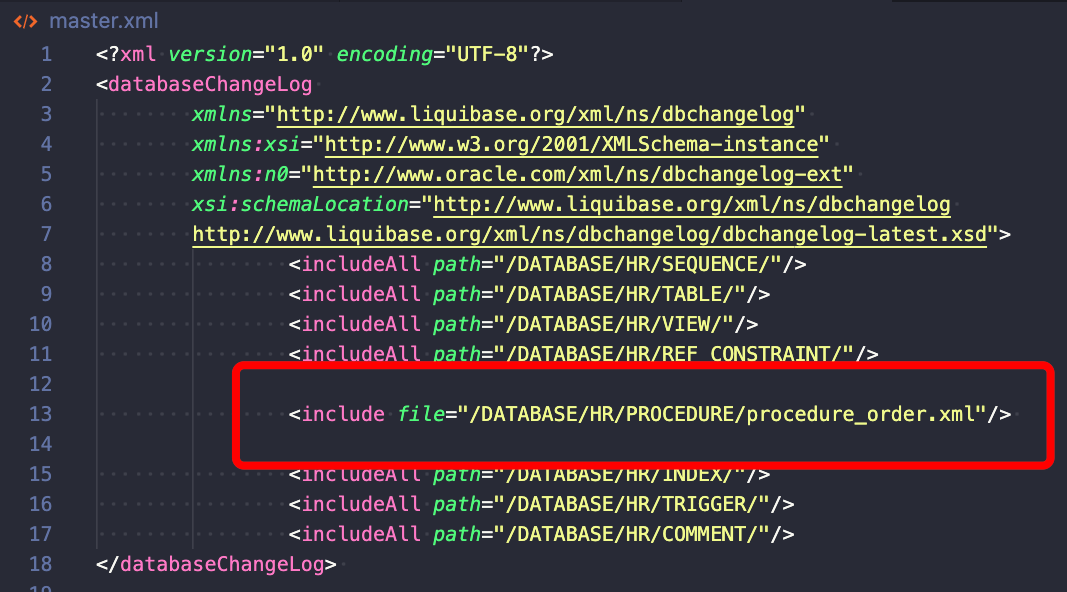
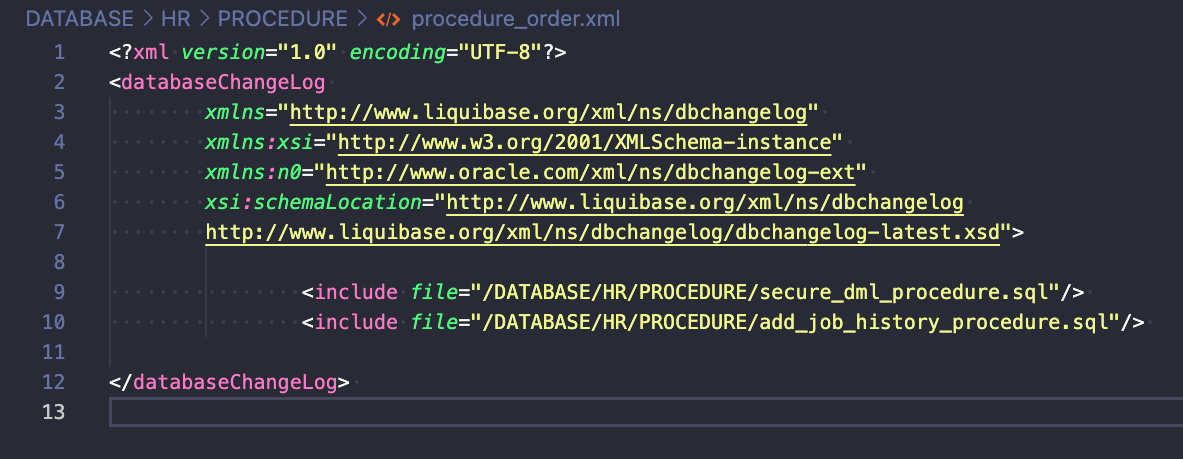
W tym przykładzie wyraźnie wskazuję, który plik powinien być wykonany w jakiej kolejności.
Możesz tworzyć takie changelogi dla wszystkich swoich folderów i używać dowolnej ich liczby.
Utworzyłem dwa połączenia, korzystając z poradnika instalacji z początku tego przewodnika. Jedno dla środowiska DEV , a drugie dla PROD .
Kolejnym krokiem jest synchronizacja istniejącej bazy danych z Liquibase – oczywiście będzie to konieczne tylko w przypadku istniejących projektów. Celem jest „poinformowanie” Liquibase, że wszystkie pliki w Twoim repozytorium już istnieją w Twojej bazie danych i pliki te nie powinny być wykonywane, dopóki ktoś nie zmieni czegoś w kodzie.
Moje dwa środowiska DEV i PROD są teraz identyczne, więc muszę je zsynchronizować – jest to tylko jednorazowy krok, gdy zaczynasz używać Liquibase w istniejącym projekcie.
Polecenie changelog-sync oznacza wszystkie zmiany w changelogu jako wykonane w Twoiej bazie danych (dowiedz się więcej w dokumentacji Liquibase).
liquibase --defaults-file=dev.liquibase.properties --changelog-sync-sql
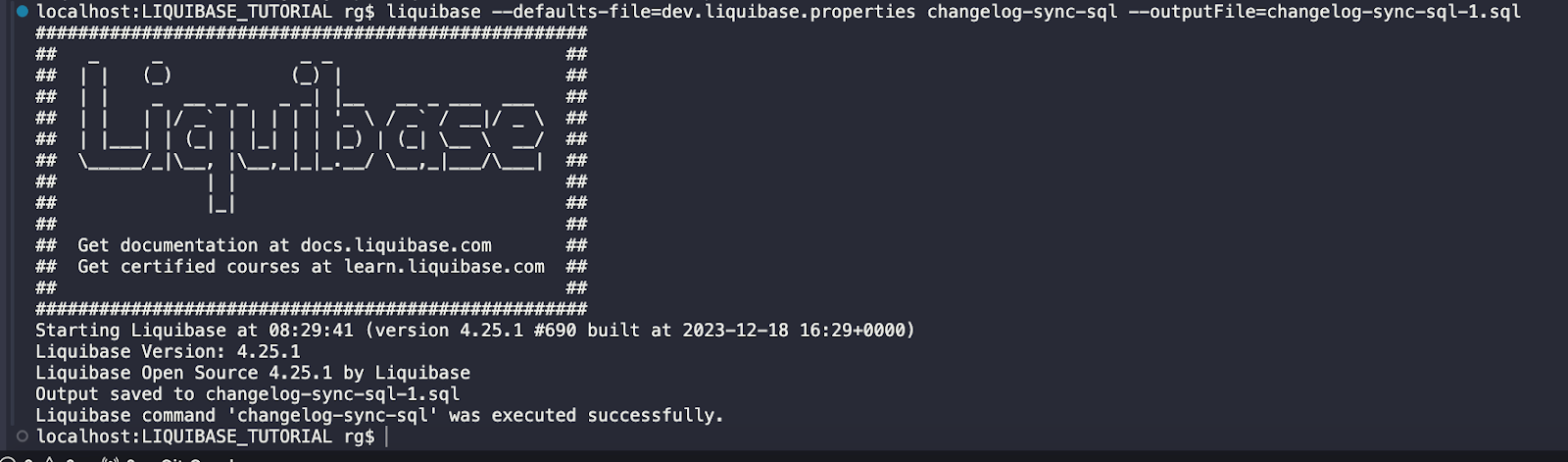
Użyłem najpierw polecenia changelog-sync-sql, aby wygenerować plik SQL i zweryfikować, co zostanie wykonane po uruchomieniu polecenia changelog-sync.
Nie użyłem filtrowania po etykietach (labels), np. –label-filter=INITIAL_SYNC, ponieważ w tej chwili chcę przechwycić wszystkie moje zmiany.
Gdyby jednak moje polecenie wyglądało tak, wynik i plik wyjściowy byłyby takie same:
liquibase --defaults-file=dev.liquibase.properties --changelog-sync-sql -label-filter=INITIAL_SYNC
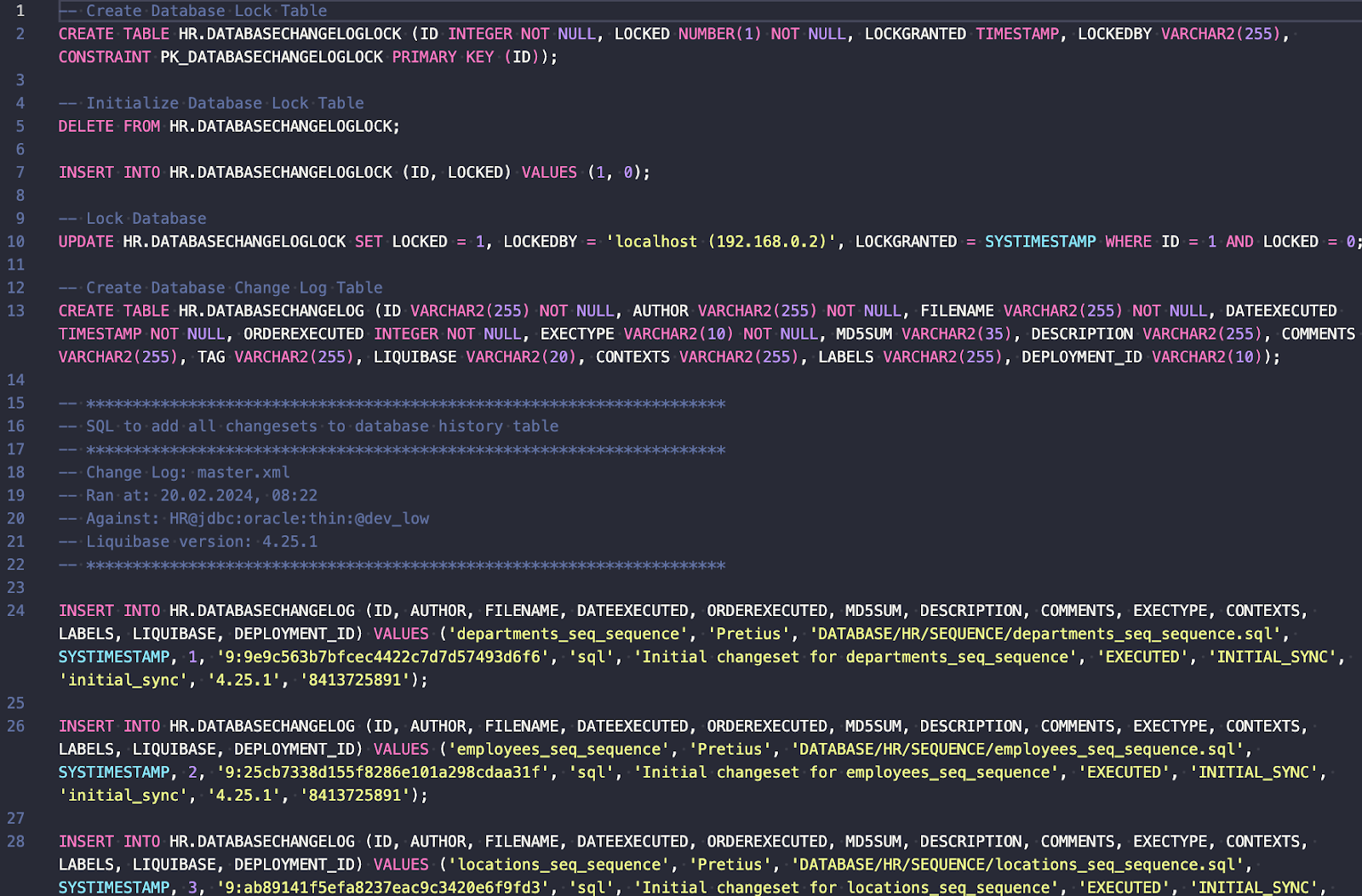
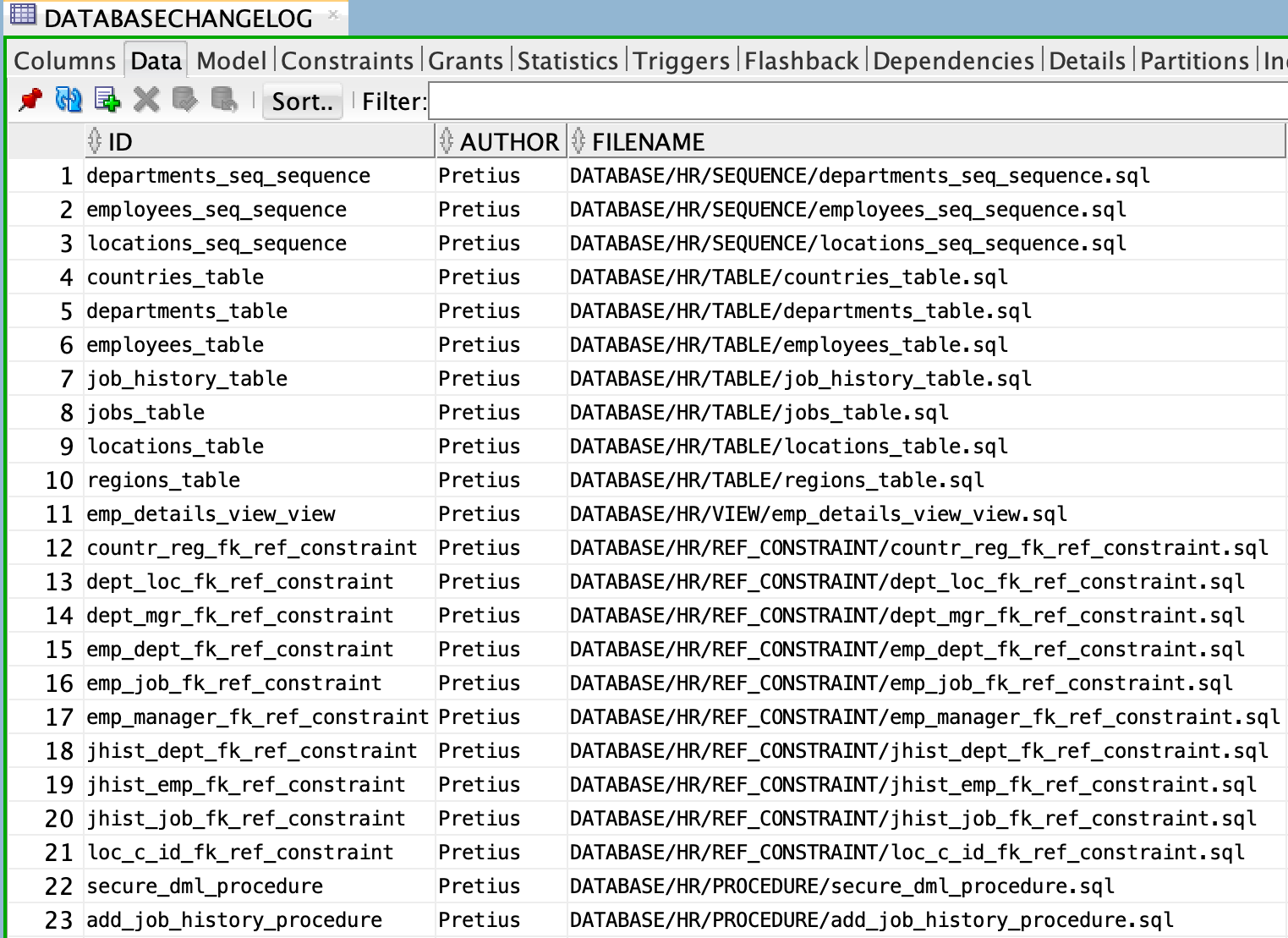
Jak widzisz, Liquibase utworzy tabele DATABASECHANGELOGLOCK i DATABASECHANGELOG – ponieważ jest to pierwszy bieg Liquibase.
Co więcej, wiele wierszy zostanie wstawionych do tabeli DATABASECHANGELOG, oznaczając wszystkie changesety jako już wykonane.
Żaden inny kod bazy danych nie zostanie wykonany – brak zmian w istniejących obiektach. Pełny wygenerowany skrypt możesz zobaczyć tutaj.
Dobrą praktyką jest najpierw uruchamianie poleceń z opcją -sql i podglądanie, co się stanie, zamiast wykonywania niezamierzonego kodu.
Teraz wykonam polecenie changelog-sync.
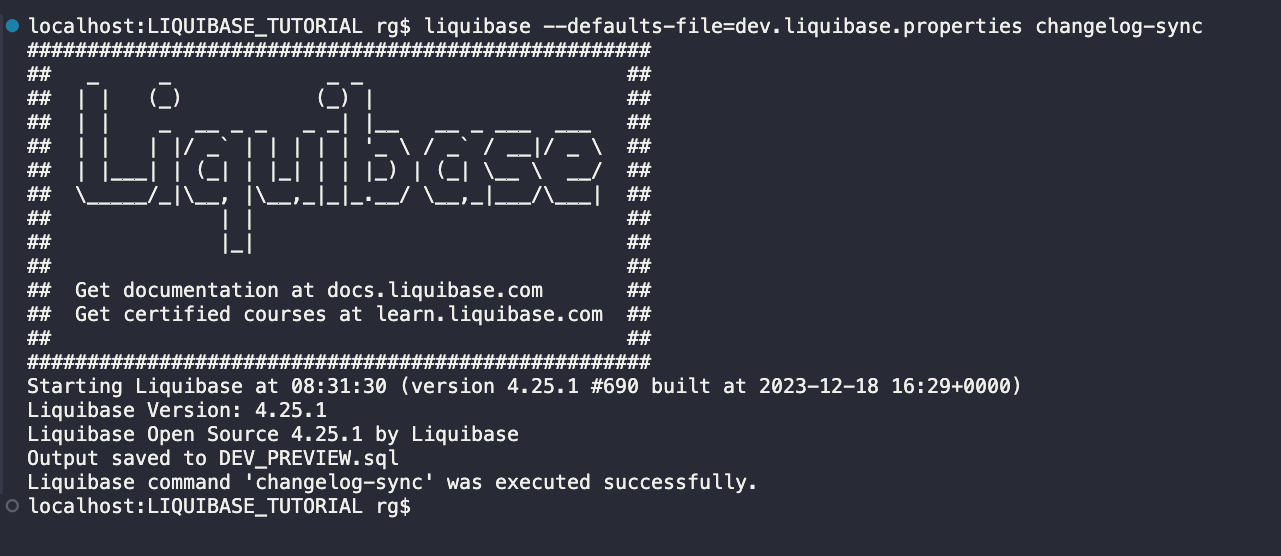
Dwie tabele zostały utworzone, a wiersze do DATABASECHANGELOG zostały wstawione.
Przed powtórzeniem kroków pamiętaj o zmianie pliku połączenia.
liquibase --defaults-file=prod.liquibase.properties --changelog-sync-sql
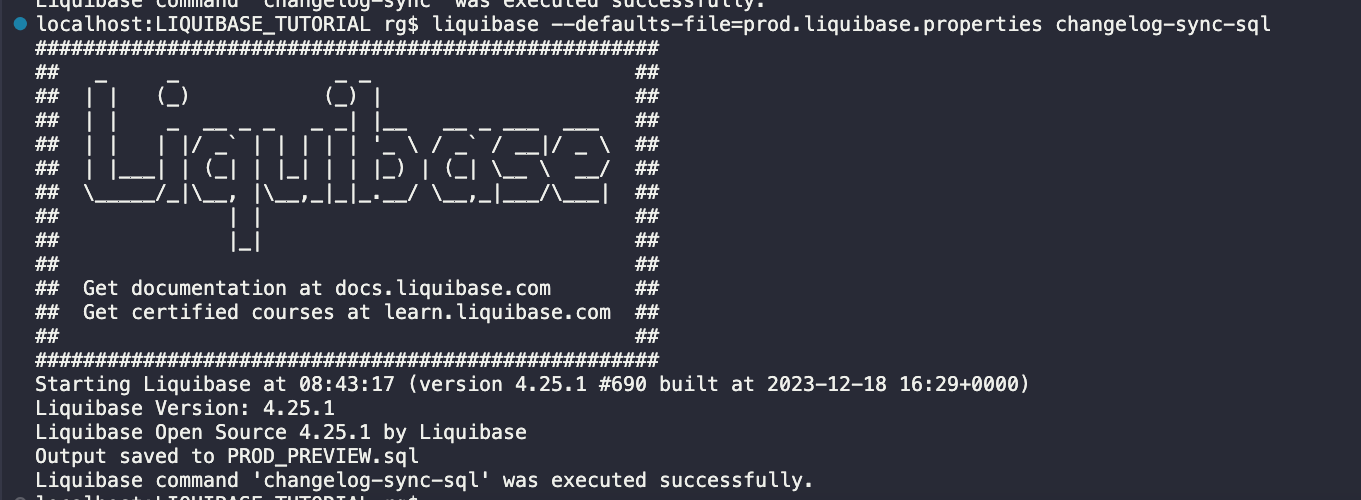
Plik podglądu był w porządku, więc wykonam changelog-sync.
liquibase --defaults-file=prod.liquibase.properties --changelog-sync
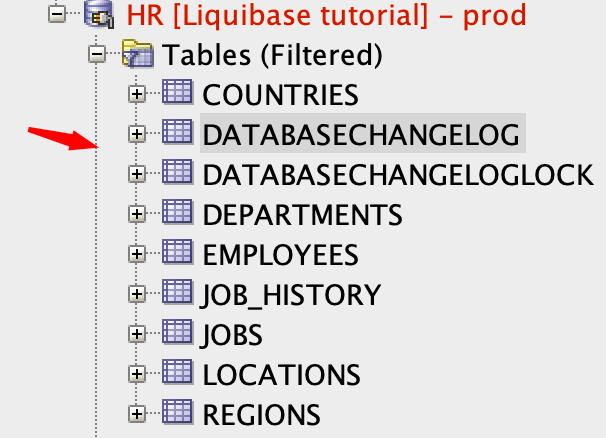
Wynik jest taki sam jak na DEV – dwie tabele zostały utworzone, a wiersze do DATABASECHANGELOG zostały wstawione. Twój istniejący projekt jest gotowy do dalszej pracy z Liquibase.
Podsumowując to, co zrobiliśmy:
Jeśli chodzi o GIT:
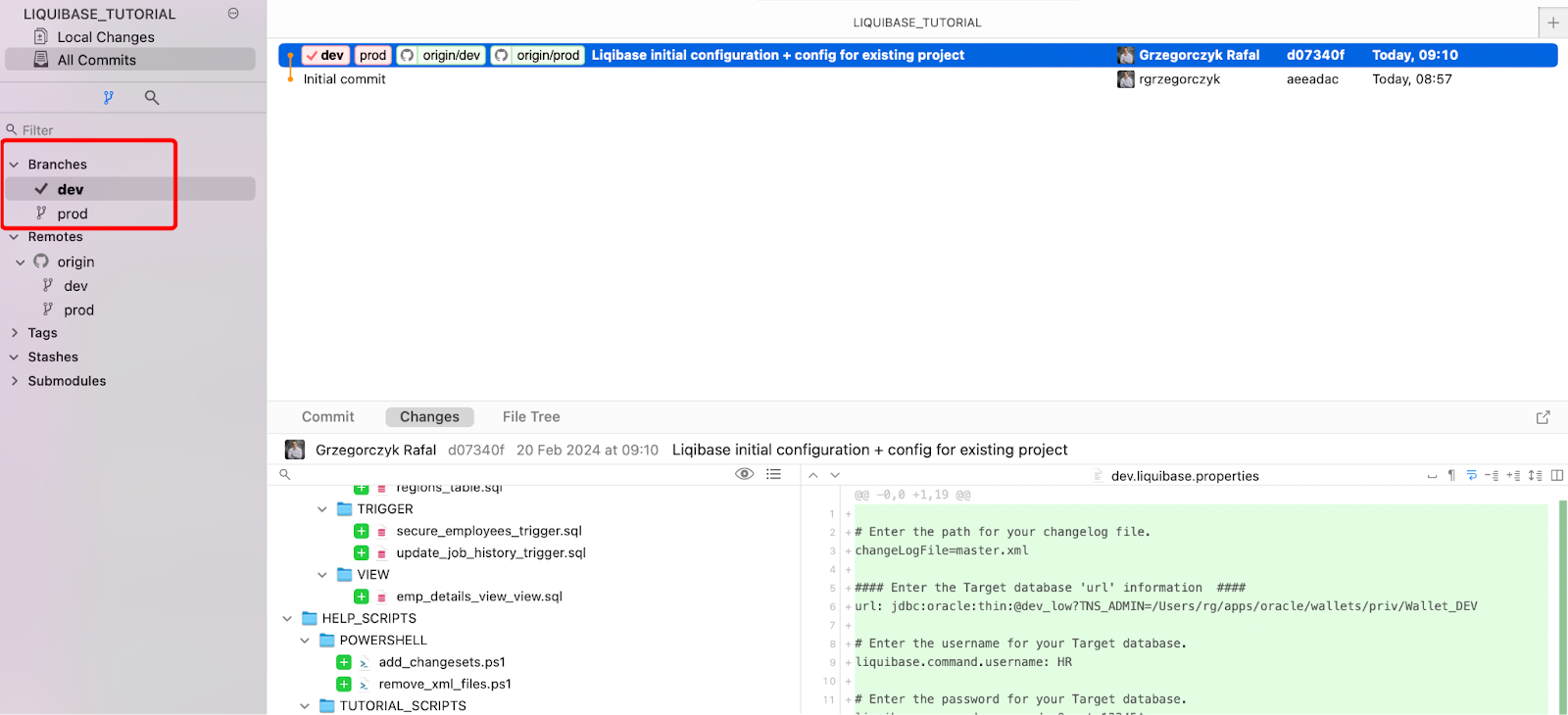
Dobrze, masz już repozytorium GIT i bazę danych skonfigurowaną do użytku z Liquibase. Od teraz wszystkie zmiany w bazie danych będą śledzone.
Z tego powodu NIE POWINIENEŚ zmieniać żadnego z obiektów bazy danych bezpośrednio w bazie (czy to przez SQLcl, SQL Developer czy jakiekolwiek inne narzędzie). Każda zmiana powinna odbywać się poprzez zmianę w pliku SQL w Twoim repozytorium i wykonanie odpowiedniego polecenia Liquibase.
W następnej części tego poradnika dokonam różnych zmian w mojej bazie danych, aby pokazać, jak tworzyć changesety i pisać odpowiednią składnię. Wszystkie pliki i zmiany, które wprowadzę, są dostępne w publicznym repozytorium stworzonym na potrzeby tego poradnika.
Wszystkie zmiany będą najpierw tworzone i wykonywane w bazie danych DEV . Po udanych testach zmiany zostaną wprowadzone na PROD.
Szybkie przypomnienie: changeset to typ zmiany w bazie danych, np. utworzenie tabeli, modyfikacja tabeli, utworzenie paczki itp.
Do wdrażania zmian będę używać polecenia UPDATE . Bardzo dobrą praktyką jest określanie tylko jednego typu zmiany na changeset. Pozwala to uniknąć sytuacji, w których instrukcje auto-commit pozostawiają bazę danych w nieoczekiwanym stanie. Podczas uruchamiania polecenia UPDATE każdy changeset albo kończy się sukcesem, albo niepowodzeniem. Jeśli się nie powiedzie, możesz go łatwo naprawić i wdrożyć ponownie. Powinieneś także dodawać komentarze do swoich changesetów, aby wyjaśnić ich znaczenie.
Ale najpierw zdefiniujmy, co naprawdę robi polecenie UPDATE . Wdraża ono wszelkie zmiany w pliku changelog, które nie zostały jeszcze wdrożone w Twojej bazie danych.
Warto wspomnieć, że Liquibase nie sprawdza niczego w obiektach bazy danych. Nie sprawdzi, czy tabela, kolumna lub paczka istnieją. Nie sprawdzi, jaka wersja obiektu znajduje się w bazie danych. Jeśli jednak spróbujesz utworzyć tabelę, która istnieje, Oracle zgłosi błąd podczas wykonywania Liquibase. Skąd więc Liquibase wie, co powinno zostać wdrożone?
Kiedy uruchamiasz polecenie UPDATE , Liquibase sekwencyjnie odczytuje changesety w pliku changelog, a następnie porównuje unikalne identyfikatory – id, autor (author) i ścieżkę pliku – z wartościami w tabeli DATABASECHANGELOG . Istnieją co najmniej 3 możliwe scenariusze, które mogą wystąpić po uruchomieniu polecenia UPDATE :
Jeśli dodasz to do istniejącego changesetu, zakończy się on niepowodzeniem:
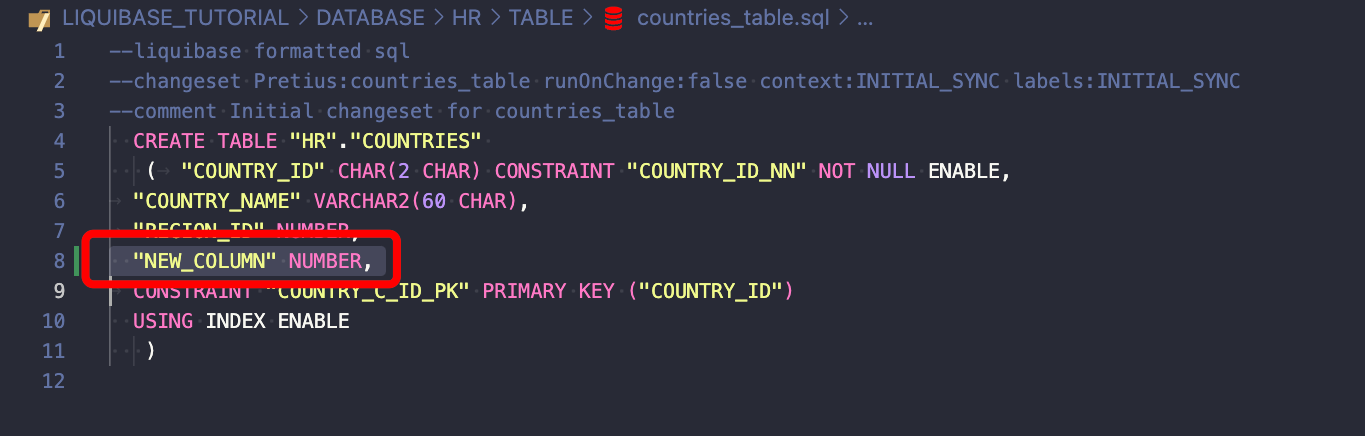
To jest w porządku:
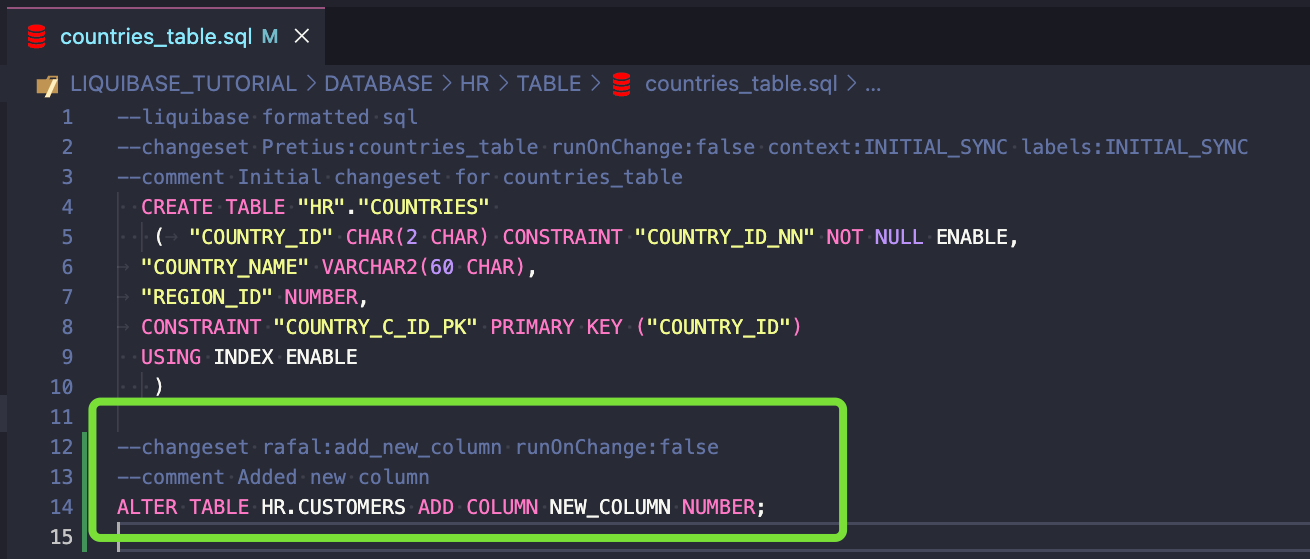
Jeśli jednak runOnChange jest ustawione na TRUE, Liquibase ponownie zastosuje changeset.
Pamiętaj, że ten parametr powinien być ustawiony na TRUE tylko dla obiektów, które można zastąpić (replace), takich jak widoki, paczki, procedury, funkcje itp.
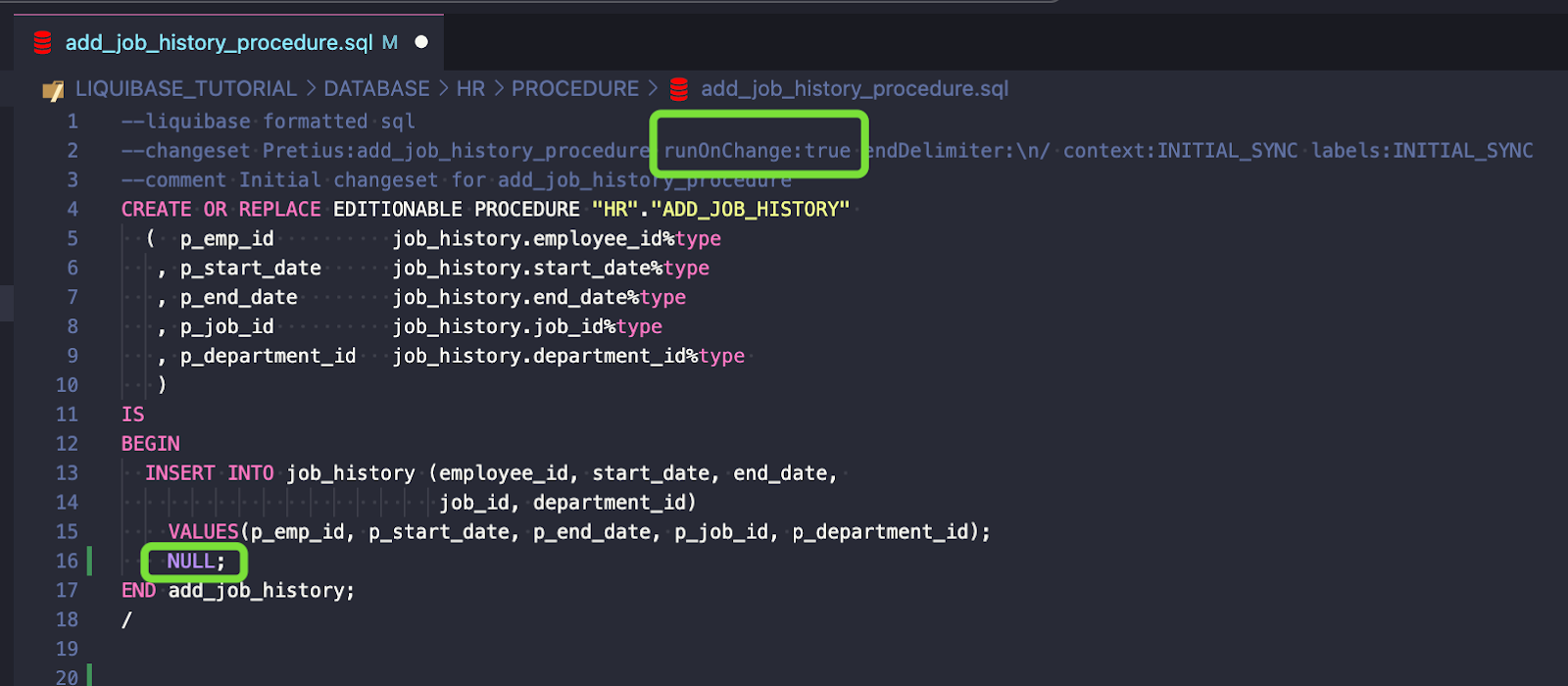
Teraz zacznijmy wprowadzać i śledzić zmiany w naszej bazie danych. Aby zachować prostotę, określę wymagania i kroki, które należy wykonać, aby wdrożyć każde z nich.
Moje przykłady pokażą zmiany wprowadzone przez dwóch programistów, RAFAŁA oraz JANA, którzy pracują z tą samą bazą danych DEV . Korzystają oni również z GIT i Visual Studio Code.
ŻADNE ZMIANY nie są wprowadzane bezpośrednio w bazie danych. Wszystko musi przechodzić przez pliki SQL i Liquibase.
Jest to zasada pisana czerwoną czcionką, której muszą przestrzegać wszyscy programiści. W przeciwnym razie używanie Liquibase nie ma sensu.
Teraz przejdźmy przez niezbędne kroki.
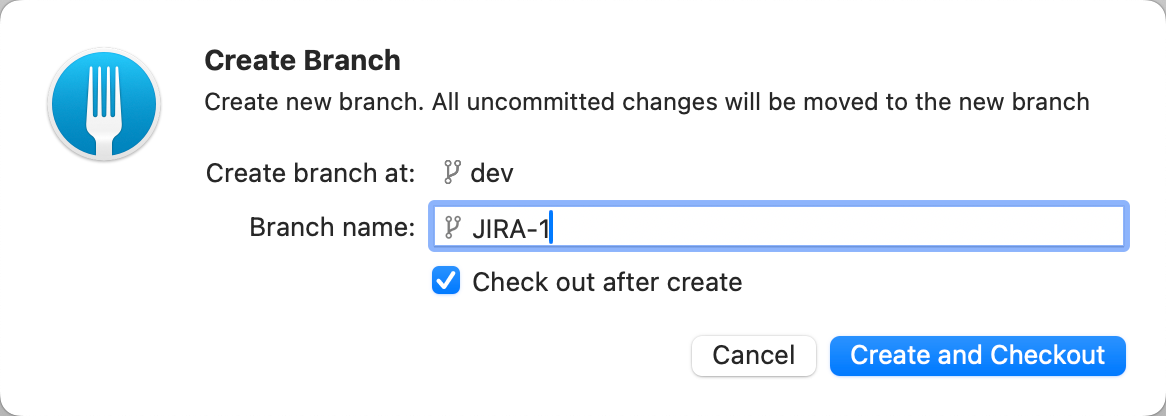
Kroki:
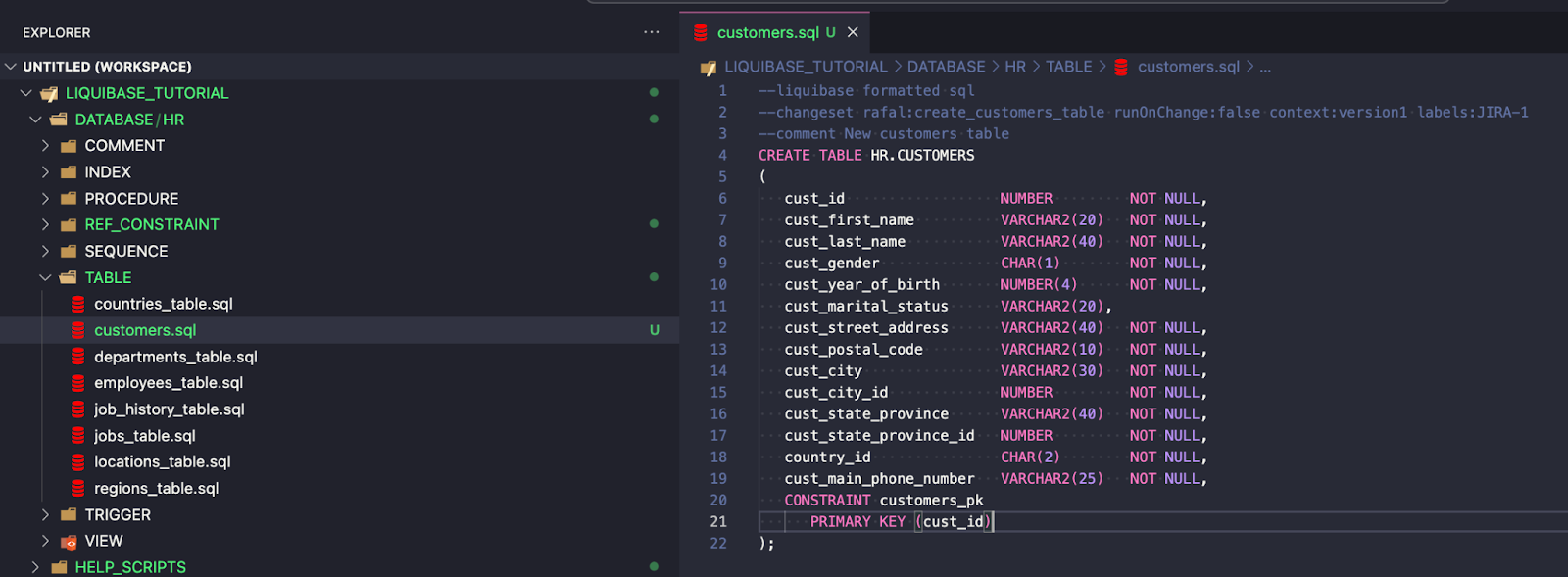
Legenda:
--liquibase formatted sql --changeset rafal:create_customers_table runOnChange:false context:version1 labels:JIRA-1 --comment New customers table CREATE TABLE HR.CUSTOMERS ( cust_id NUMBER NOT NULL, cust_first_name VARCHAR2(20) NOT NULL, cust_last_name VARCHAR2(40) NOT NULL, cust_gender CHAR(1) NOT NULL, cust_year_of_birth NUMBER(4) NOT NULL, cust_marital_status VARCHAR2(20), cust_street_address VARCHAR2(40) NOT NULL, cust_postal_code VARCHAR2(10) NOT NULL, cust_city VARCHAR2(30) NOT NULL, cust_city_id NUMBER NOT NULL, cust_state_province VARCHAR2(40) NOT NULL, cust_state_province_id NUMBER NOT NULL, country_id CHAR(2) NOT NULL, cust_main_phone_number VARCHAR2(25) NOT NULL, CONSTRAINT customers_pk PRIMARY KEY (cust_id) );
Kroki:

--liquibase formatted sql --changeset rafal:customers_country_fk context:version1 labels:JIRA-1 --comment Foreign key customers ->countries alter table customers add CONSTRAINT customers_country_fk FOREIGN KEY (country_id) REFERENCES countries (country_id);
Dla jasności: obecnie ani tabela CUSTOMERS , ani foreign key nie istnieją w mojej bazie danych DEV . To tylko kod w moich plikach SQL. Muszę użyć polecenia Liquibase UPDATE wyjaśnionego wcześniej, aby wdrożyć zmiany.
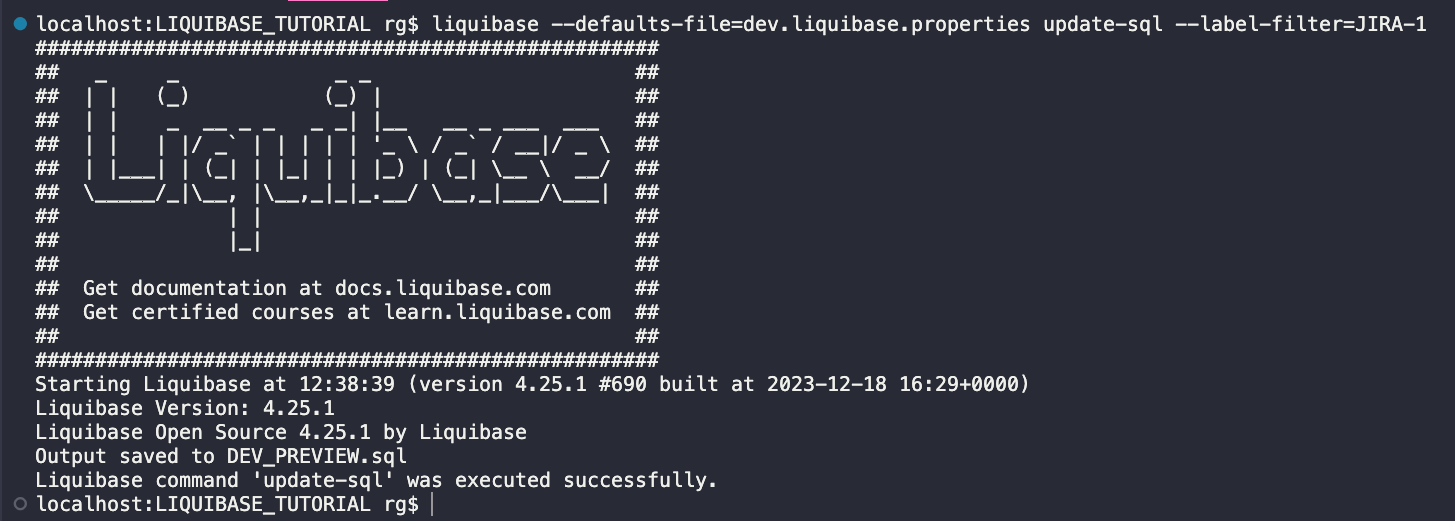
Jednak przed wykonaniem polecenia UPDATE , wysoce zalecane jest najpierw uruchomienie polecenia UPDATE-SQL. Wygeneruje plik SQL, który pokaże, co zostałoby wykonane, gdybyś później uruchomił polecenie UPDATE .
liquibase --defaults-file=dev.liquibase.properties update-sql --label-filter=JIRA-1
Legenda:
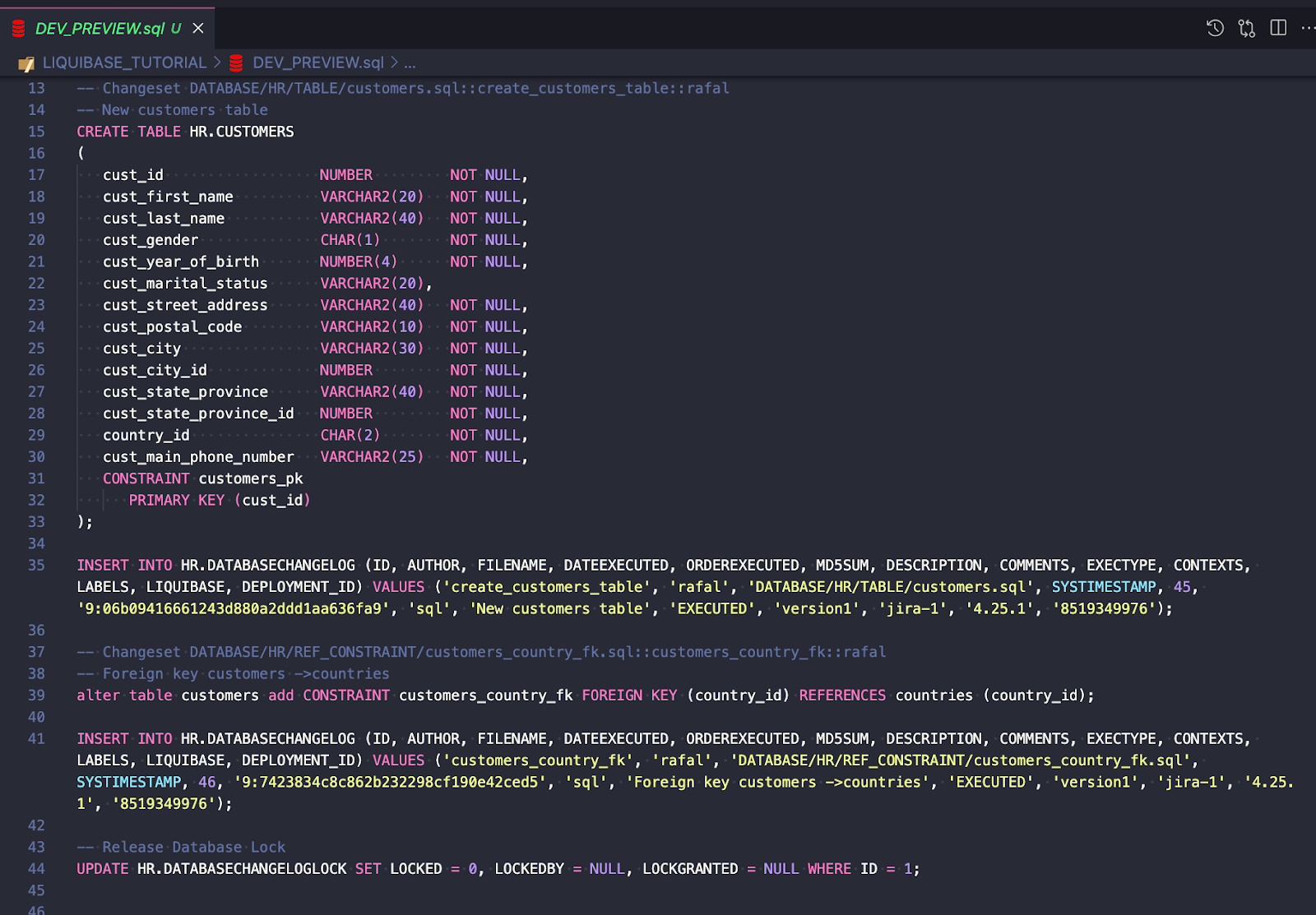
Skrypt wygląda dobrze (pełny skrypt jest dostępny tutaj), więc jestem gotowy do wdrożenia moich zmian za pomocą polecenia UPDATE .
liquibase --defaults-file=dev.liquibase.properties update --label-filter=JIRA-1
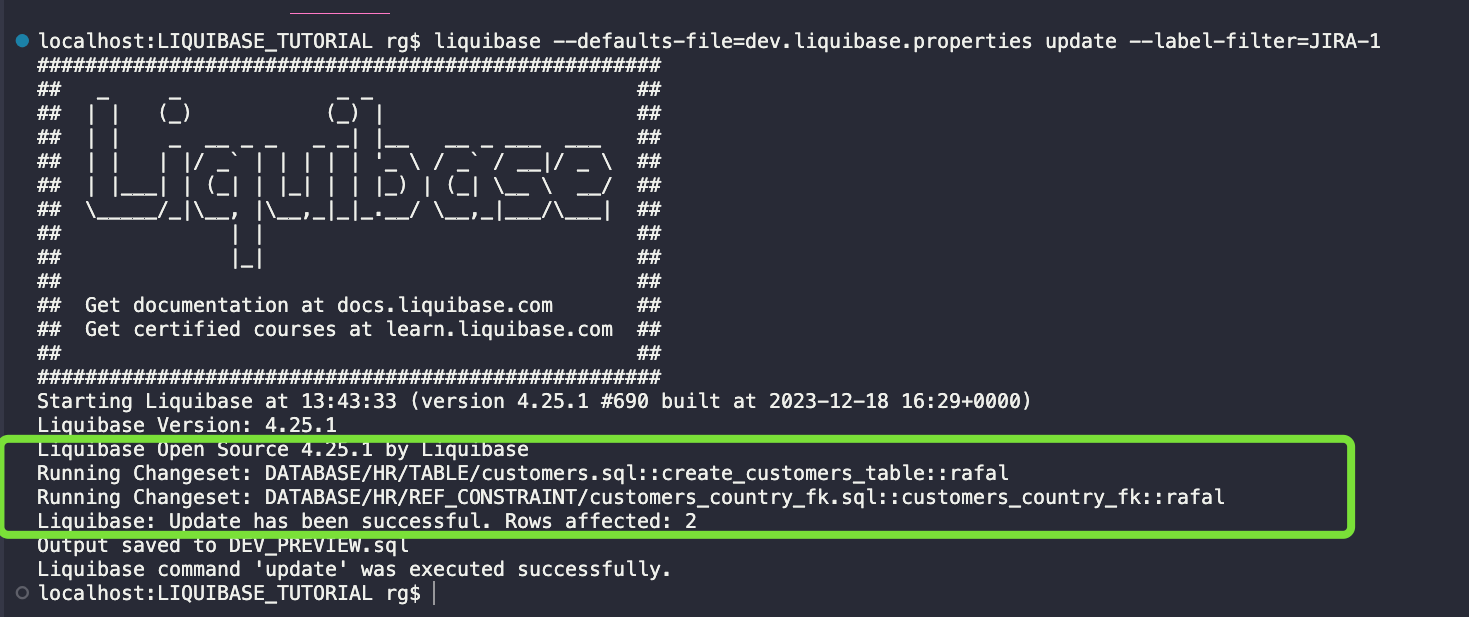
Ciekawa informacja w pliku DEV_PREVIEW.sql.
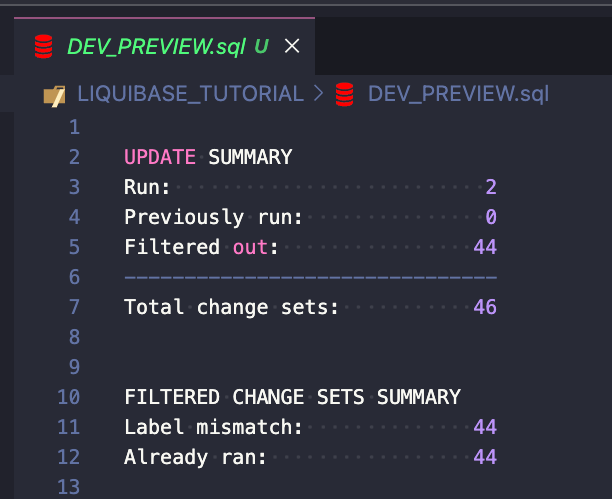
I dwa nowe wiersze zostały wstawione do tabeli DATABASECHANGELOG:

Są też dwie nowe kolumny:

Moje zmiany dotyczące zadania JIRA-1 zostały pomyślnie wdrożone w bazie danych DEV . Mogę zmergować moje zmiany do gałęzi DEV .
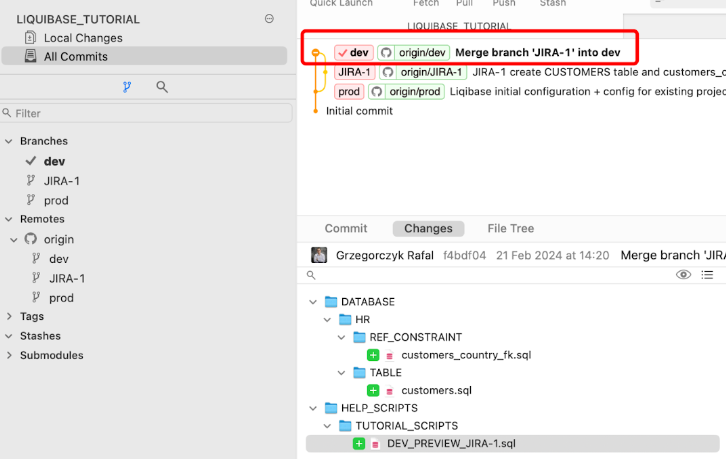
Przejdźmy przez kroki.
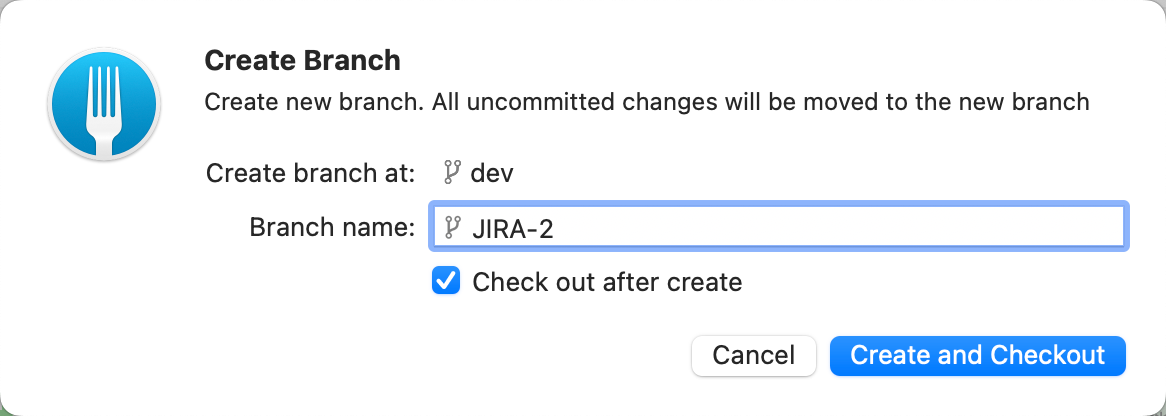
Kroki:
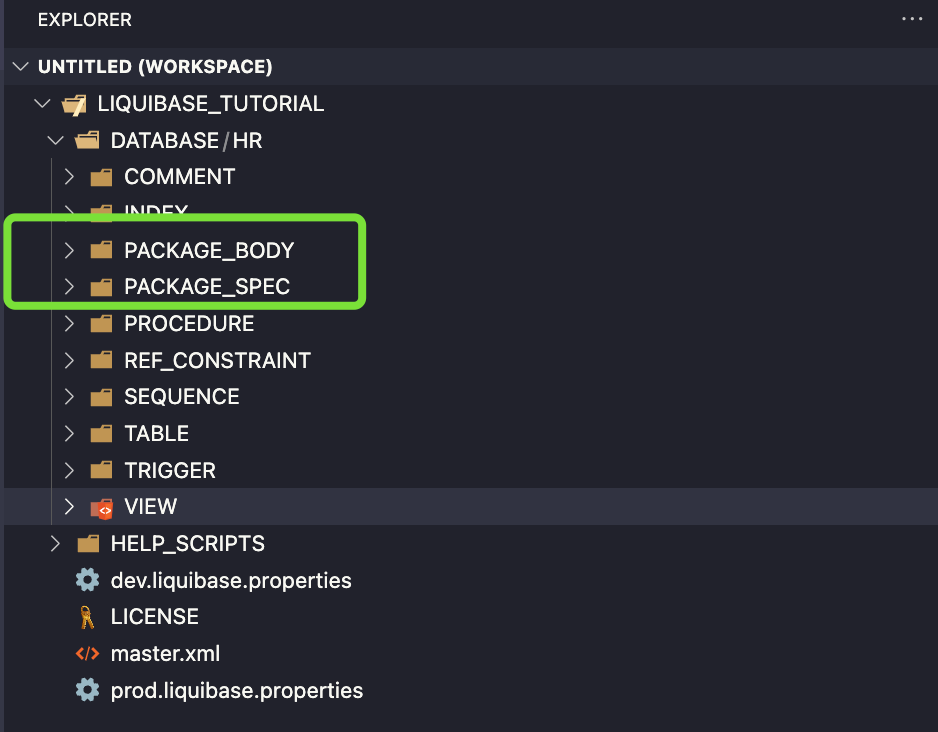
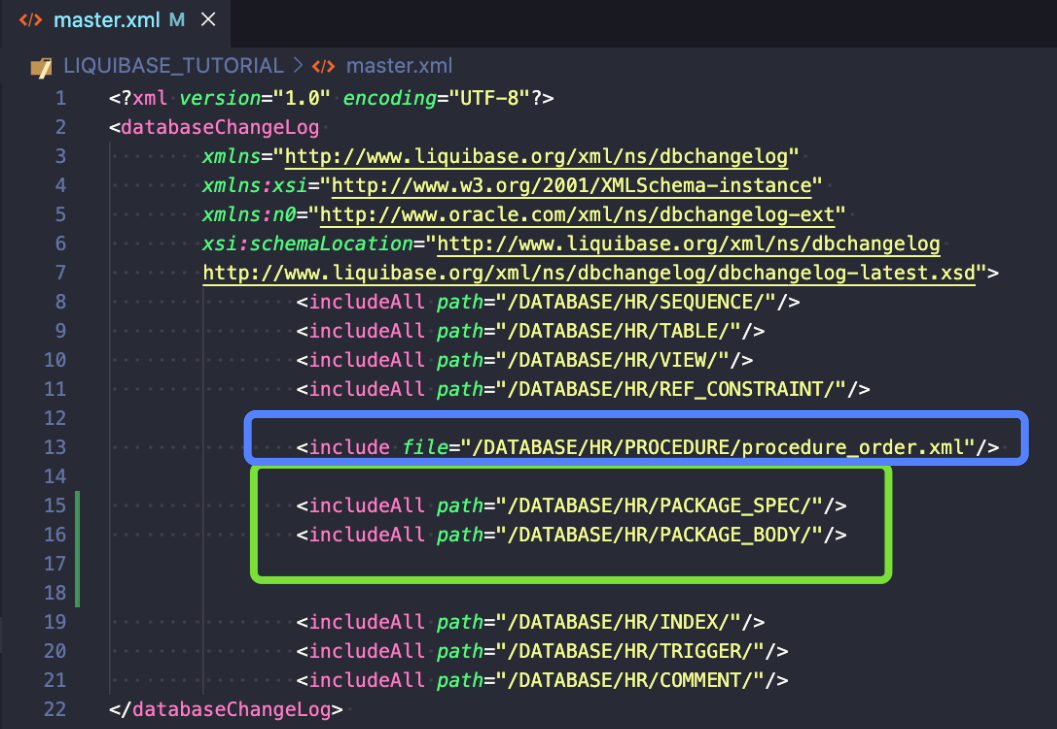
Użyłem includeAll co oznacza, że wszystkie pliki SQL utworzone w tych folderach zostaną wykonane alfabetycznie. Jeśli chcesz mieć większą kontrolę, użyj tagu include file, tak jak zrobiłem to w linii powyżej (niebieska ramka).
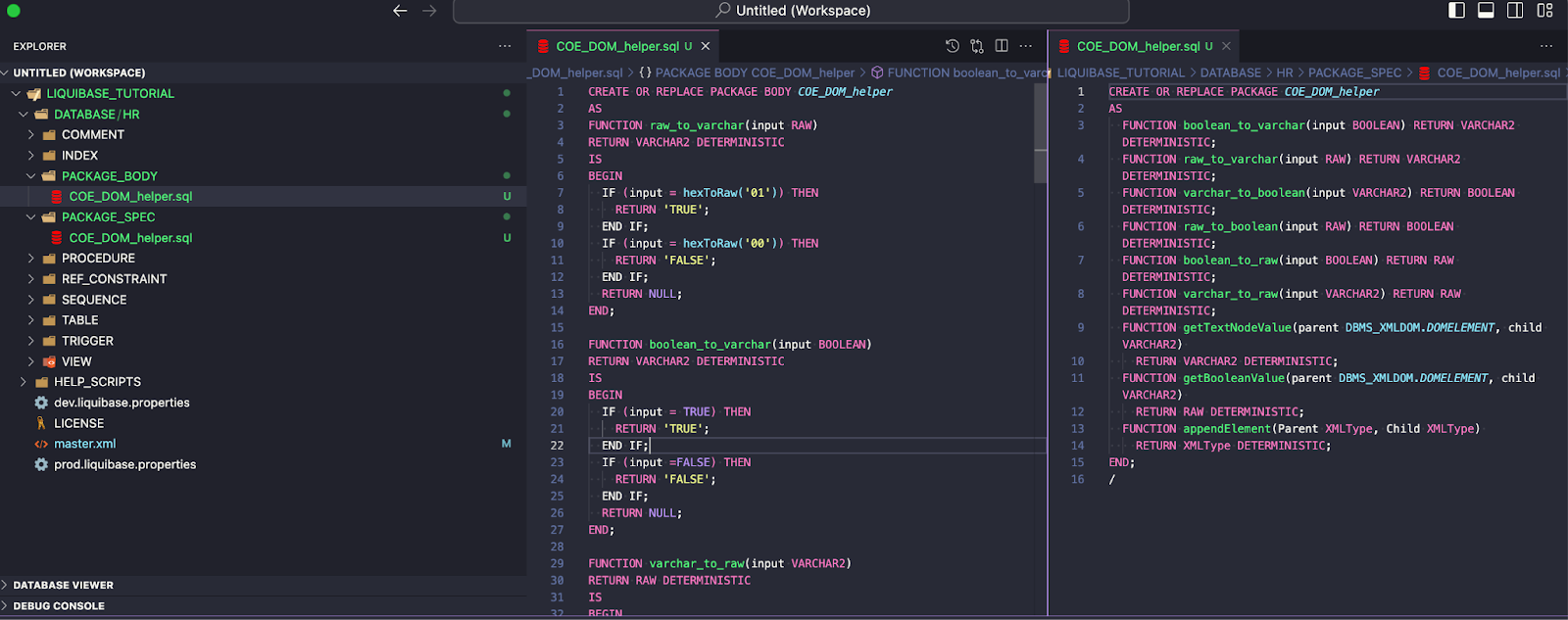
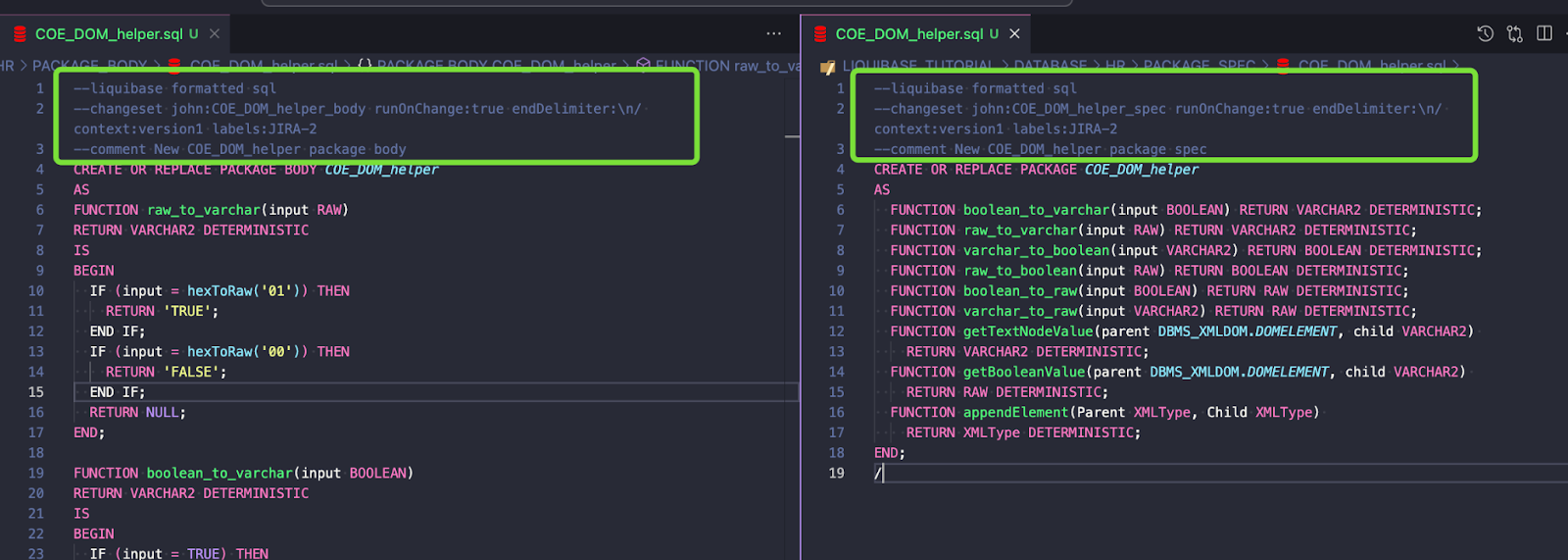
Linie do dodania do ciała paczki:
--liquibase formatted sql --changeset john:COE_DOM_helper_body runOnChange:true endDelimiter:\n/ context:version1 labels:JIRA-2 --comment New COE_DOM_helper package body
Dodaj te linie do specyfikacji paczki:
--liquibase formatted sql --changeset john:COE_DOM_helper_spec runOnChange:true endDelimiter:\n/ context:version1 labels:JIRA-2 --comment New COE_DOM_helper package spec
Legenda:
Kroki:
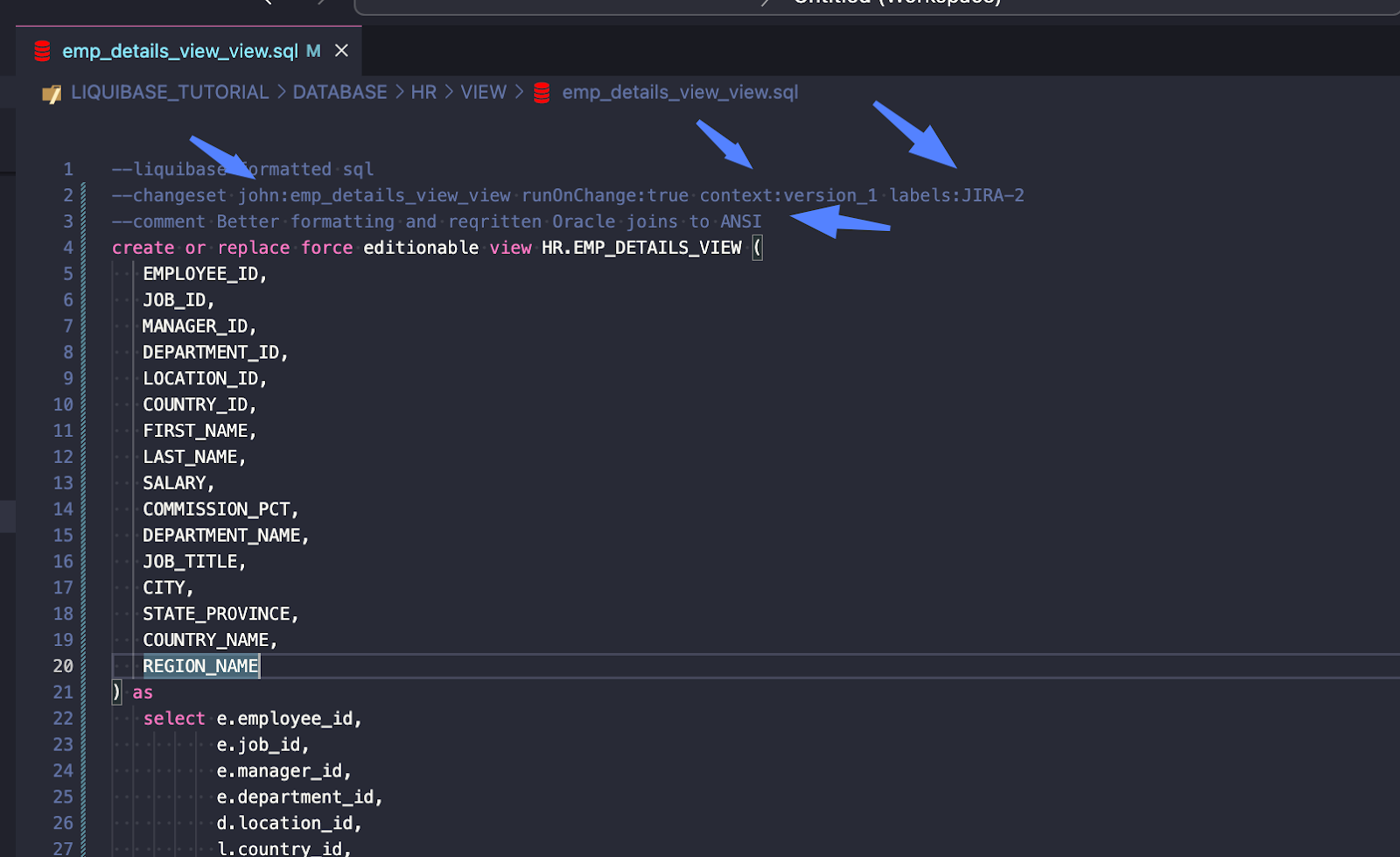
Podgląd tego, co zostanie wdrożone za pomocą tego polecenia:
liquibase --defaults-file=dev.liquibase.properties update-sql --label-filter=JIRA-2
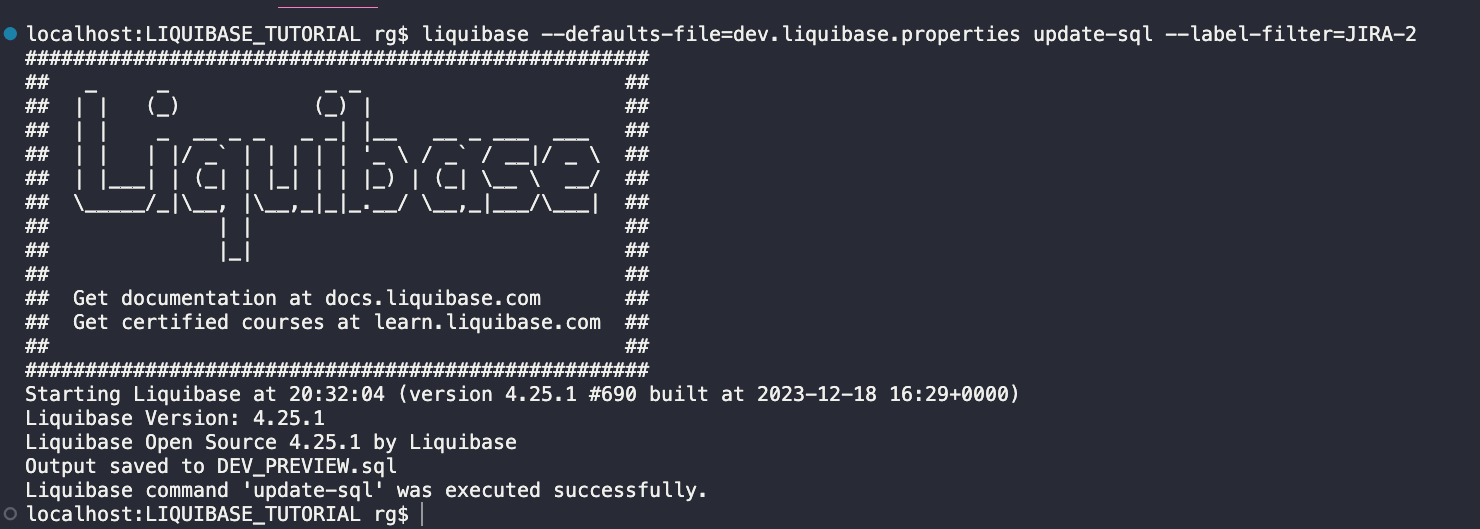
Wygląda dobrze (podgląd całego pliku tutaj).
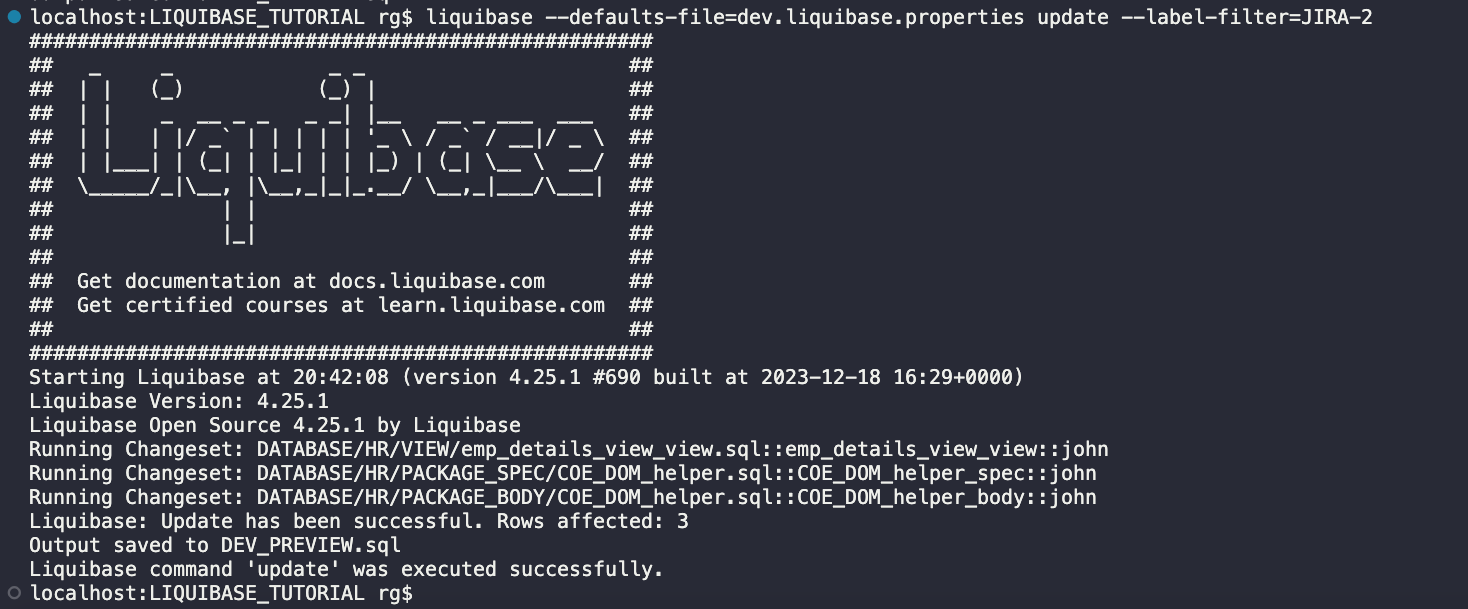
Wykonaj polecenie Liquibase UPDATE, aby wdrożyć te 3 nowe zmiany:
liquibase --defaults-file=dev.liquibase.properties update --label-filter=JIRA-2
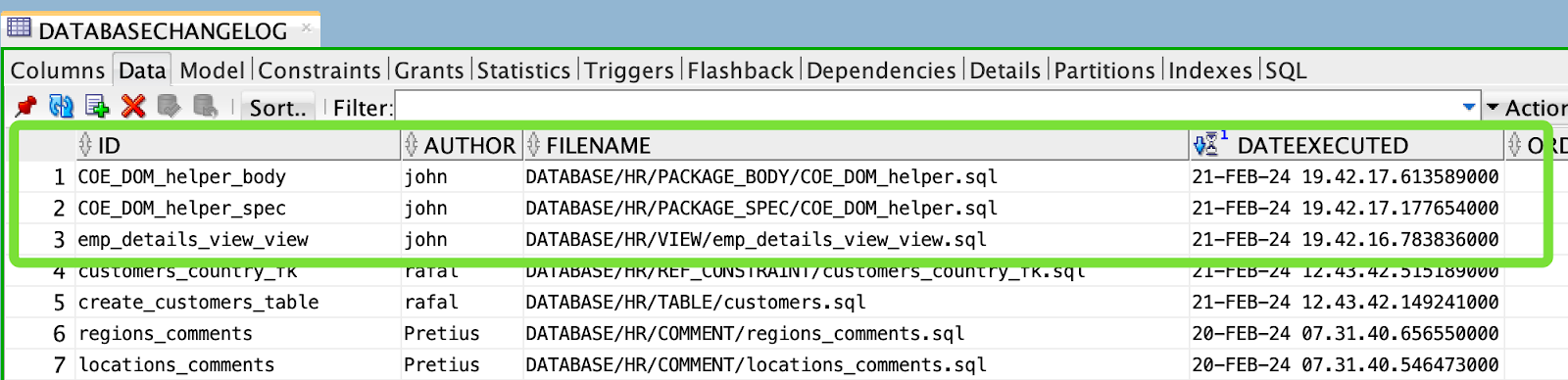
Zmiany zostały wdrożone w mojej bazie danych DEV , a w tabeli DATABASECHANGELOG pojawiły się 3 nowe wiersze:
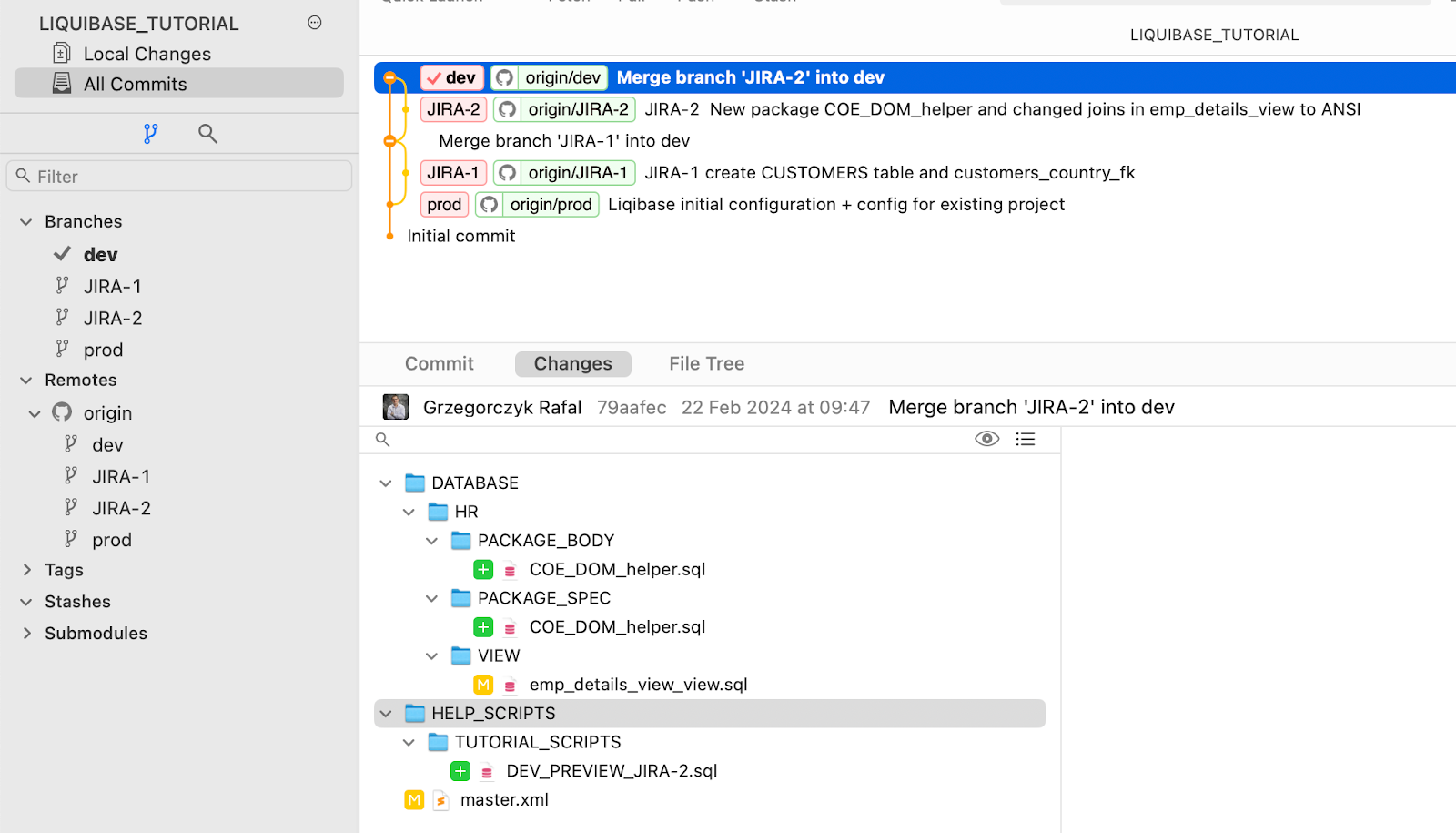
Kroki:
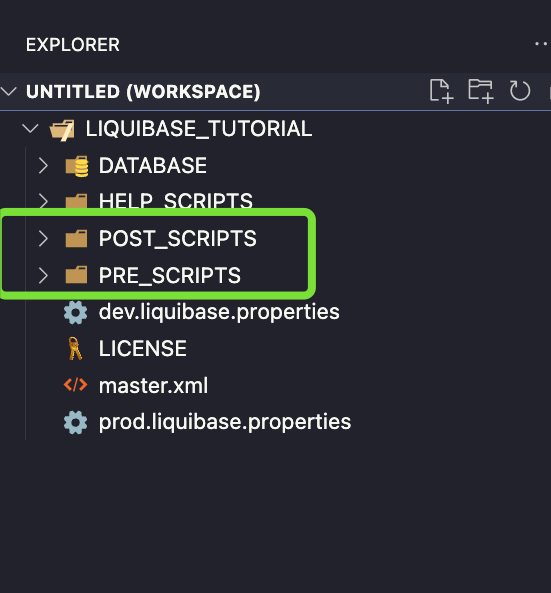
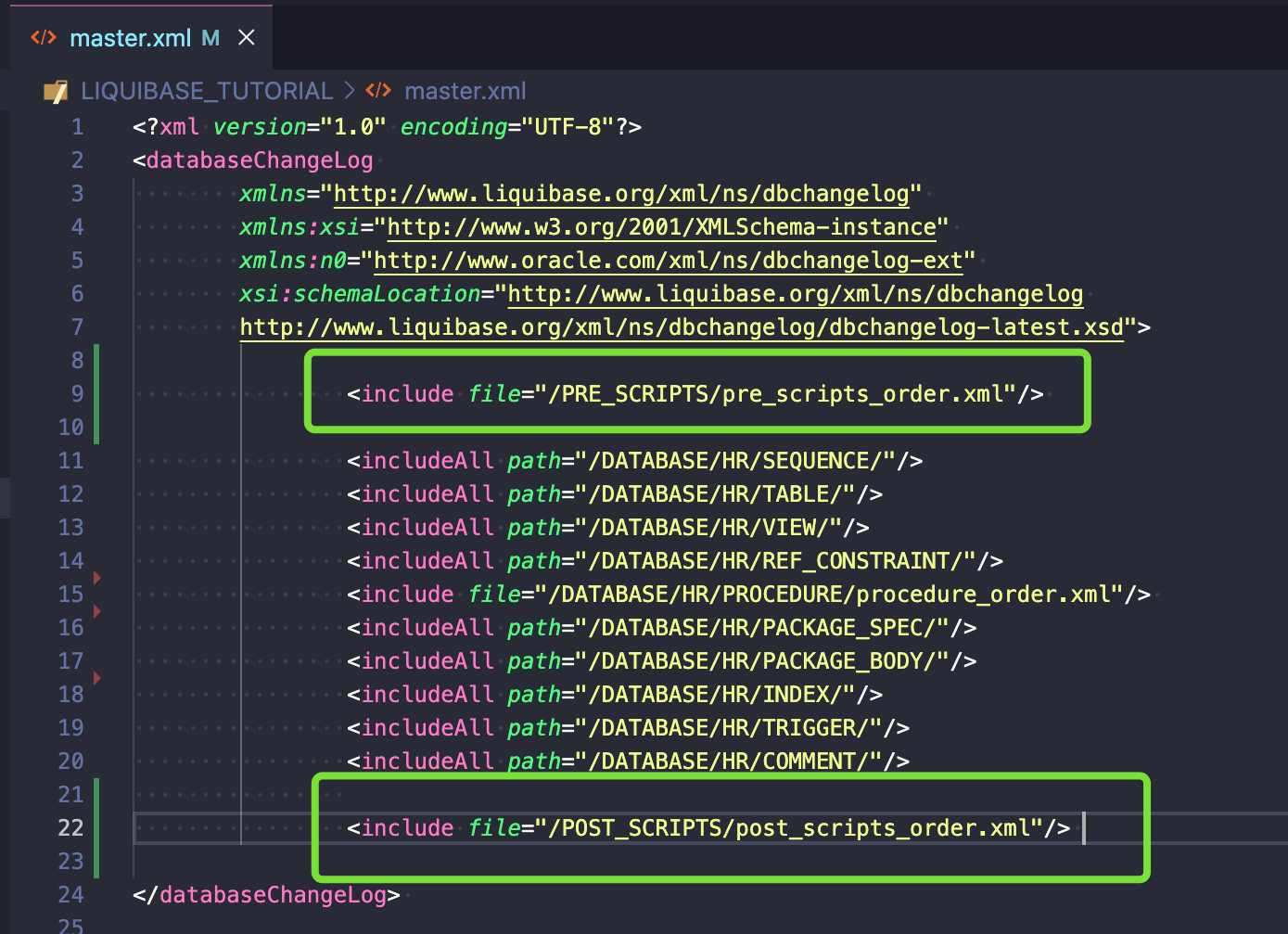
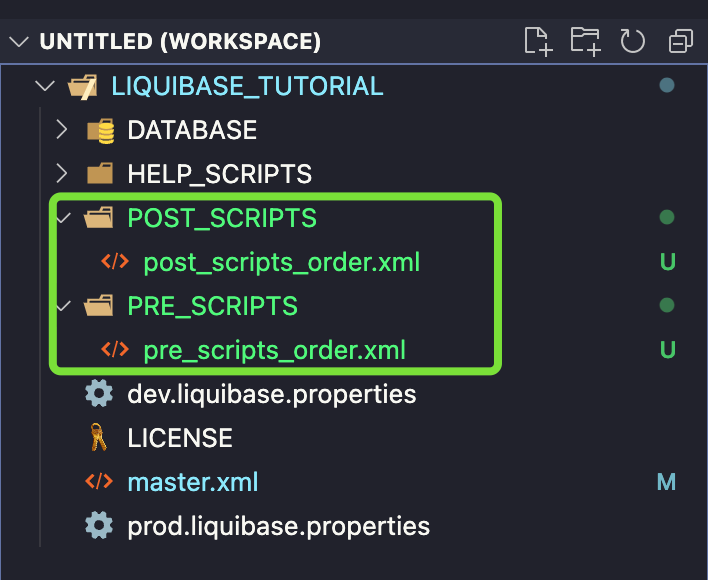
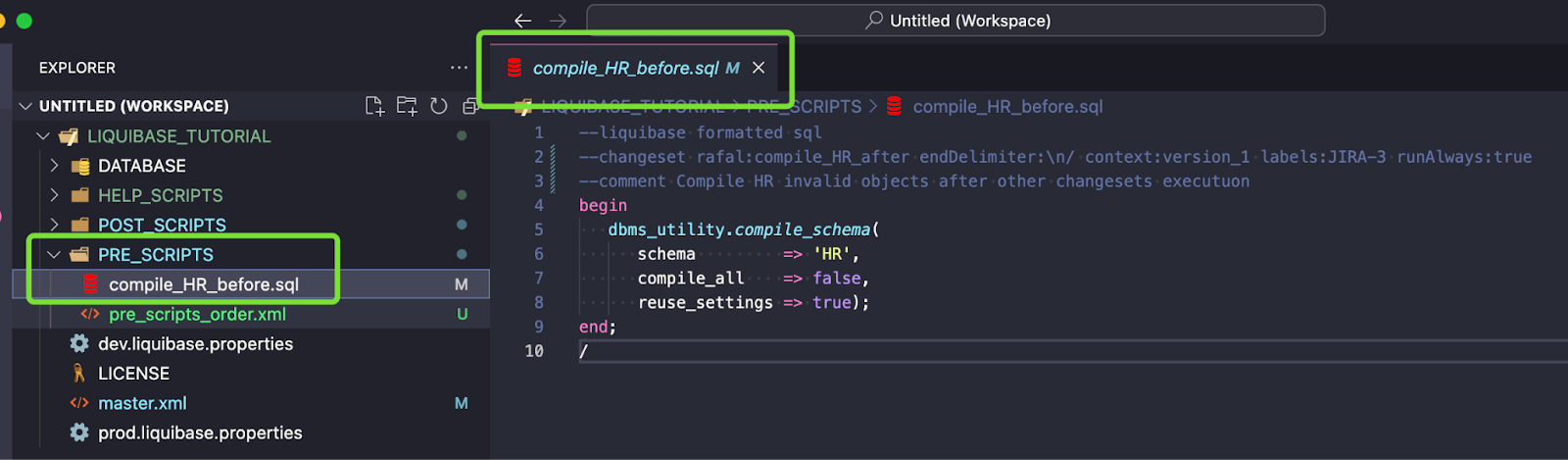
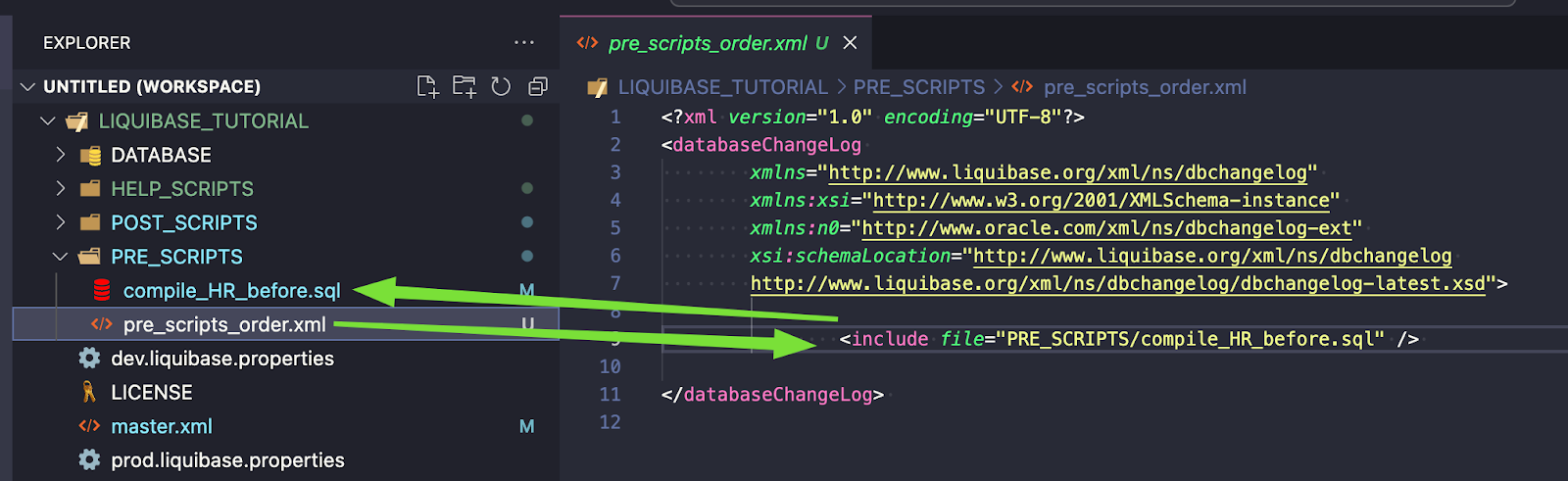
Pełny kod changesetu:
--liquibase formatted sql --changeset rafal:compile_HR_after endDelimiter:\n/ context:version_1 labels:JIRA-3 runAlways:true --comment Compile HR invalid objects after other changesets executuon begin dbms_utility.compile_schema( schema => 'HR', compile_all => false, reuse_settings => true); end; /
W powyższej składni pojawia się coś nowego – runAlways:true. Dzięki temu parametrowi Liquibase wykona ten changeset za każdym razem, gdy uruchomisz polecenie UPDATE .
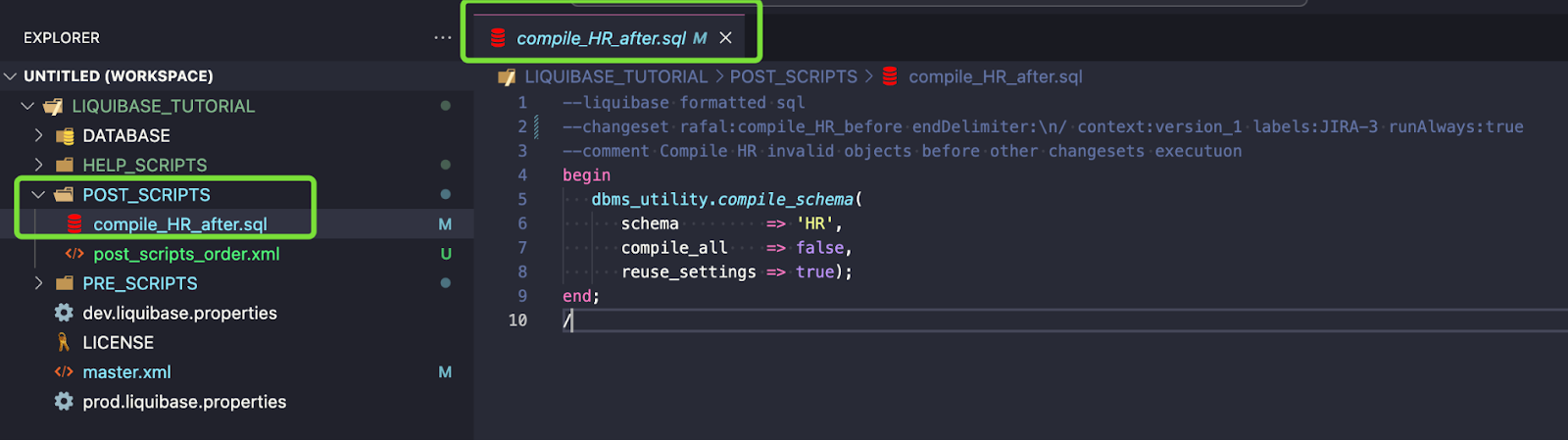
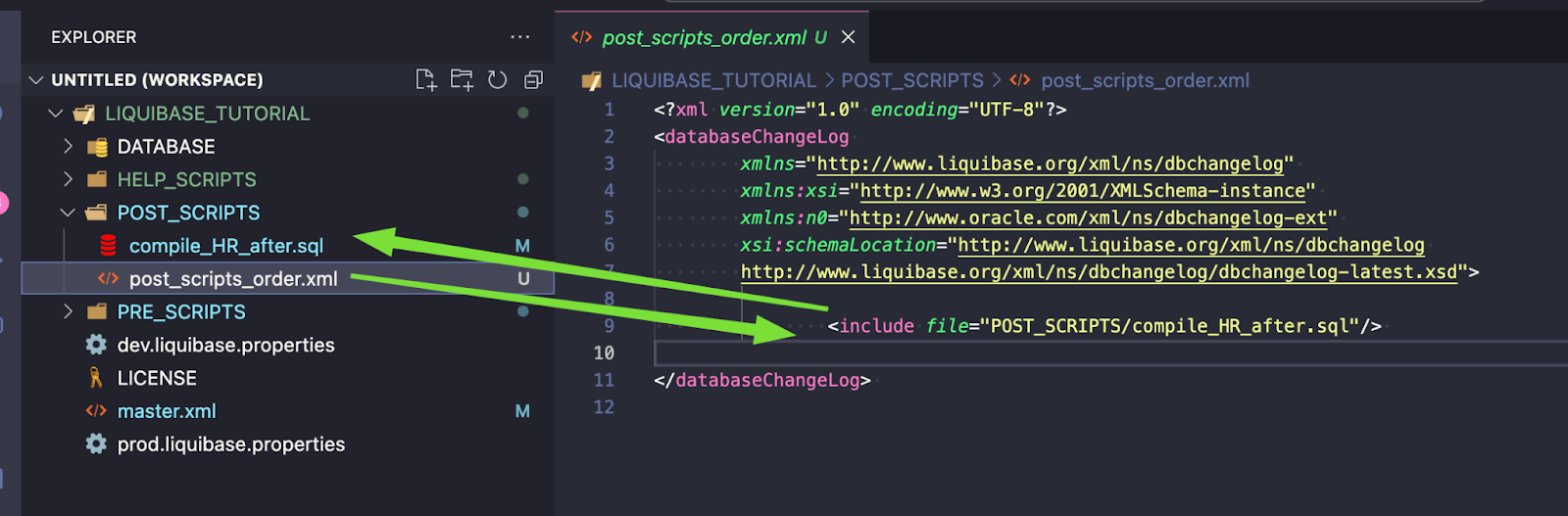
Pełny kod changesetu:
--liquibase formatted sql --changeset rafal:compile_HR_before endDelimiter:\n/ context:version_1 labels:JIRA-3 runAlways:true --comment Compile HR invalid objects before other changesets executuon begin dbms_utility.compile_schema( schema => 'HR', compile_all => false, reuse_settings => true); end; /
Kroki:
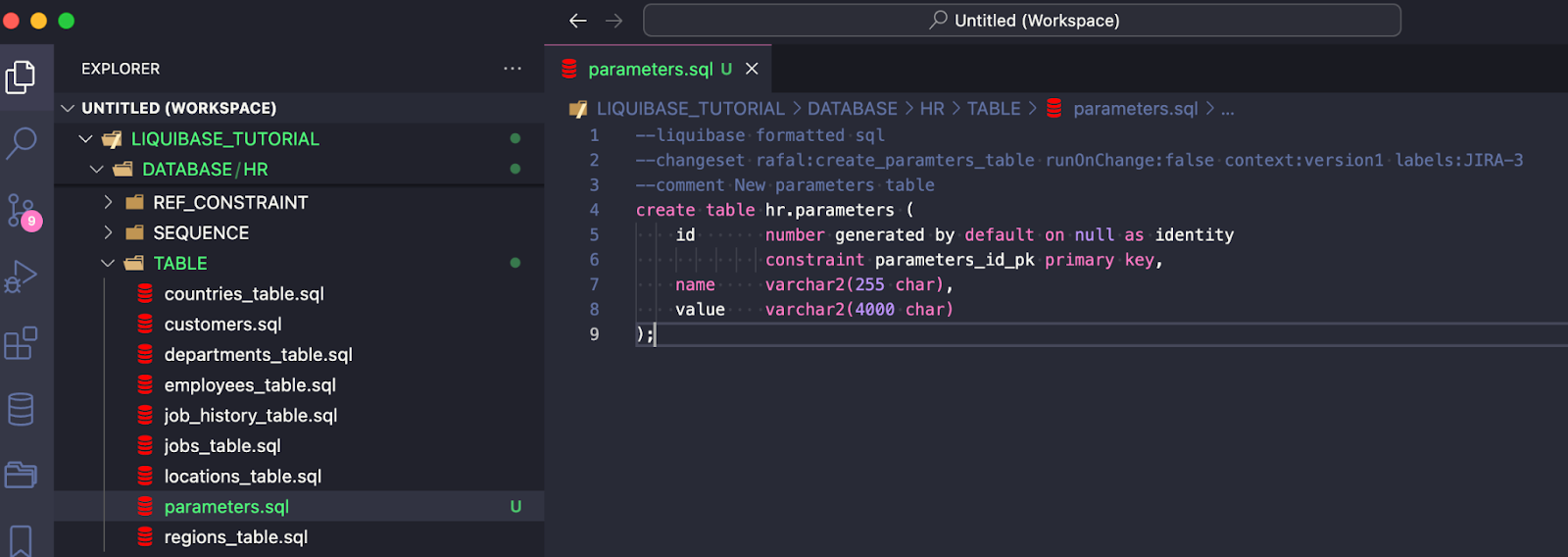
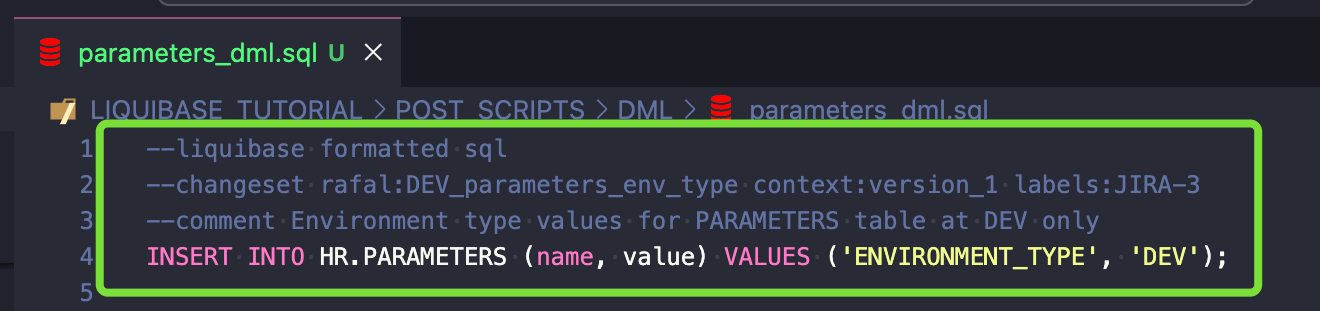
--liquibase formatted sql --changeset rafal:create_paramters_table runOnChange:false context:version1 labels:JIRA-3 --comment New parameters table create table hr.parameters ( id number generated by default on null as identity constraint parameters_id_pk primary key, name varchar2(255 char), value varchar2(4000 char) );
Kroki:
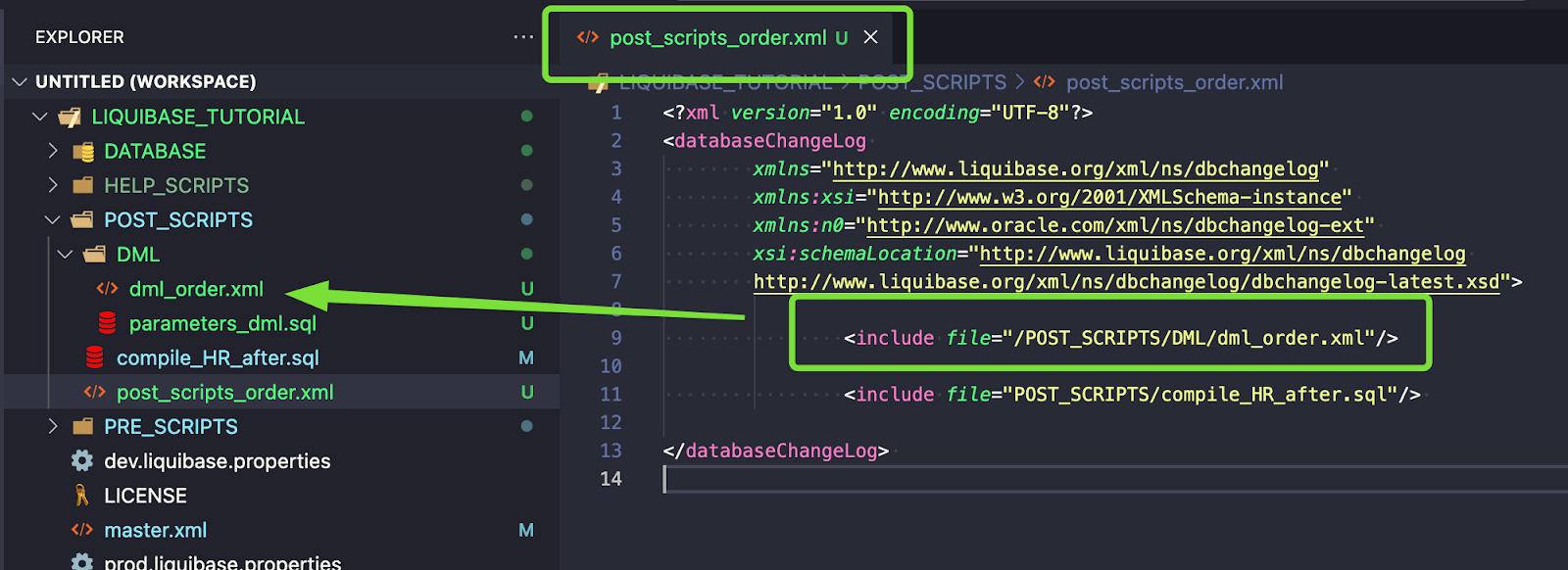
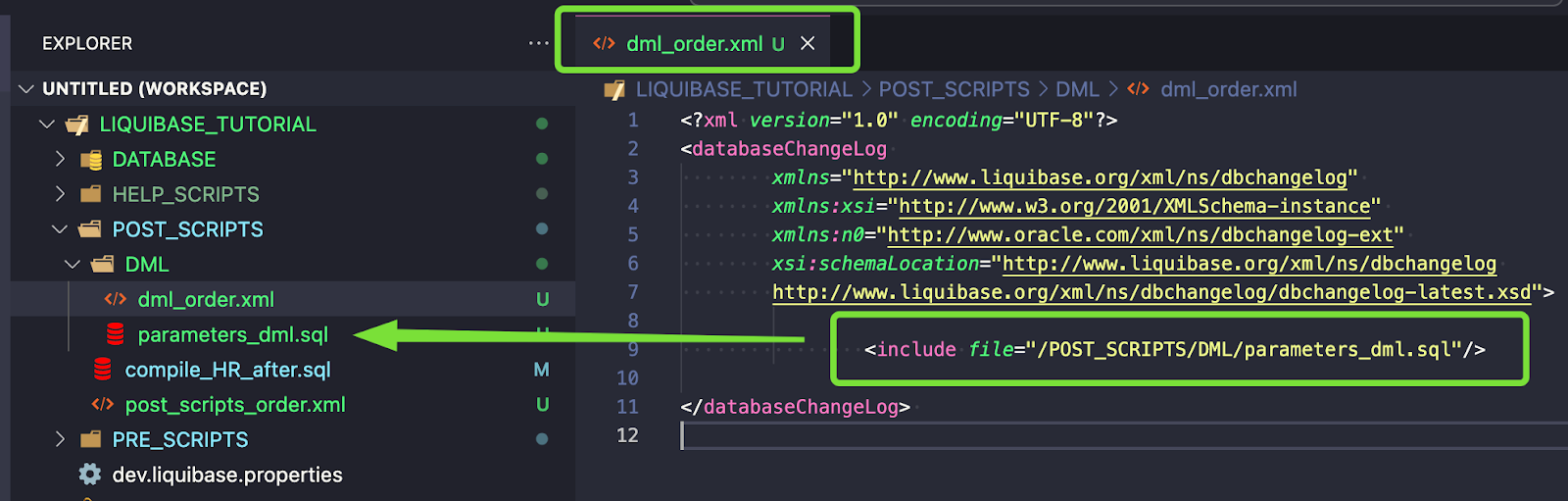
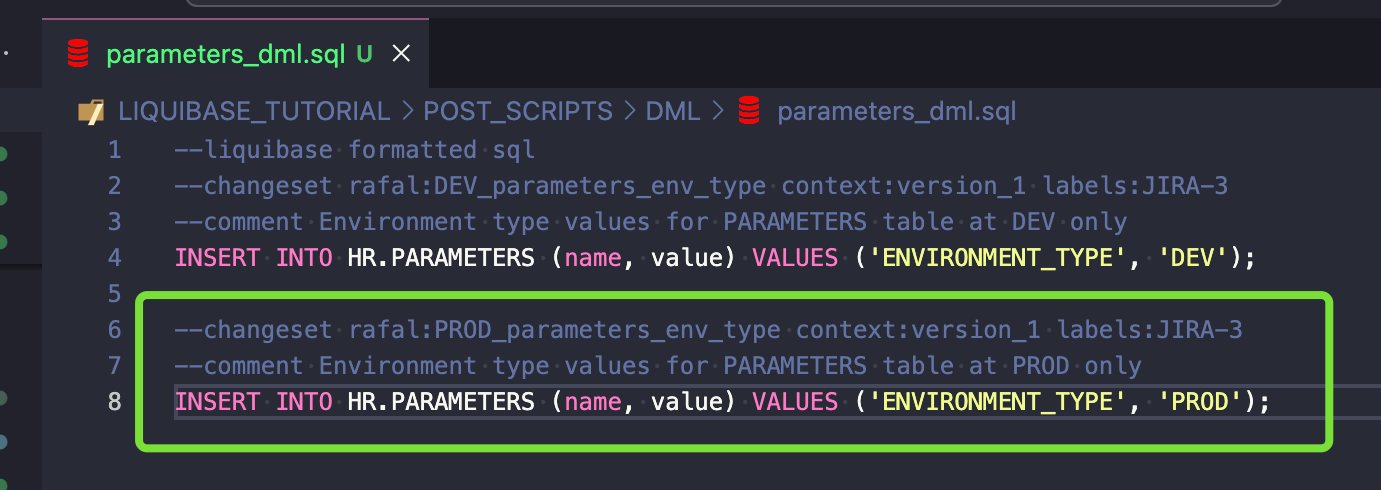
Jednak to nie wystarczy, ponieważ tak zdefiniowane changesety zostaną wykonane w każdym środowisku. Będziesz musiał użyć Liquibase preConditions.
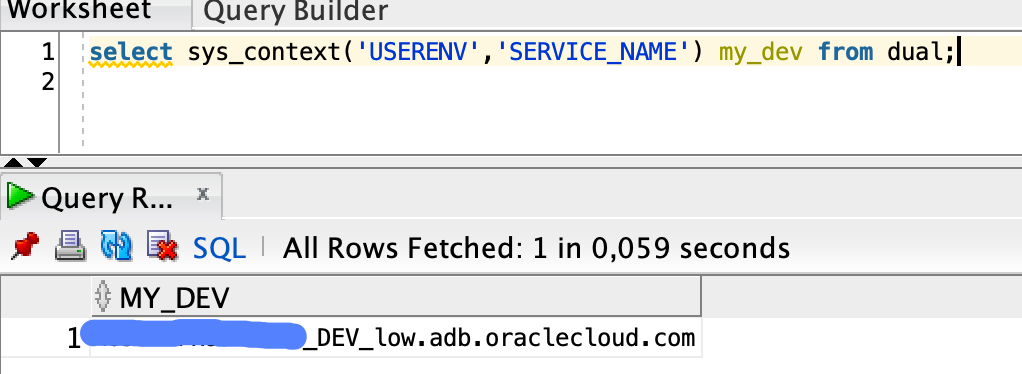
Skąd będziesz wiedzieć, czy Twoja baza danych Autonomous to DEV czy PROD? Twój parametr service_name będzie zawierał wartość DEV lub PROD . To zapytanie powinno wystarczyć:
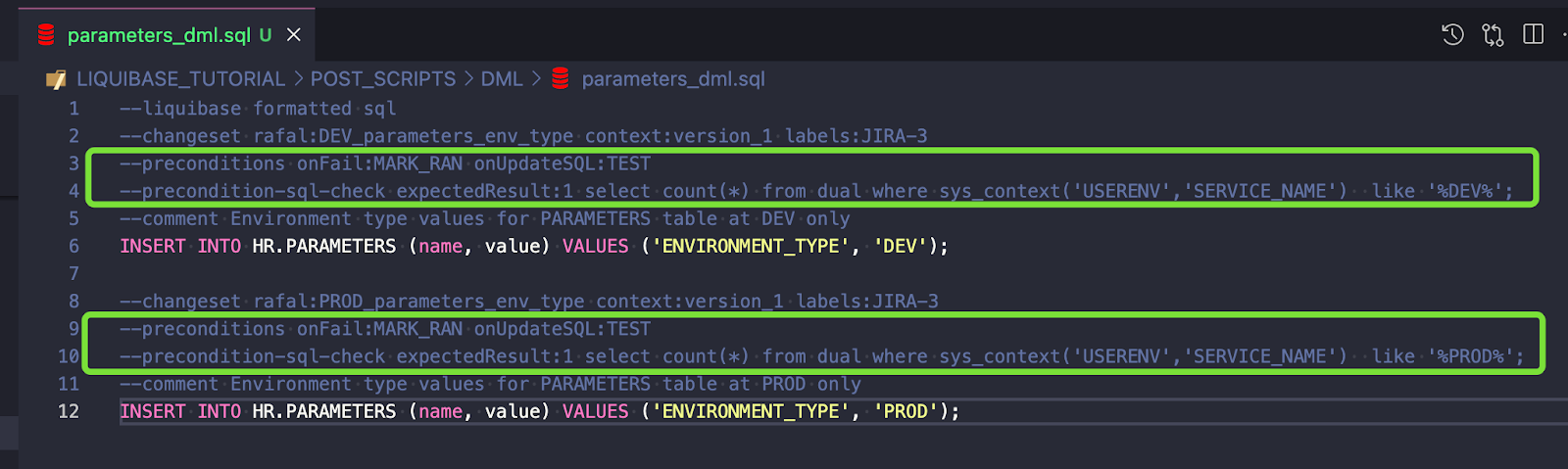
Zmiany są przygotowane. Uruchom UPDATE-SQL, aby sprawdzić, co zostanie wykonane na DEV:
liquibase --defaults-file=dev.liquibase.properties update-sql --label-filter=JIRA-3
Mój skrypt podglądu znajduje się poniżej oraz w repozytorium tutaj, i wszystko jest tak, jak oczekiwałem. Co się wydarzy:
Skrypt podglądu:
-- Lock Database
UPDATE HR.DATABASECHANGELOGLOCK SET LOCKED = 1, LOCKEDBY = 'localhost (192.168.0.2)', LOCKGRANTED = SYSTIMESTAMP WHERE ID = 1 AND LOCKED = 0;
-- *********************************************************************
-- Update Database Script
-- *********************************************************************
-- Change Log: master.xml
-- Ran at: 22.02.2024, 15:08
-- Against: HR@jdbc:oracle:thin:@dev_low
-- Liquibase version: 4.25.1
-- *********************************************************************
-- Changeset PRE_SCRIPTS/compile_HR_before.sql::compile_HR_after::rafal
-- Compile HR invalid objects after other changesets executuon
begin
dbms_utility.compile_schema(
schema => 'HR',
compile_all => false,
reuse_settings => true);
end;
/
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('compile_HR_after', 'rafal', 'PRE_SCRIPTS/compile_HR_before.sql', SYSTIMESTAMP, 50, '9:84b226d042023ca9771041f4c887fd6a', 'sql', 'Compile HR invalid objects after other changesets executuon', 'EXECUTED', 'version_1', 'jira-3', '4.25.1', '8610923542');
-- Changeset DATABASE/HR/TABLE/parameters.sql::create_paramters_table::rafal
-- New parameters table
create table hr.parameters (
id number generated by default on null as identity
constraint parameters_id_pk primary key,
name varchar2(255 char),
value varchar2(4000 char)
);
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('create_paramters_table', 'rafal', 'DATABASE/HR/TABLE/parameters.sql', SYSTIMESTAMP, 51, '9:830a9f31b55e62c8fc4a3f8c2ee4e51c', 'sql', 'New parameters table', 'EXECUTED', 'version1', 'jira-3', '4.25.1', '8610923542');
-- Changeset POST_SCRIPTS/DML/parameters_dml.sql::DEV_parameters_env_type::rafal
-- Environment type values for PARAMETERS table at DEV only
INSERT INTO HR.PARAMETERS (name, value) VALUES ('ENVIRONMENT_TYPE', 'DEV');
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('DEV_parameters_env_type', 'rafal', 'POST_SCRIPTS/DML/parameters_dml.sql', SYSTIMESTAMP, 52, '9:d707b31273b18adf3fce32ddce9f1553', 'sql', 'Environment type values for PARAMETERS table at DEV only', 'EXECUTED', 'version_1', 'jira-3', '4.25.1', '8610923542');
-- Changeset POST_SCRIPTS/DML/parameters_dml.sql::PROD_parameters_env_type::rafal
-- Environment type values for PARAMETERS table at PROD only
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('PROD_parameters_env_type', 'rafal', 'POST_SCRIPTS/DML/parameters_dml.sql', SYSTIMESTAMP, 53, '9:7868f1d9e91fa2c43b86cd6f8bd5d698', 'sql', 'Environment type values for PARAMETERS table at PROD only', 'MARK_RAN', 'version_1', 'jira-3', '4.25.1', '8610923542');
-- Changeset POST_SCRIPTS/compile_HR_after.sql::compile_HR_before::rafal
-- Compile HR invalid objects before other changesets executuon
begin
dbms_utility.compile_schema(
schema => 'HR',
compile_all => false,
reuse_settings => true);
end;
/
INSERT INTO HR.DATABASECHANGELOG (ID, AUTHOR, FILENAME, DATEEXECUTED, ORDEREXECUTED, MD5SUM, DESCRIPTION, COMMENTS, EXECTYPE, CONTEXTS, LABELS, LIQUIBASE, DEPLOYMENT_ID) VALUES ('compile_HR_before', 'rafal', 'POST_SCRIPTS/compile_HR_after.sql', SYSTIMESTAMP, 54, '9:84b226d042023ca9771041f4c887fd6a', 'sql', 'Compile HR invalid objects before other changesets executuon', 'EXECUTED', 'version_1', 'jira-3', '4.25.1', '8610923542');
-- Release Database Lock
UPDATE HR.DATABASECHANGELOGLOCK SET LOCKED = 0, LOCKEDBY = NULL, LOCKGRANTED = NULL WHERE ID = 1;liquibase --defaults-file=dev.liquibase.properties update --label-filter=JIRA-3
Wszystko poszło dobrze.
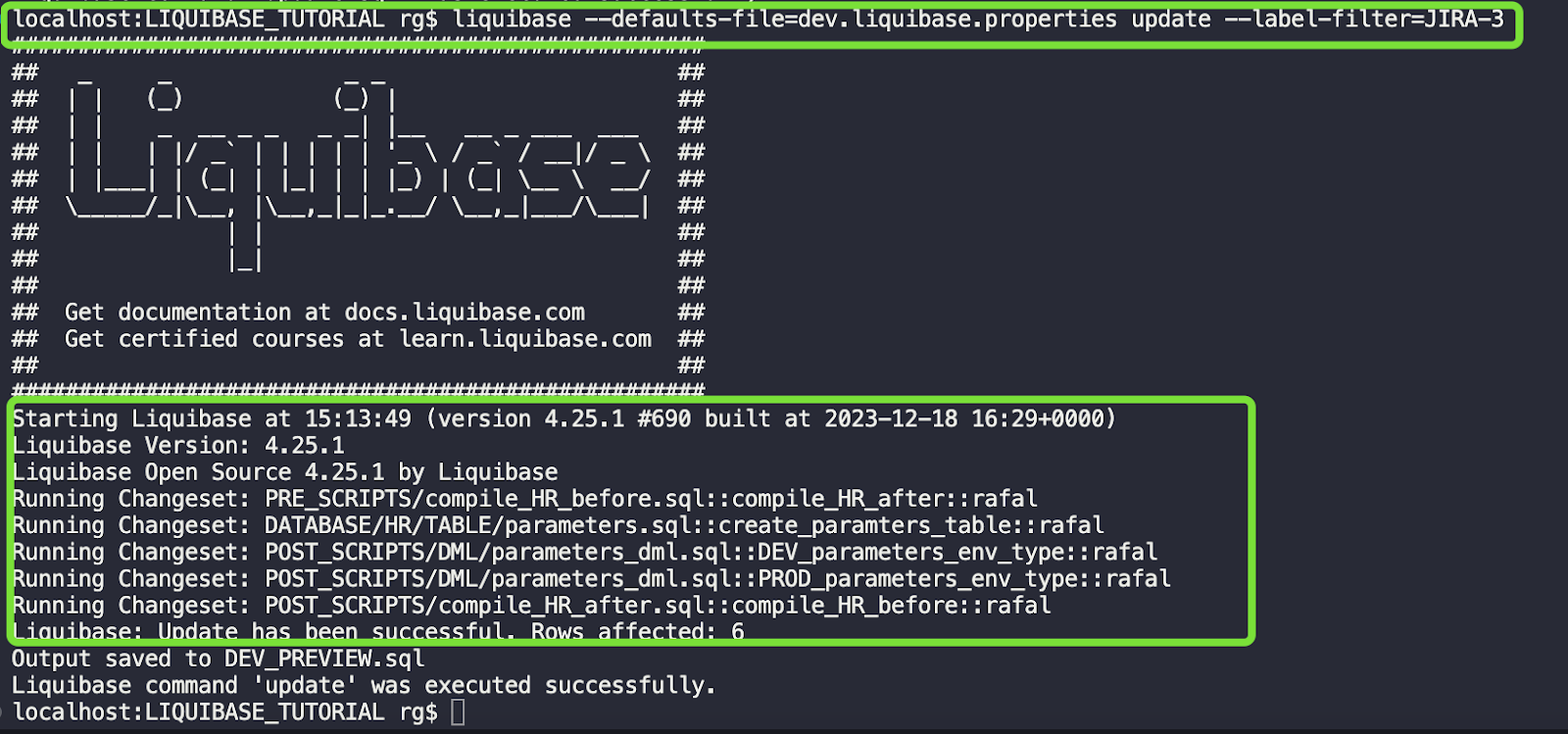

W tabeli PARAMETERS znajdują się tylko wartości dla DEV :
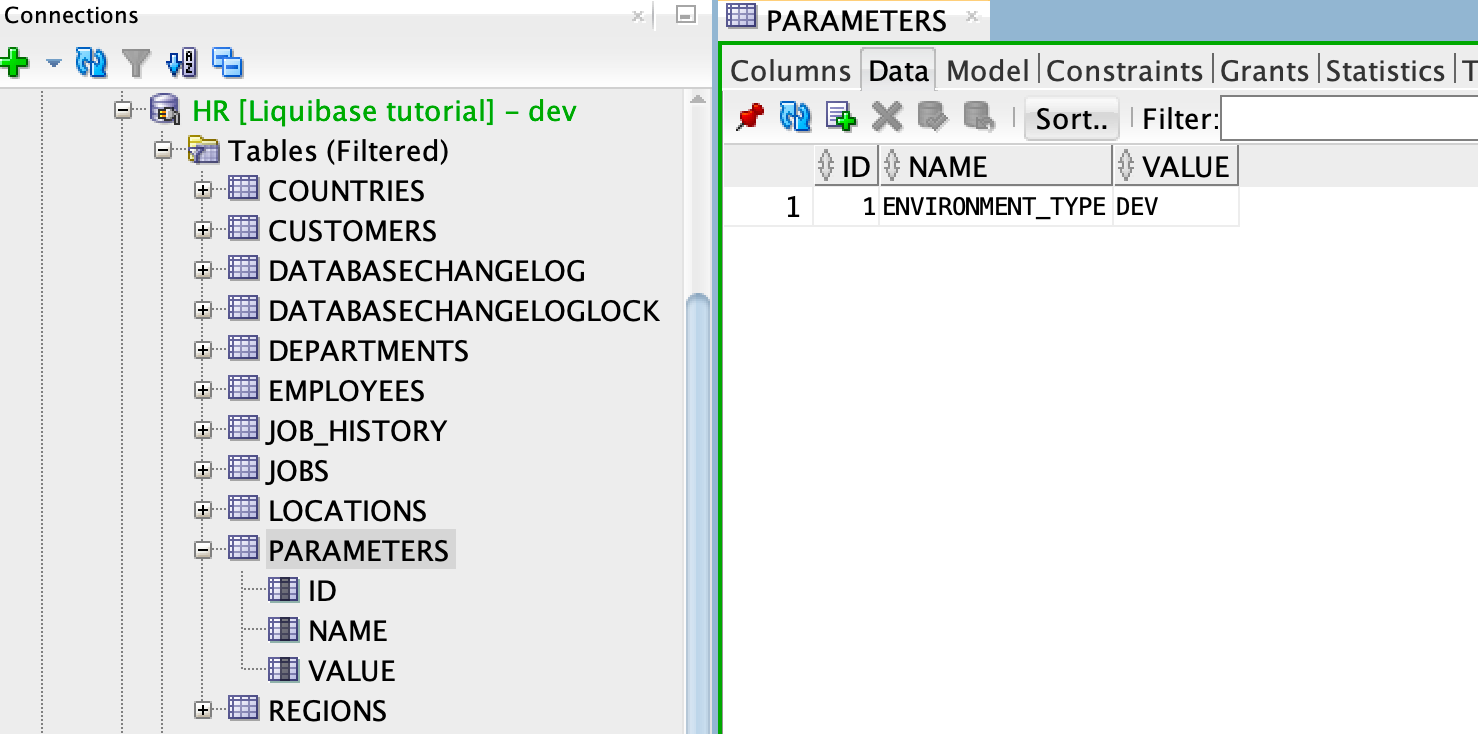
Możesz teraz zmergować gałąź JIRA-3 do DEV.
Na koniec pokażę Ci wdrażanie zmian dokonanych na DEV do innego środowiska – w moim przypadku jest to PROD, ale może to być również UAT, PRE-PROD lub dowolne inne. Najpierw przeniosę zmiany z JIRA-1 i JIRA-2, a następnie z JIRA-3. Będziesz musiał jedynie przygotować odpowiednie pliki liquibase.properties z połączeniami.
W poprzedniej części tego poradnika RAFAŁ i JAN opracowali kilka nowych funkcji dla wersji version_1 swojej aplikacji. Ukończyli zadania JIRA-1, JIRA-2 i JIRA-3.
Do naszego zespołu dołącza nowa osoba: Matt, kierownik projektu. Mówi: „Musimy wdrożyć na PROD tylko zmiany z zadań JIRA-1 i JIRA-2”.
Cieszę się, że użyliśmy kontekstów i etykiet, ponieważ będzie to łatwiejsze. Oto jak to zrobić.
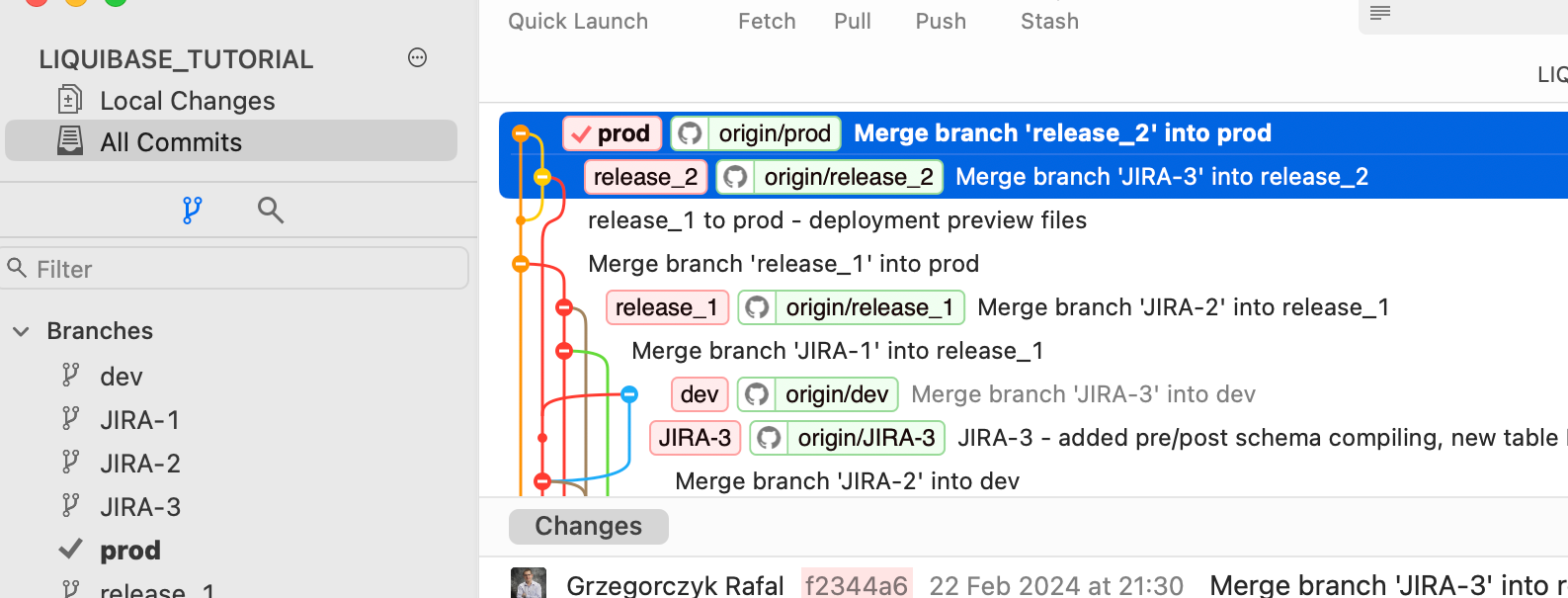
Jak pamiętasz, zmergowaliśmy zadania JIRA-1, JIRA-2 i JIRA-3 do brancha DEV . Nie mogę więc po prostu zmergować DEV do PROD w celu wdrożenia, ponieważ obejmowałoby to zmiany JIRA-3, które nie są wymagane.
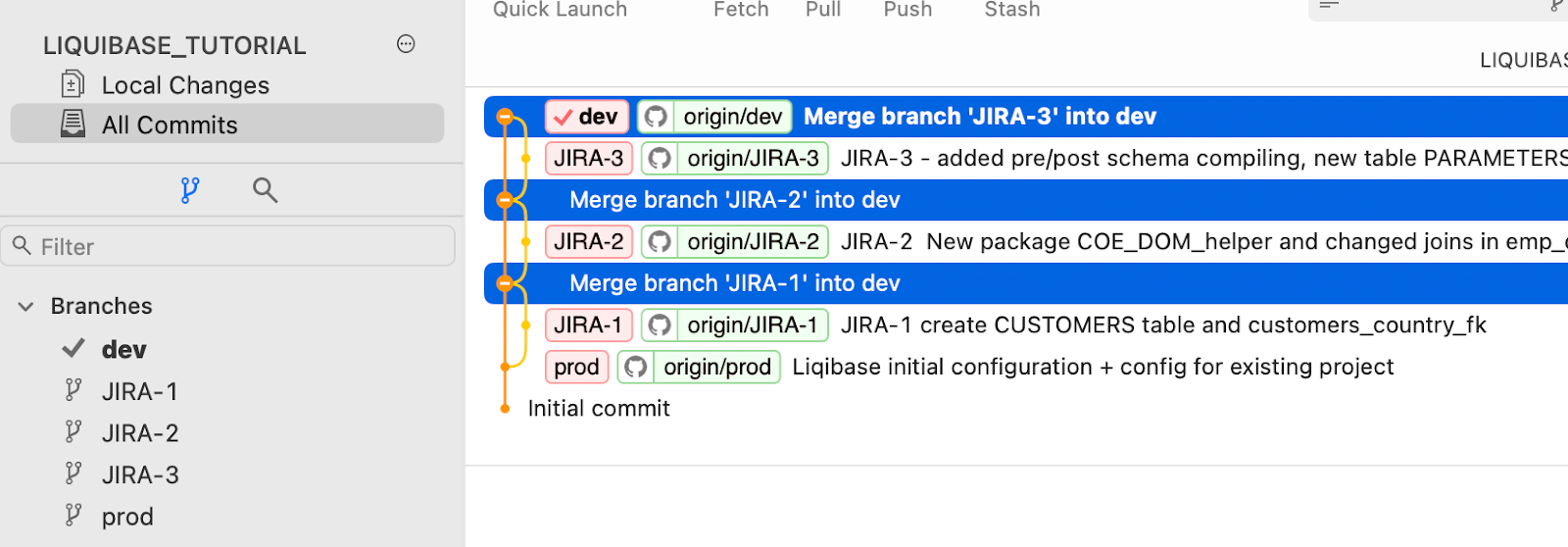
Oto co musimy zrobić:
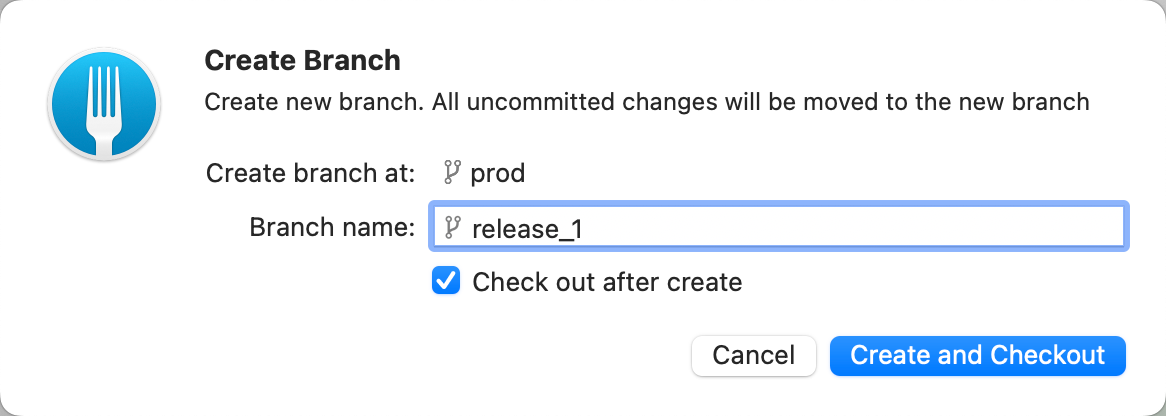
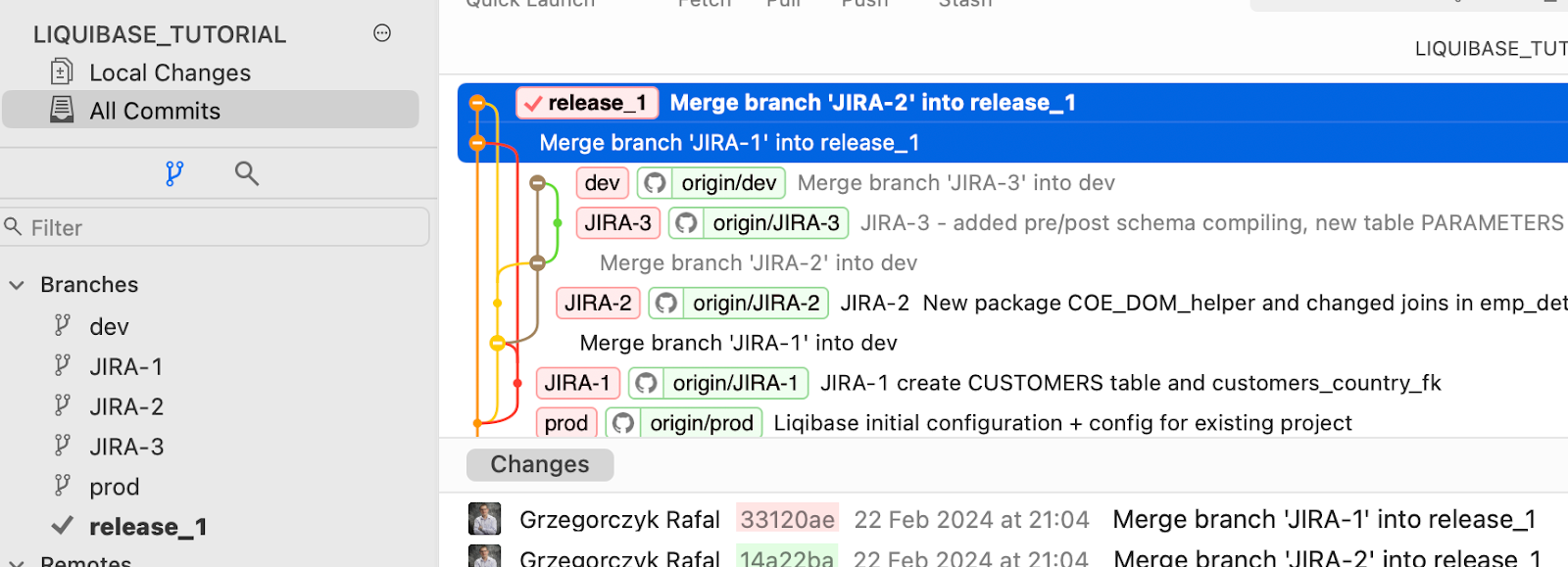
Jesteś prawie gotowy do wdrożenia na PROD.

Teraz wdróż zmiany ze swojego brancha PROD do swojej bazy danych PROD . Uruchom update-sql , aby zobaczyć, co zostanie wdrożone:
liquibase --defaults-file=prod.liquibase.properties update-sql --label-filter=JIRA-1,JIRA-2
Na branchu PROD nie ma innych oczekujących zmian, więc możesz również uruchomić to polecenie bez parametru –label-filter.
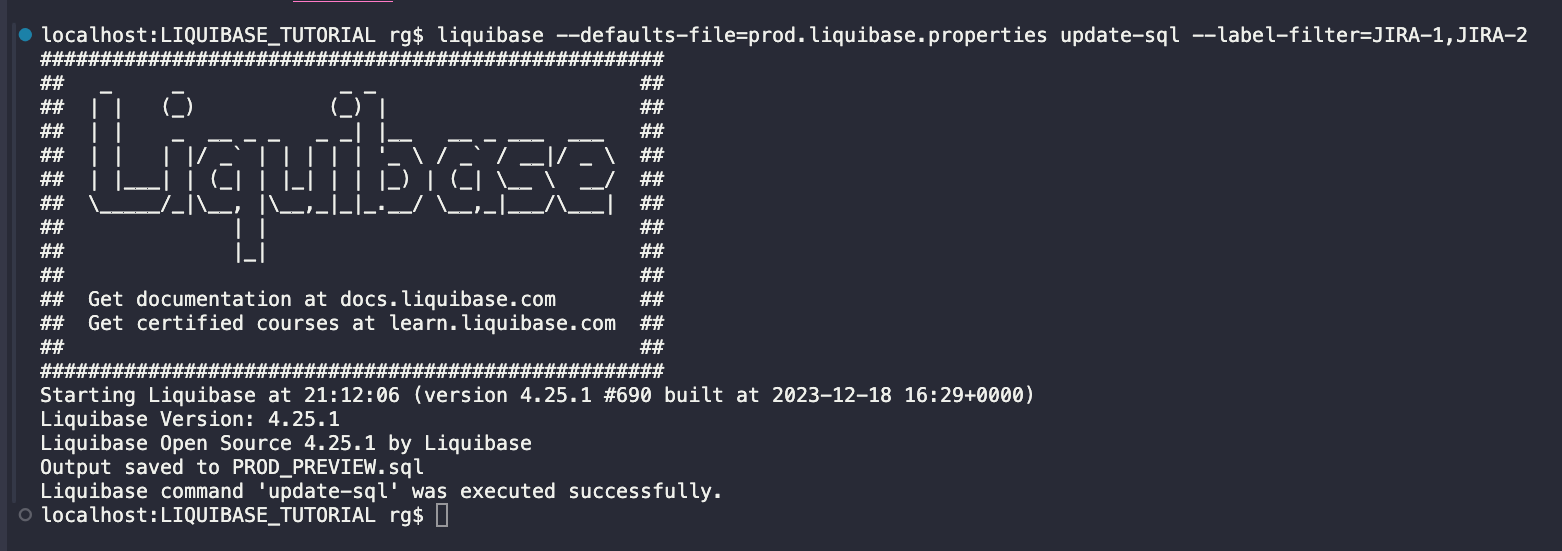
Skrypt wygląda zgodnie z oczekiwaniami i zawiera tylko zmiany z zadań JIRA-1 i JIRA-2 (podgląd pełnego skryptu tutaj).
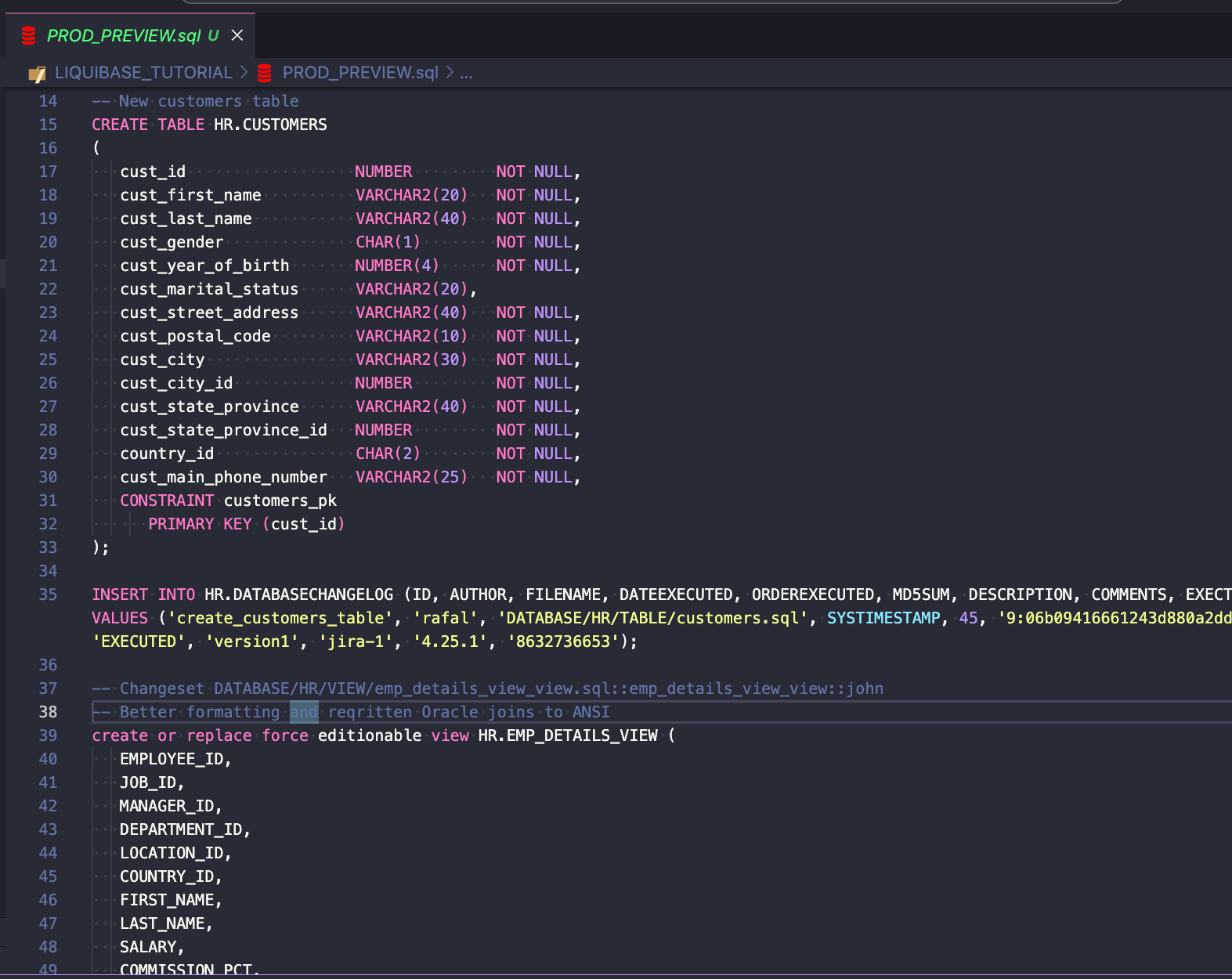
Możesz również użyć polecenia status , aby sprawdzić, które changesety zostaną wdrożone:
liquibase --defaults-file=prod.liquibase.properties status
Wynik wygląda następująco:
5 changesets have not been applied to HR@jdbc:oracle:thin:@prod_low DATABASE/HR/TABLE/customers.sql::create_customers_table::rafal DATABASE/HR/VIEW/emp_details_view_view.sql::emp_details_view_view::john DATABASE/HR/REF_CONSTRAINT/customers_country_fk.sql::customers_country_fk::rafal DATABASE/HR/PACKAGE_SPEC/COE_DOM_helper.sql::COE_DOM_helper_spec::john DATABASE/HR/PACKAGE_BODY/COE_DOM_helper.sql::COE_DOM_helper_body::john
Kroki:
liquibase --defaults-file=prod.liquibase.properties update --label-filter=JIRA-1,JIRA-2
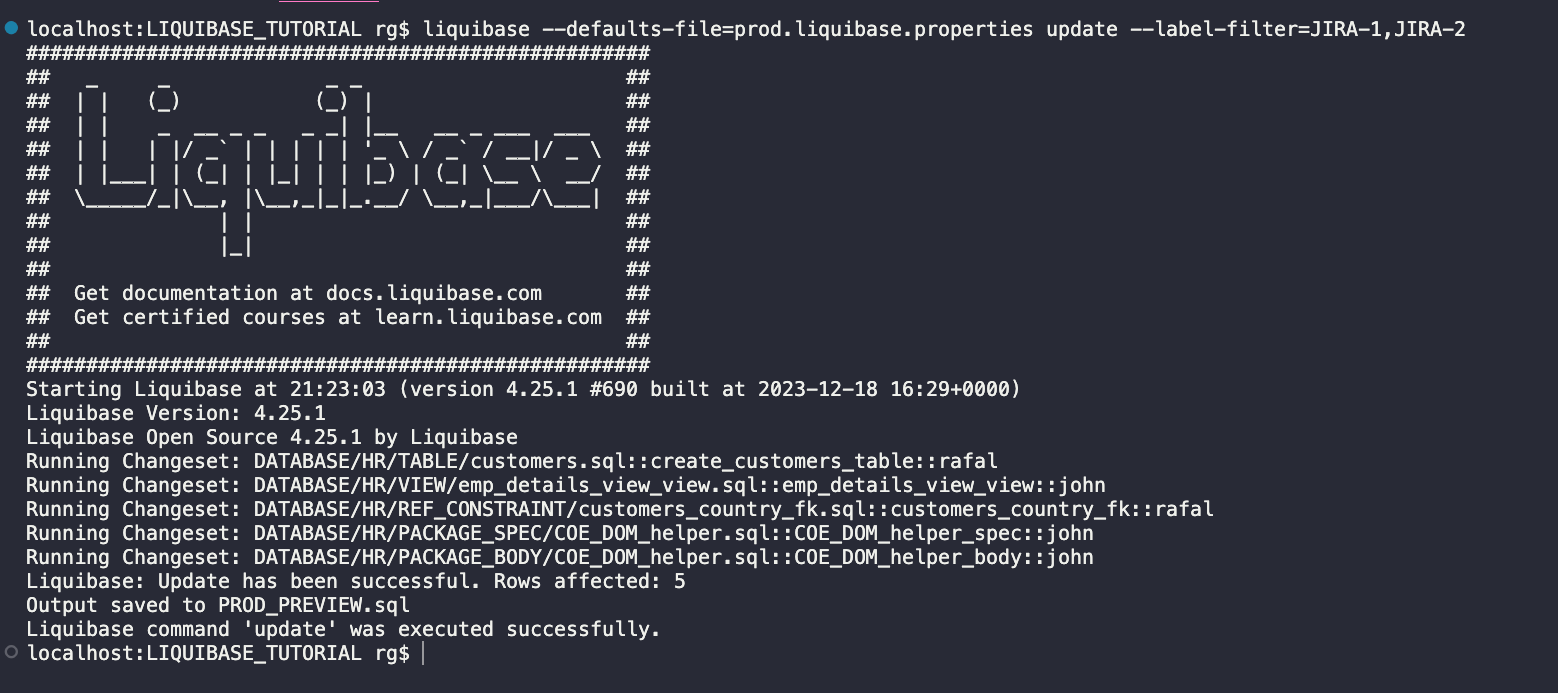
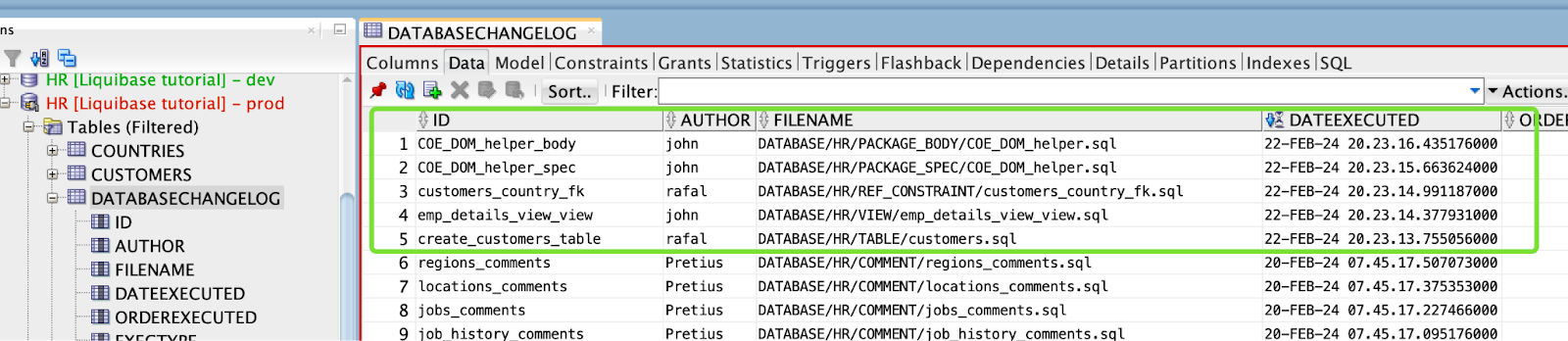
Wszystko zostało wdrożone zgodnie z oczekiwaniami.
Czas wdrożyć pozostałe zmiany z JIRA-3 na PROD.
Aby to zrobić, musisz zmergować JIRA-3 do nowo utworzonego brancha release_2. Następnie zmerguj branch release_2 do PROD (powtórz kroki wymienione powyżej tam, gdzie ma to zastosowanie).
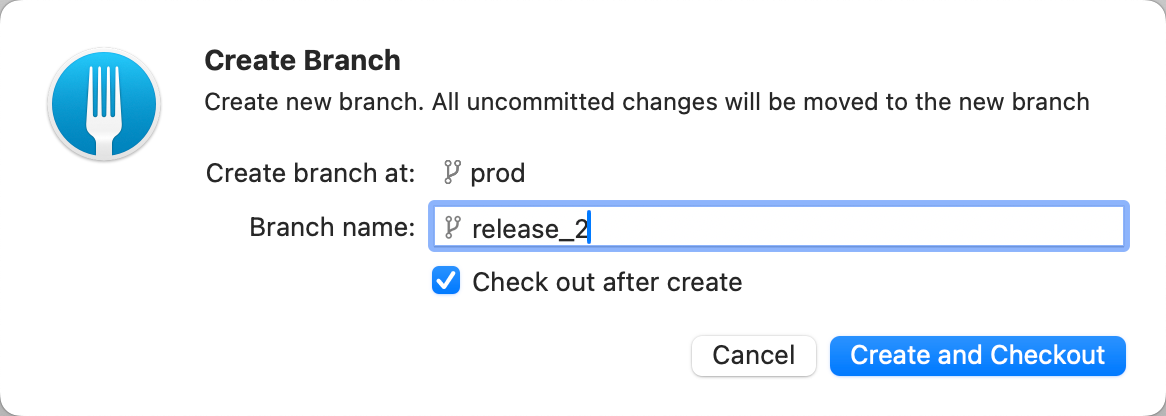

Kroki:
liquibase --defaults-file=prod.liquibase.properties update-sql --label-filter=JIRA-3
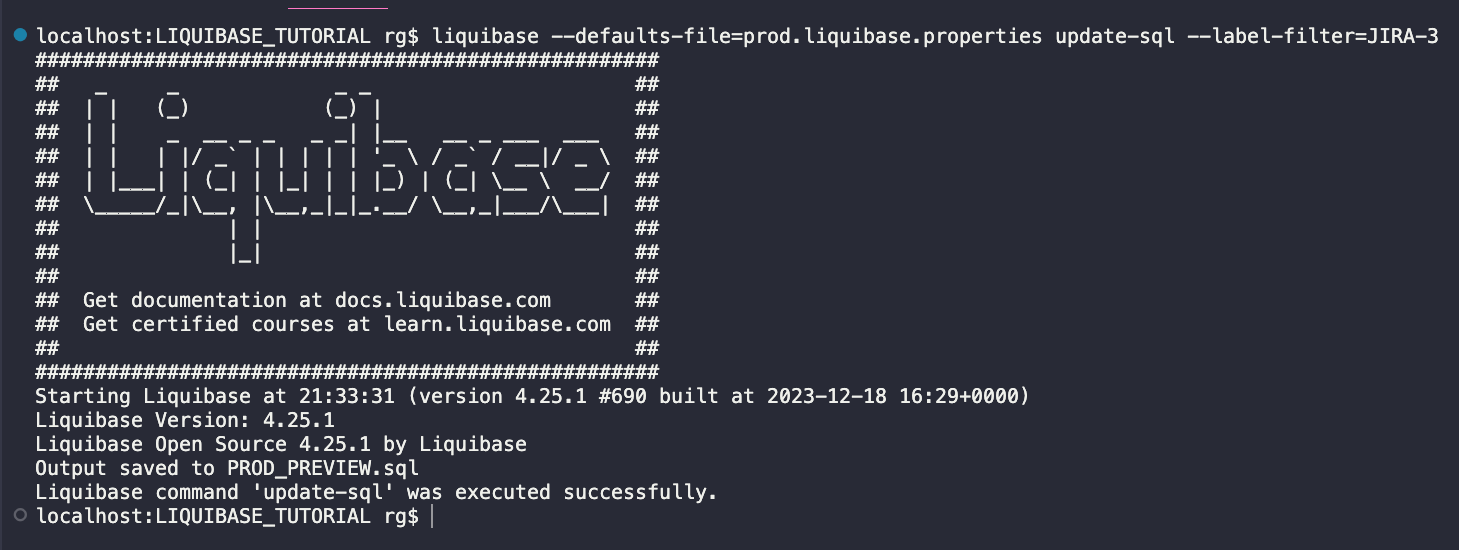
Plik wygląda dobrze (pełny podgląd skryptu jest dostępny tutaj).
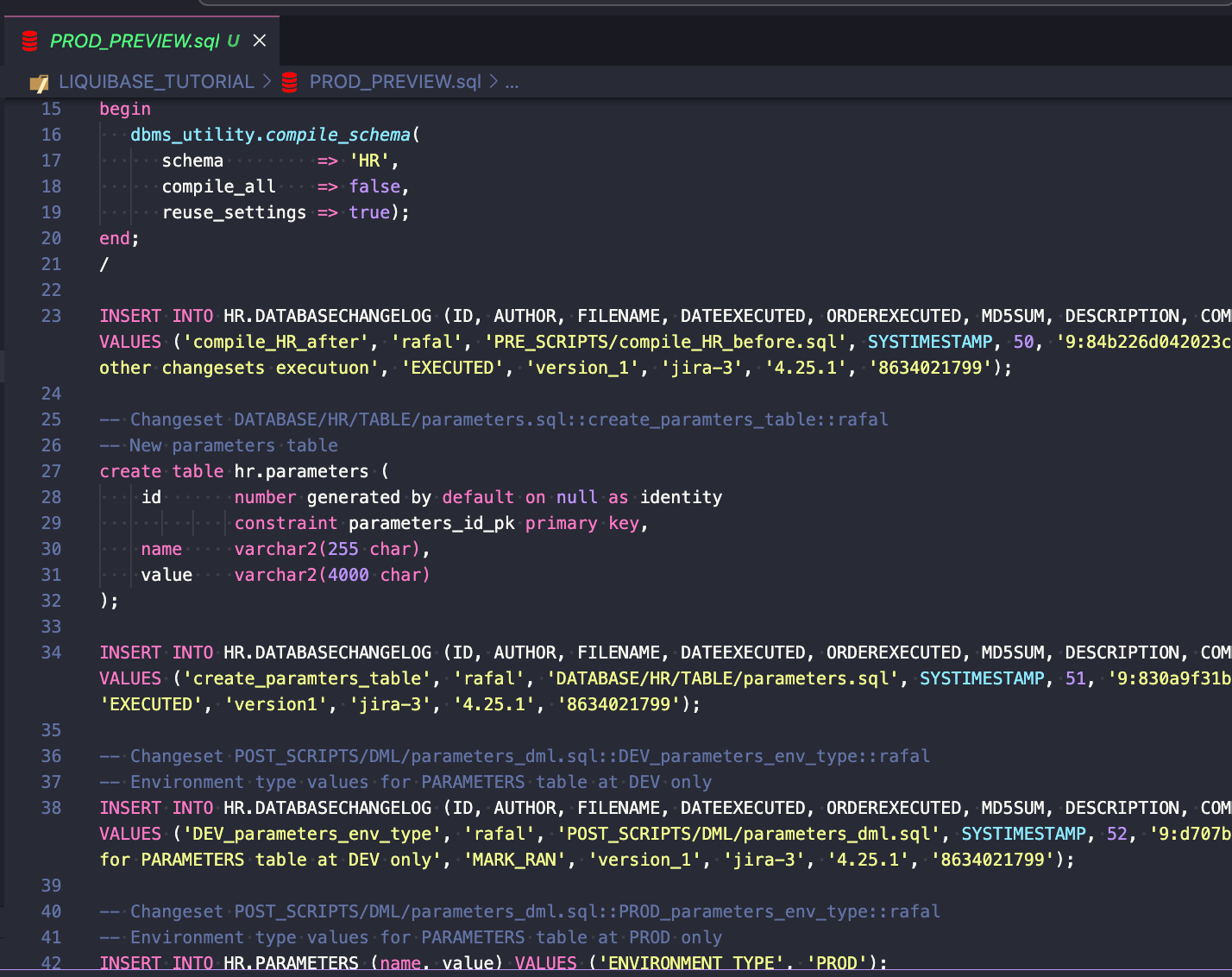
Kroki:
liquibase --defaults-file=prod.liquibase.properties update --label-filter=JIRA-3
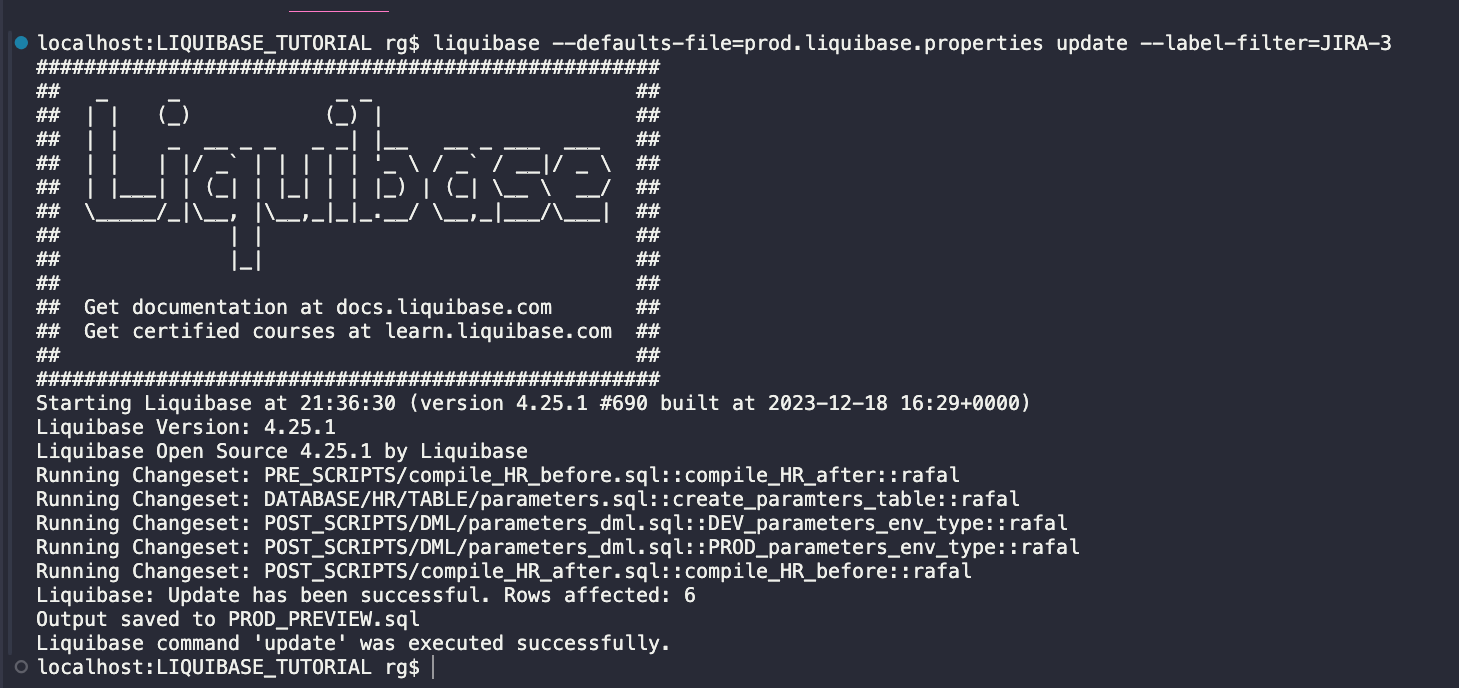
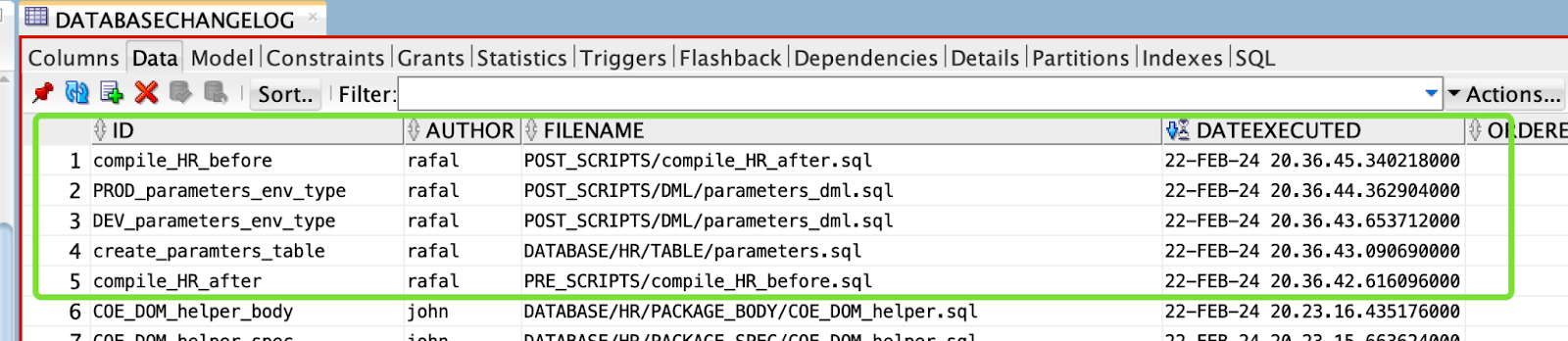
Ostatecznie wszystkie zmiany z zadań JIRA-1, JIRA-2 oraz JIRA-3 zostały wdrożone na PROD. Aby sprawdzić, czy to prawda, ponownie uruchom polecenie STATUS :
liquibase --defaults-file=prod.liquibase.properties status
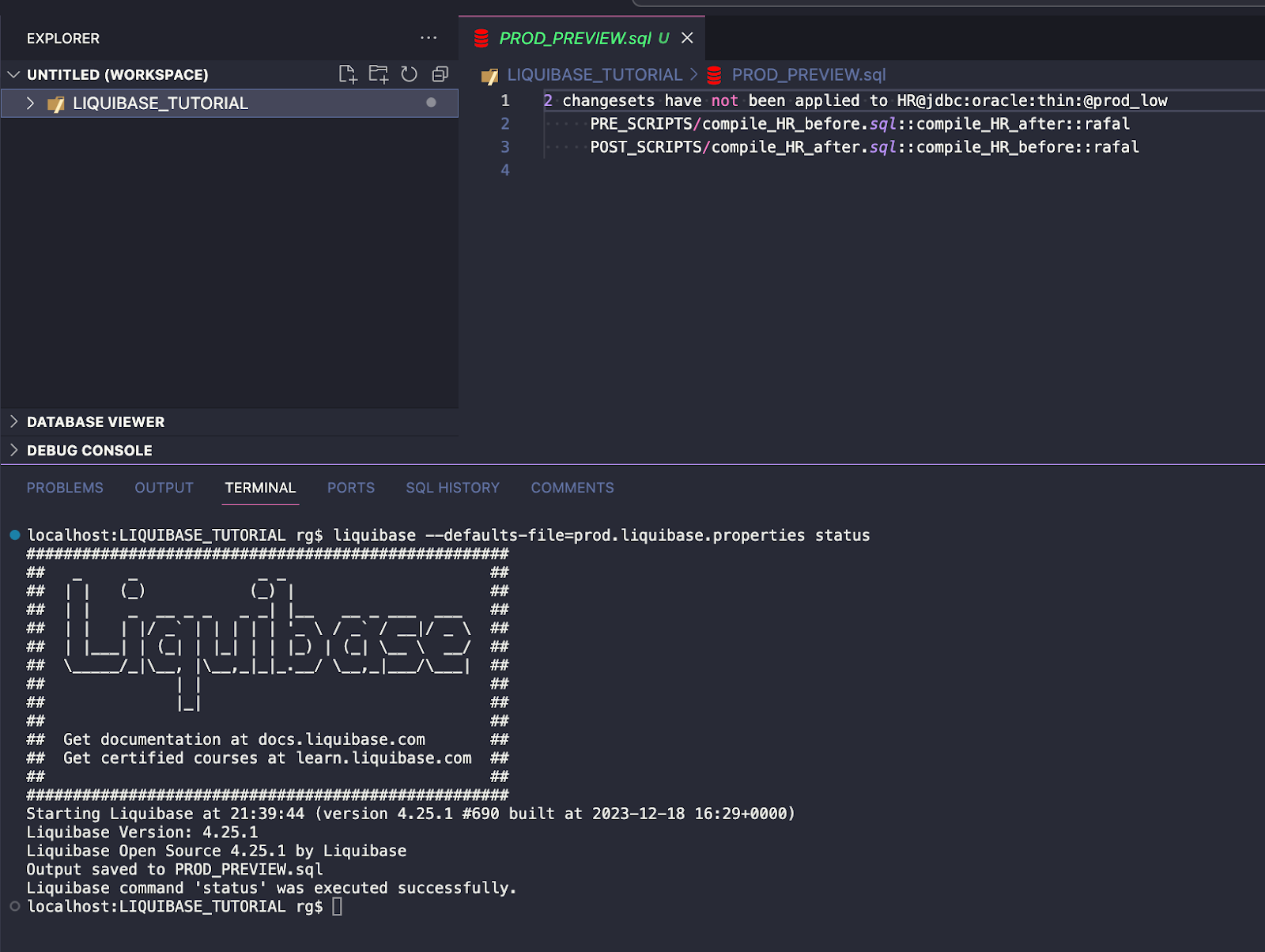
Wynik wygląda następująco:
2 changesets have not been applied to HR@jdbc:oracle:thin:@prod_low PRE_SCRIPTS/compile_HR_before.sql::compile_HR_after::rafal POST_SCRIPTS/compile_HR_after.sql::compile_HR_before::rafal
Jest to prawdą, ponieważ są to dwa changesety, które mają ustawiony parametr runAlways:true , więc będą one wykonywane za każdym razem.
To, co przeczytałeś powyżej, to najlepsze praktyki, których nauczyłem się podczas ostatnich kilku lat pracy z Liquibase – w wielu projektach i dla różnych klientów. Mam nadzieję, że da Ci to pewien wgląd w możliwości tego darmowego narzędzia open-source. Oto kilka zaleceń dotyczących korzystania z tego rozwiązania:
Możesz również zapoznać się z innymi artykułami związanymi z Liquibase na blogu Pretius:
Programiści Pretius doskonale wiedzą, jak efektywnie korzystać z Liquibase. Mamy ogromne doświadczenie w pracy z różnymi branżami i wiemy dużo o projektowaniu architektury systemów. Czy potrzebujesz pomocy w tworzeniu lub odświeżaniu złożonego rozwiązania z wieloma bazami danych? Napisz do nas na hello@pretius.com (lub skorzystaj z poniższego formularza kontaktowego). Odezwiemy się w ciągu 48 godzin i wspólnie ustalimy, co możemy zrobić dla Twojej firmy.




