
[Uwaga] Ten artykuł został pierwotnie przygotowany w języku angielskim i został przetłumaczony na język polski.
W moim poprzednim artykule opisałem moje pierwsze spotkanie z nową funkcjonalnością Oracle Database 23ai o nazwie JSON-Relational Duality Views. Ta funkcja jest szczególnie przydatna do parsowania lub tworzenia obiektów JSON w bazie danych Oracle. Dzisiaj napiszę własną procedurę, aby uczynić parsowanie JSON jeszcze łatwiejszym.
Moim zdaniem pisanie własnej procedury ma sens, jeśli masz do czynienia z małymi obiektami JSON o prostej hierarchii. Jeśli jednak używasz JSON często i musisz utrzymywać wiele typów zdefiniowanych przez użytkownika (User-defined types) oraz widoków duality views, warto stworzyć procedurę typu „szwajcarski scyzoryk”, która wykona pracę za Ciebie.
Tabele, na których będę pracować podczas pisania tego artykułu, to przykłady tabel Project Milestones z narzędzia Quick SQL w APEX.
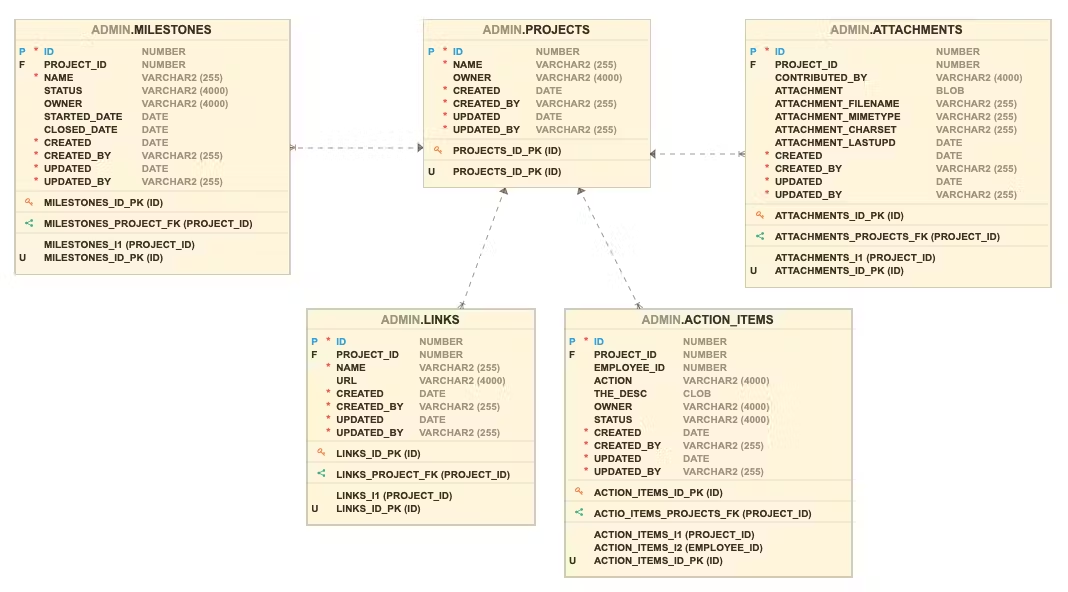
Typowa reprezentacja projektu w formacie JSON będzie miała główny obiekt JSON z kilkoma atrybutami oraz tablice (arrays) dla kamieni milowych (milestones), załączników (attachments), linków i elementów akcji (action items).
{
"projects": [
{
"id": "1",
"name": "Pharmacy project",
"owner": "Tomas",
"created_by": "TK",
"links": [
{
"name": "Rachel Morris",
"url": "http://datefjo.do/memwez"
}
],
"action_items": [
{
"project_id": "1",
"action": "Action 2",
"the_desc": "N/A",
"owner": "N/A",
"status": "completed"
}
],
"milestones": [
{
"project_id": "1",
"name": "Milestone 4",
"status": "completed",
"owner": "N/A",
"started_date": "01.02.2024",
"closed_date": "01.04.2024"
}
],
"attachments": [
{
"project_id": "1",
"contributed_by": "TK"
}
]
}
]
}
Zanim zacznę kodować procedurę, chcę ustalić kryteria, które zamierzam spełnić.
Stworzyłem diagram kroków niezbędnych do sparsowania JSON do tabel. Możesz go zobaczyć poniżej.
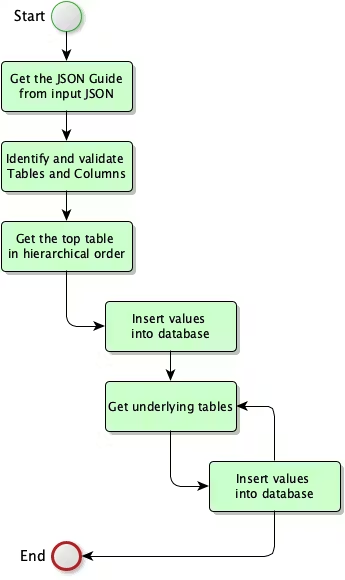
Najpierw używam funkcji JSON_DATAGUIDE, aby pobrać strukturę wejściowego JSON. Następnie uruchamiam kilka zapytań, aby sprawdzić, czy tabele (tablice) istnieją w bazie danych i wstawiam wszystkie informacje do własnej tabeli json_structure_to_process.
Tabela będzie przechowywać dla mnie strukturę, więc nie muszę wielokrotnie odpytywać wejściowego JSON, jeśli zajdzie taka potrzeba.
W następnym kroku biorę najwyższy obiekt w hierarchii, którym w moim przypadku jest tablica „projects”.
Uruchamiam prostą pętlę (loop), w której tworzę dynamiczne zapytanie SQL generujące insert z selectem z funkcji JSON_TABLE. Zapytanie dla tabeli projects wygląda tak jak poniżej.
insert into projects (id,name,owner,created_by)
select *
from json_table('input_json','$.projects[*]'
columns (
id VARCHAR2(11) PATH '$.id',
name VARCHAR2(26) PATH '$.name',
owner VARCHAR2(18) PATH '$.owner',
created_by VARCHAR2(12) PATH '$.created_by'
)
);
Po wykonaniu tego zapytania pętla wychwyci podrzędne tablice (tabele) i stworzy dla nich podobne inserty.
W moim przypadku pozostałe tablice to Links, Action items, Milestones oraz Attachments. Zapytania utworzone przez procedurę znajdują się poniżej.
--Links
insert into links (url,name)
select *
from json_table('input_json','$.projects.links[*]'
columns (
url VARCHAR2(42) PATH '$.url',
name VARCHAR2(26) PATH '$.name'
)
);
--Action items
insert into action_items (owner,action,status,the_desc,project_id)
select *
from json_table('input_json','$.projects.action_items[*]'
columns (
owner VARCHAR2(14) PATH '$.owner',
action VARCHAR2(18) PATH '$.action',
status VARCHAR2(26) PATH '$.status',
the_desc VARCHAR2(14) PATH '$.the_desc',
project_id VARCHAR2(11) PATH '$.project_id'
)
);
--Milestones
insert into milestones (name,owner,status,project_id,closed_date,started_date)
select *
from json_table('input_json','$.projects.milestones[*]'
columns (
name VARCHAR2(26) PATH '$.name',
owner VARCHAR2(14) PATH '$.owner',
status VARCHAR2(26) PATH '$.status',
project_id VARCHAR2(11) PATH '$.project_id',
closed_date DATE PATH '$.closed_date',
started_date DATE PATH '$.started_date'
)
);
--Attachments
insert into attachments (project_id,contributed_by)
select *
from json_table('input_json','$.projects.attachments[*]'
columns (
project_id VARCHAR2(11) PATH '$.project_id',
contributed_by VARCHAR2(12) PATH '$.contributed_by'
)
);
Większość moich kolumn to VARCHAR2, ale prawdopodobnie możesz użyć dowolnego typu kolumny, ponieważ typ jest automatycznie wykrywany przez JSON_DATAGUIDE. Zawsze możesz dopracować swoją procedurę, aby była bardziej precyzyjna, jeśli potrzebujesz konkretnego typu danych.
Po przejściu przez wszystkie obiekty w JSON i wstawieniu wszystkich danych, pętla kończy działanie.
Jak zapewne zauważyłeś, największą wadą tego rozwiązania jest prawdopodobnie wymóg, aby nazwy tablic i kolumn odpowiadały nazwom właściwych tabel i kolumn. Jednak zawsze możesz użyć funkcji dopasowującej (matching function), która nie będzie wymagała 100% dokładności nazw.
Innym ograniczeniem jest wydajność. Przetwarzanie dużego wejściowego JSON ze skomplikowaną hierarchią zajmie dużo czasu.
Największą zaletą używania tej własnej procedury jest czas zaoszczędzony podczas tworzenia i utrzymywania User-defined types lub JSON duality views. To rozwiązanie pozwala po prostu wrzucić JSON do procedury bez żadnego wcześniejszego przygotowania czy mapowania (mapping).
Zatem to zależy od tego, który czas cenisz bardziej: czas pracy procedury, która sparsuje JSON, czy czas spędzony na development i utrzymanie.
Cały kod, którego użyłem w tym artykule, jest dostępny tutaj. Procedura jest bardzo prosta i nie poświęciłem na nią dużo czasu. Jeśli zdecydujesz się użyć jej do własnych potrzeb, możesz potrzebować pewnych modyfikacji tu i ówdzie, aby dostosować ją do konkretnych wymagań. Daj mi znać, co myślisz o tym rozwiązaniu! I dziękuję za przeczytanie mojego artykułu. Jeśli interesują Cię tego typu treści, sprawdź inne moje publikacje na blogu Pretius:




