Disclaimer: For the time being, the article focuses on the viability of the Pretius OpenAI Reviewer plugin for automatic tests, but we’re looking at other use cases of AI in software testing – including writing test scenarios using Chat GPT and Mixtral – and we’ll update the article with new information soon, so make sure to add it to your browser’s bookmarks.
A while ago, we showed you our Pretius OpenAI code review plugin, which can be a helpful code quality tool (even though it can’t fully replace peer code review). We considered what more it could be used for and decided automatic testing was potentially one of such areas. In this article, we’ll show you the results of these experiments.
OpenAI Reviewer and automatic tests – How it works in general
OpenAI Reviewer compares changes from the last commit in a given Pull Request (PR) to what is on the main branch. Please note that when a pull request has more than one commit, there is a git diff function made between changes in all commits in a new branch and the main branch that the new branch is based on (usually main/master branch, but this isn’t a rule).
Description of test cases – methods, scope, etc.
Tests were performed on the Pretius OpenAI Reviewer plugin version 0.0.16. The version uses Chat GPT version 3.5. An organization was created to conduct tests for Pretius OpenAI Reviewer, where files with automated tests written in JavaScript (using the Cypress testing framework) and TypeScript (using the Playwright testing framework) were added. Two separate projects were created, each of them intended for testing the code of one framework. Tests included:
- Uploading the entire repository with test code (test, Page Object, configuration files)
- Uploading individual test files
- Making changes to code formatting and comparing the changes for unformatted and formatted code
- Sending test files that were intentionally corrupted (e.g.. missing function closing bracket, incorrectly declared variable, or incorrect import name of an external class) when the IDE highlighted such a file in red
- Attempting to modify the prompt sent to OpenAI so that the code review indicates more precisely the line in which the problem occurred and which the review concerns
- Checking for skipping of a file that is too long and whether an appropriate message appears in the build logs
- Finally, after receiving comments from OpenAI, analyzing the plugin’s usefulness and validity in detail
OpenAI Reviewer and Cypress / JavaScript
Here is a brief summary of observations and problems encountered during the experiment.
- OpenAI Reviewer works fine for small batches of code (e.g., change in 1-3 files) and provides useful comments. Examples:
- “Line 10: The describe block should have a space before the opening parenthesis”
- “Line 11: The beforeEach block should have a space before the opening parenthesis”
- “Line 14: The it block should have a space before the opening parenthesis”
- “In the getAgentSaveButton method, the contains(‘Zapisz’) option is used to find the button. It would be better to use a more specific selector to ensure that the correct button is selected”
- It only provides comments for selected files – Jenkinsfile, test file, etc. It’s worth remembering that this tool has its limitations (however, it should also be pointed out that we’ve worked with the version 3.5 of ChatGPT, and we don’t know how the paid version would behave in similar circumstances)
- The token limit can sometimes cause the comment to be cut in half
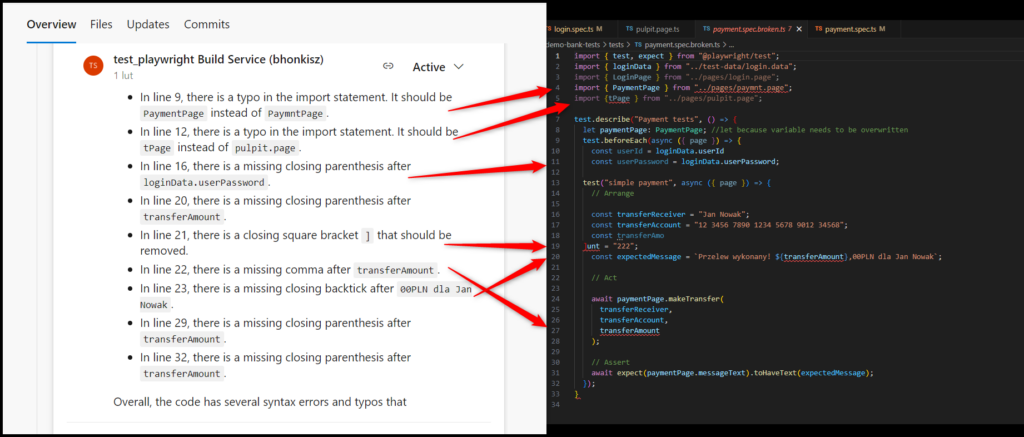
- The comments can also be untrue (for example, pointing out missing brackets that do, in fact, exist in the code)
- We’ve also tested skipping a too-long file, and it works fine. Also, if you add one normal-size file and one too long, code review will be done for the normal-size one, and the one that exceeds the length will be skipped. Information about this is included in the build logs
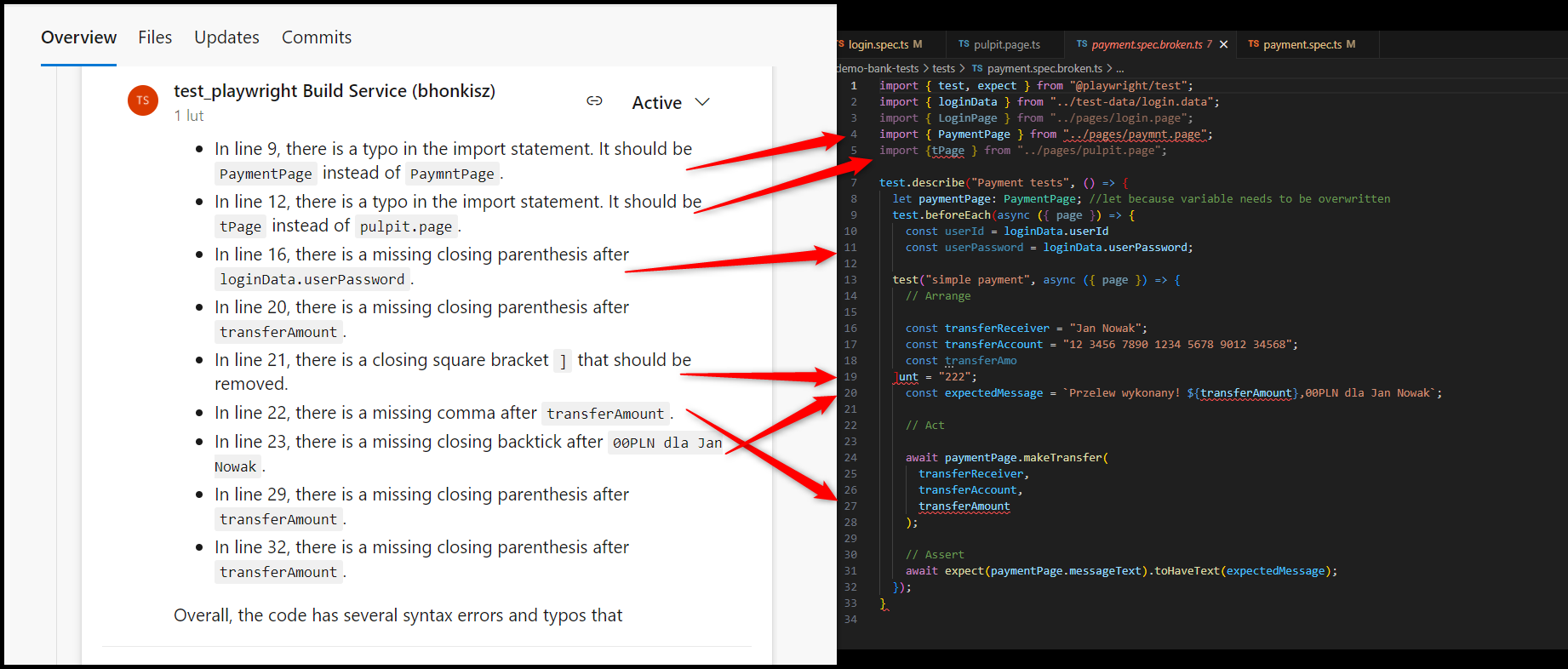
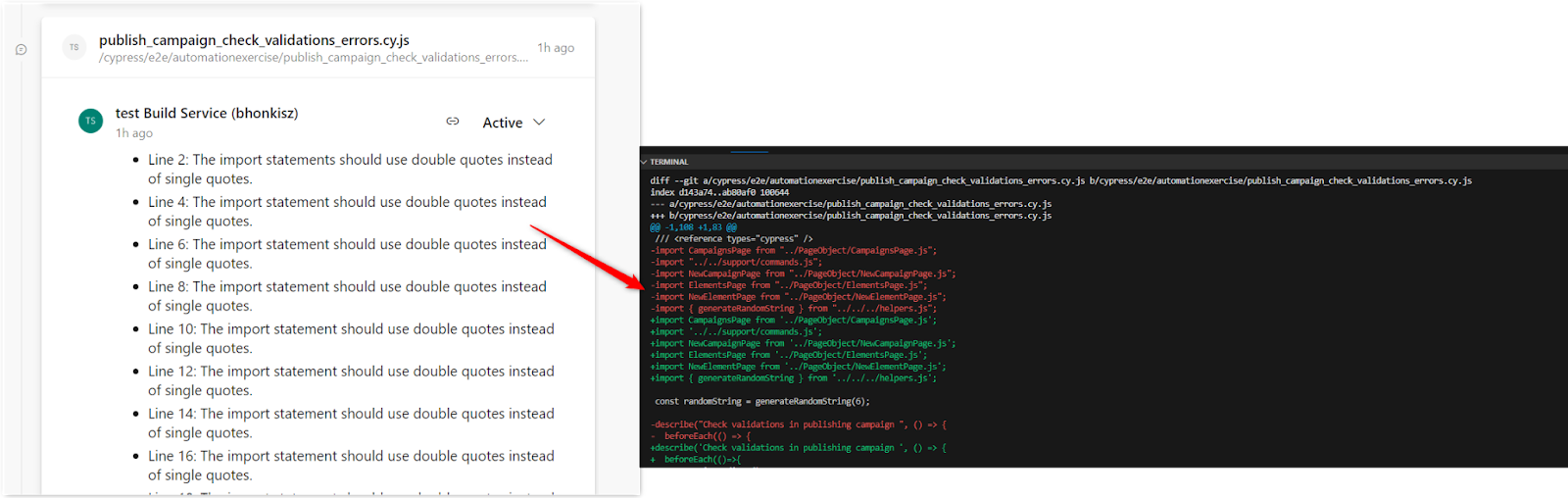
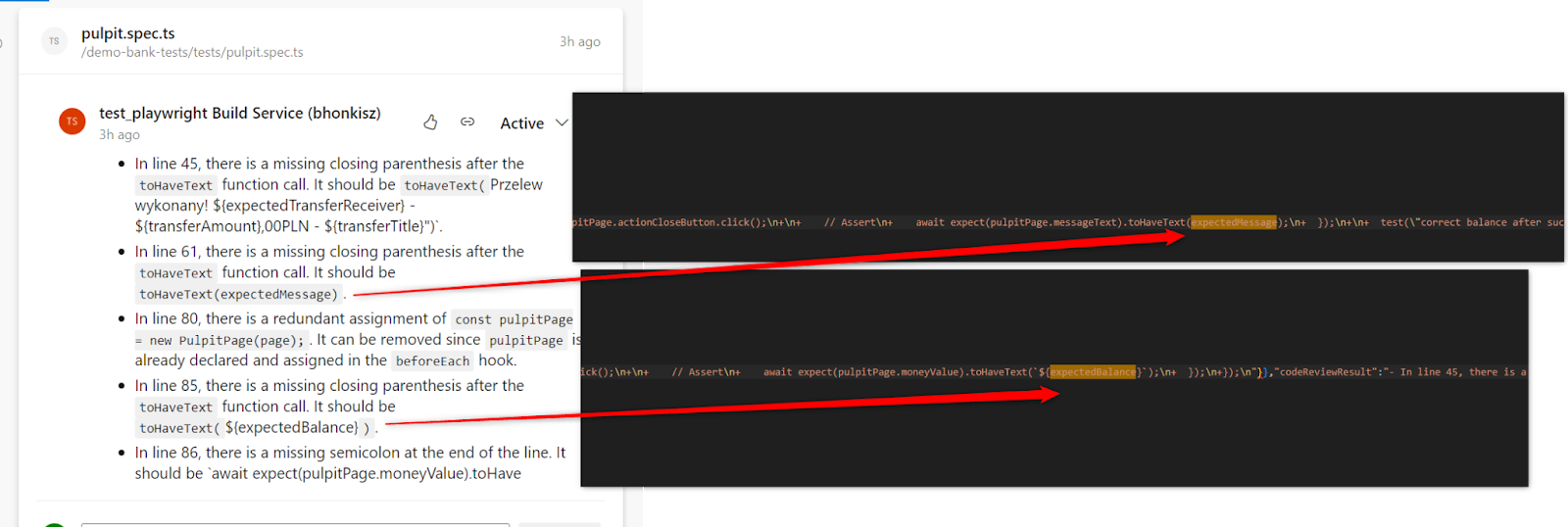
- Often, the comment indicates a lack of a semicolon at the end of the line, which is inconsistent with the actual state of the code. The situation repeats, as seen in the example below
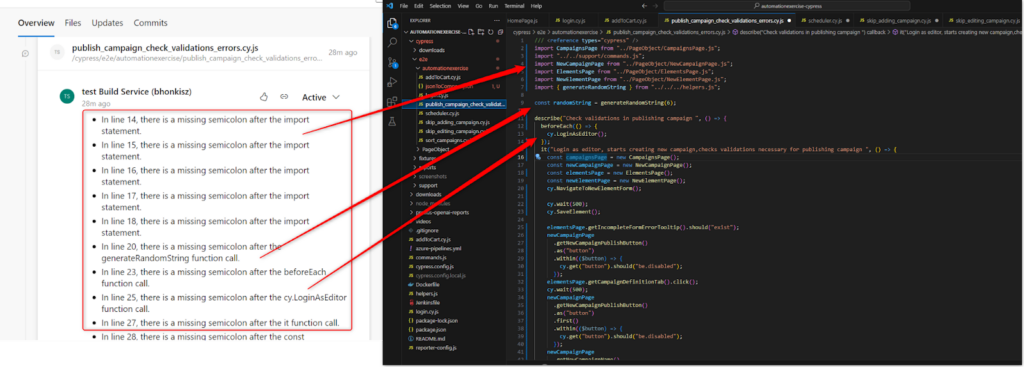
After verification, git diff on our side is sent correctly – semicolons are in the right places. Below is a fragment of git diff. The lines referred to by code review are bolded:
/// <reference types=\”cypress\” />\n+import CampaignsPage from ‘../PageObject/CampaignsPage.js’;\n+import ‘../../support/commands.js’;\n+import NewCampaignPage from ‘../PageObject/NewCampaignPage.js’;\n+import ElementsPage from ‘../PageObject/ElementsPage.js’;\n+import NewElementPage from ‘../PageObject/NewElementPage.js’;\n+import { generateRandomString } from ‘../../../helpers.js’;\n+\n+const randomString = generateRandomString(6);\n+\n+describe(‘Check validations in publishing campaign ‘, () => {\n+ beforeEach(()=>{\n+ cy.LoginAsEditor();\n+ })\n+ it(‘Login as editor, starts creating new campaign,checks
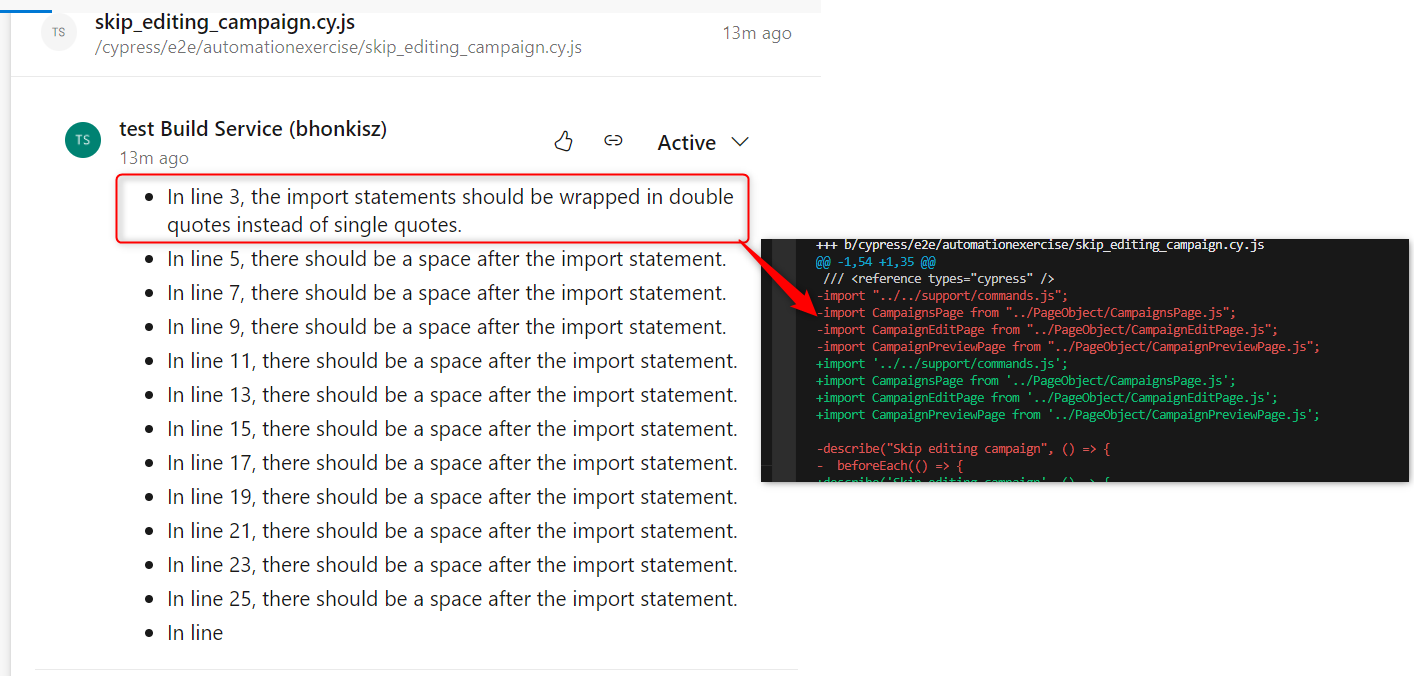
- Similarly, occasionally, we have a comment about the lack of spaces which are in place

There are more such distortions. Git diff verification usually shows that the code is sent correctly. Here’s another example using sample test files installed by default with Cypress.
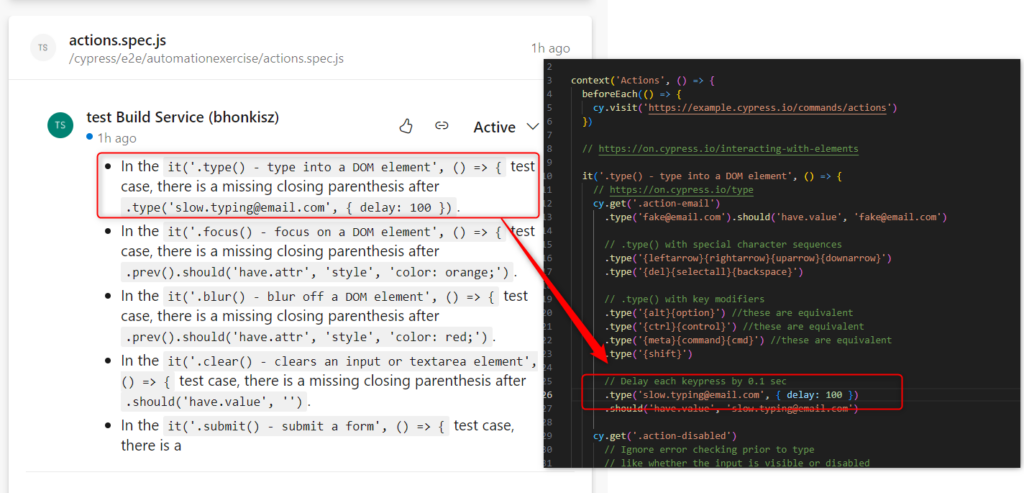
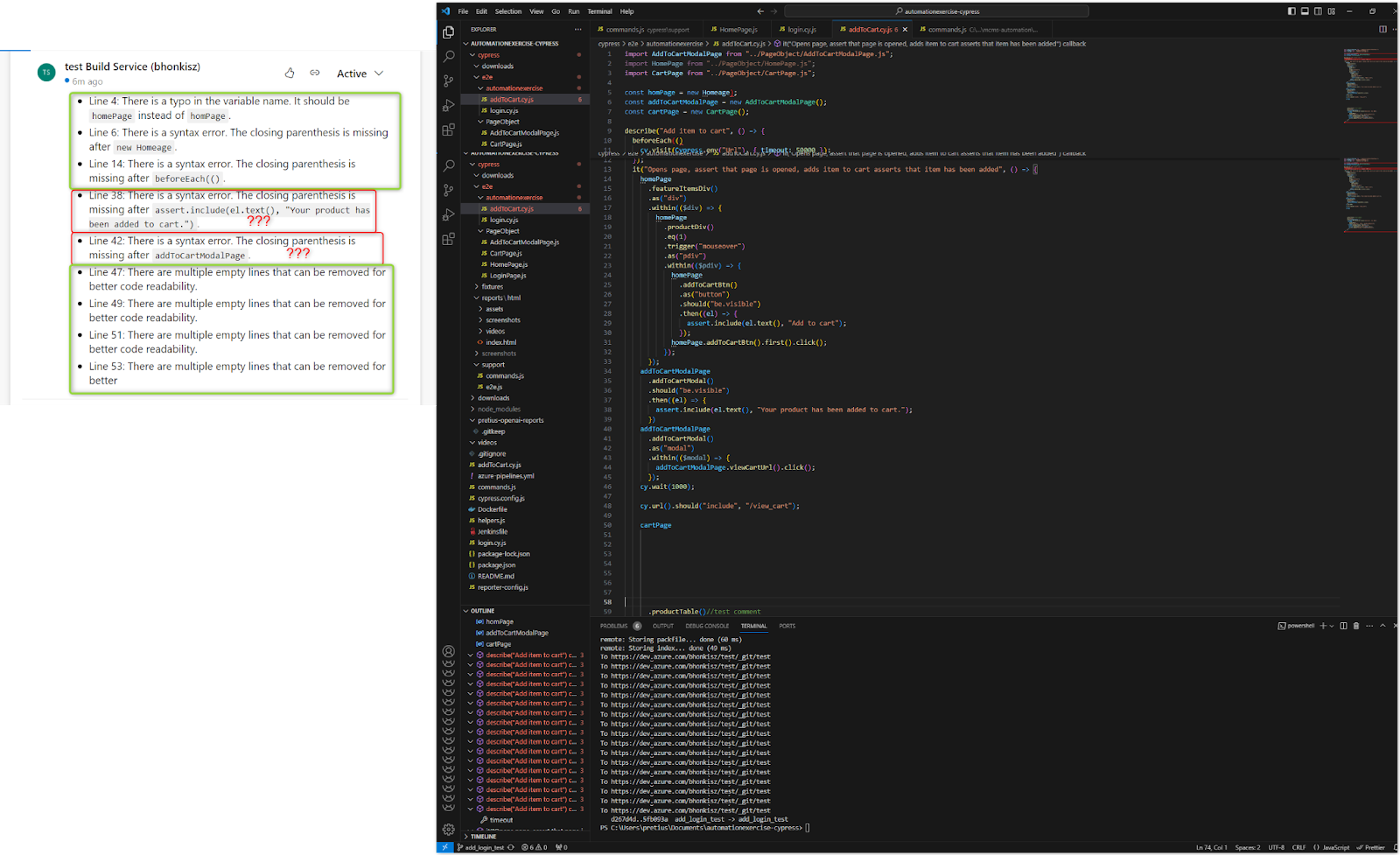
- Corrupted files (missing function closing brackets, semicolons, etc. – underlined in red in the IDE). Not all comments are valid, but generally, it works okay
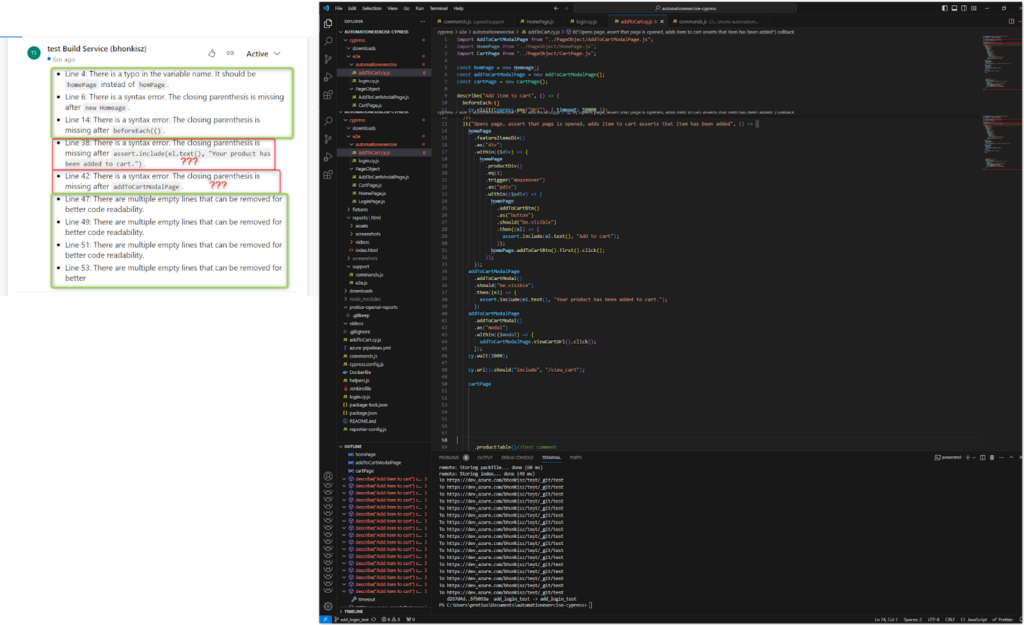
- For formatting corrections, a git diff containing the previous version is also sent (because git sees it as a change of the whole), so the review may contain comments that something is not corrected when, in fact, it has been corrected (the comment refers to the previous version). Examples:
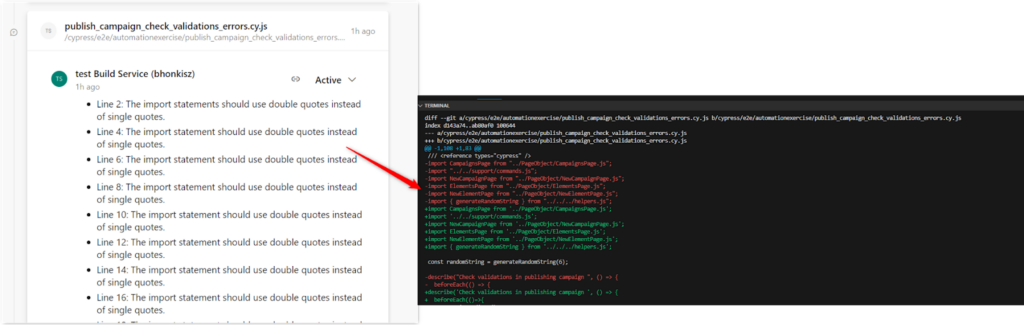
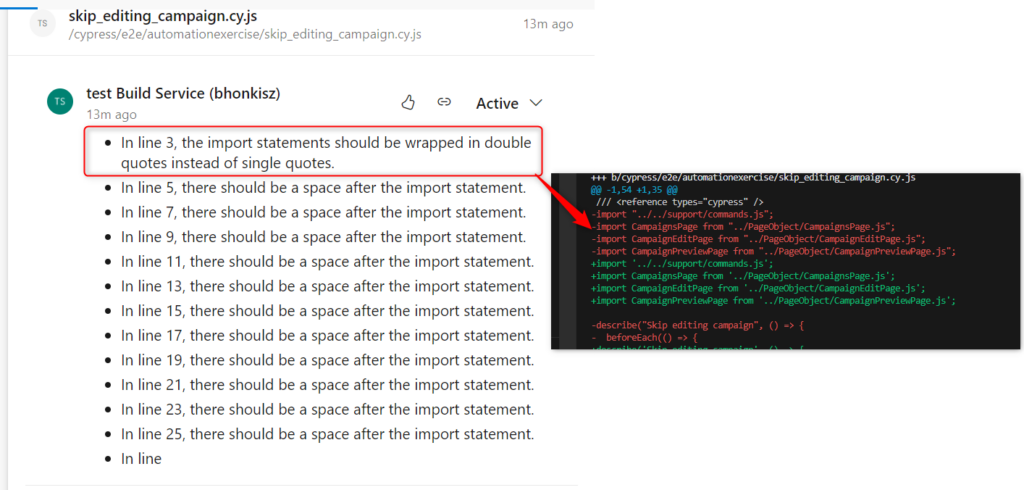
As a result, the user will get comments on the code located on both branches (the main one and the one subject to review), which may be confusing – but this is how git diff works.
OpenAI Reviewer and Playwright / TypeScript
And here’s a summary of the Playwright / TypeScript experiment.
- It provides useful notifications about the comments being in a different language than English such as “In lines 7-12, the comments are in a different language. It would be better to have them in English for better readability and maintainability.”
- The same goes for the declaration of variables: “Line 12: It seems that the variable loginPage is declared as a global variable. It would be better to declare it within the beforeEach block to ensure that it is properly scoped. Consider moving the declaration of loginPage inside the beforeEach block” or “Line 23: It seems that the variable desktopPage is declared within the test case. Since it is only used within this test case, there is no need to move it to the describe block. You can keep it declared within the test case.”
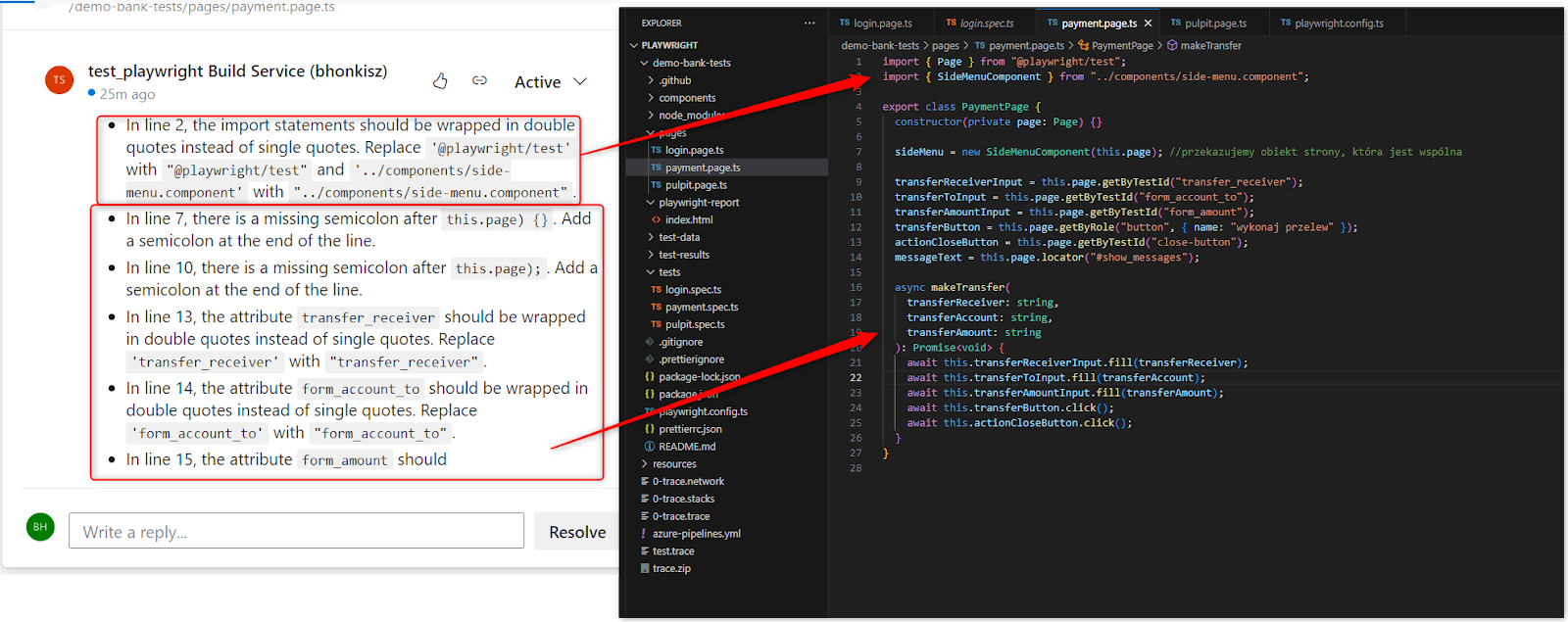
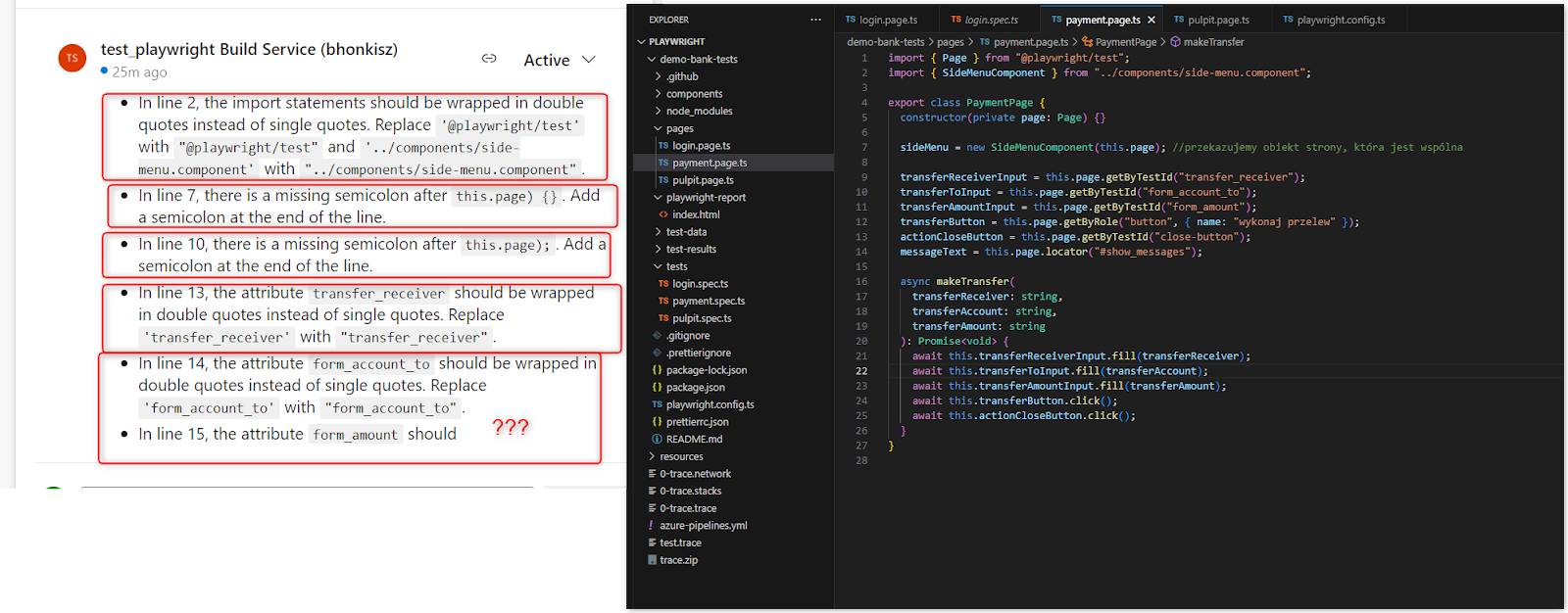
- For some reason, sometimes AI doesn’t see double quotes, only single ones. However, the error occurred only once, and I couldn’t reproduce it
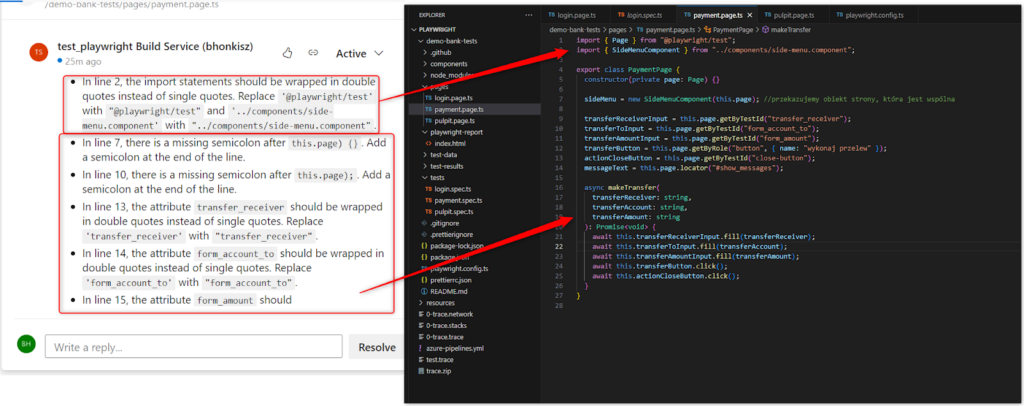
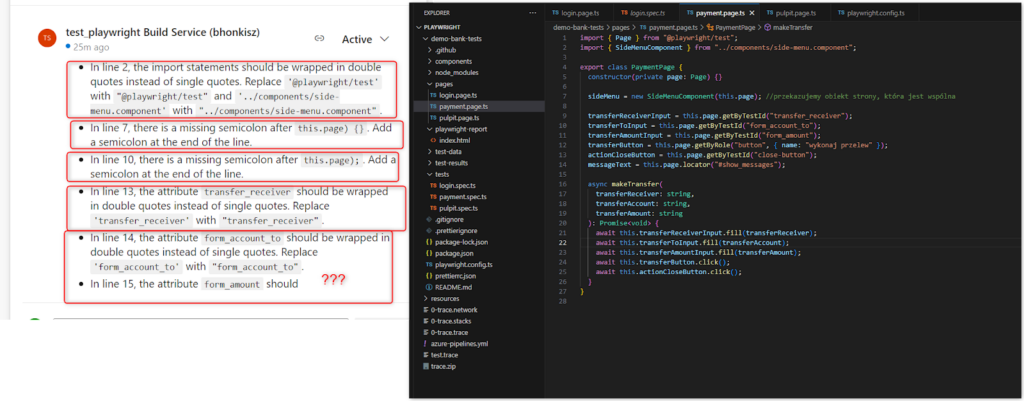
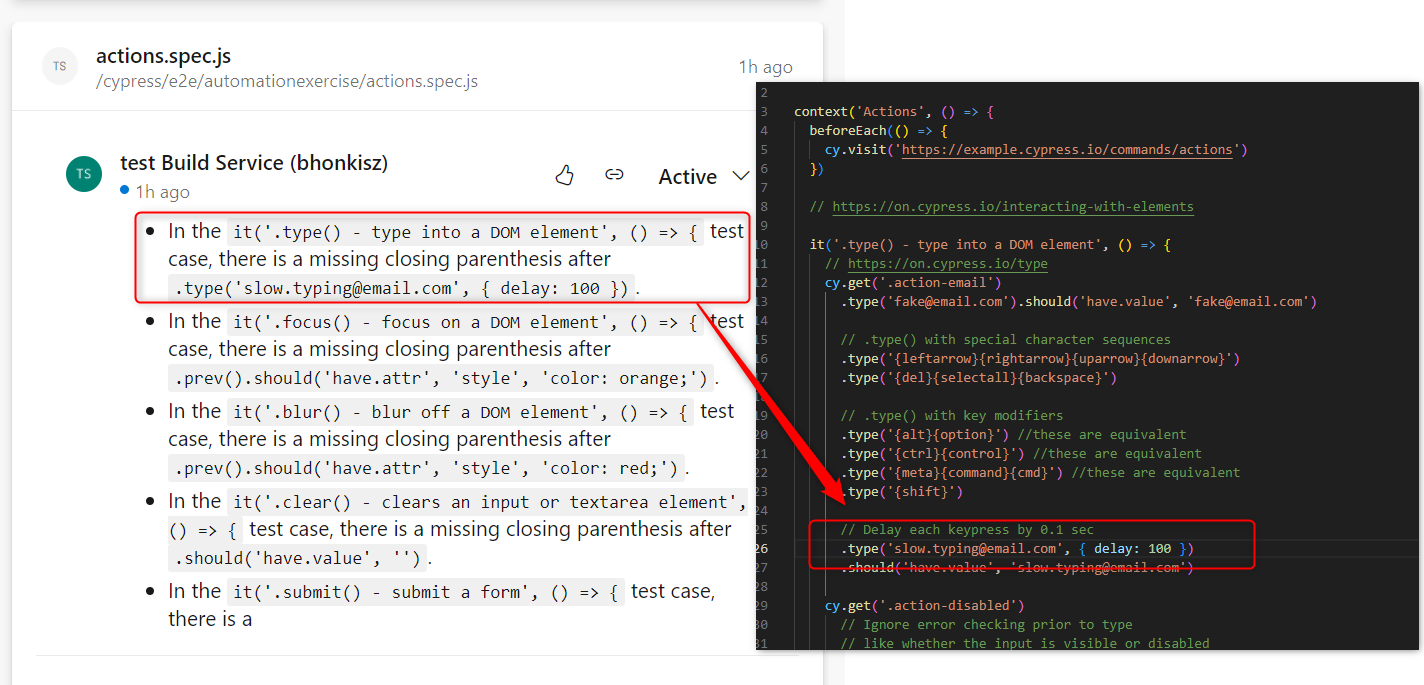
- There were occasional comments about the lack of closing brackets, even though they were there. Examples:
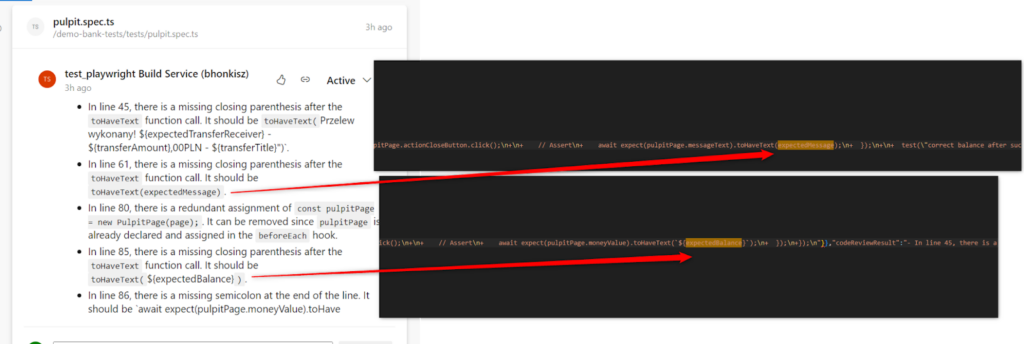
- Corrupted file – the first time, ChatGPT didn’t take errors into account at all. There are no reviews for this file. However, during the retest there were quite accurate comments, so, again, it’s not a problem I could reproduce
Pretius OpenAI Reviewer – summary of challenges and problems
Let’s summarize and look at the broader picture. Here are some problems and challenges you can run into while using our plugin:
- First of all, it should be pointed out that the tool can’t verify whether the tests that are subject to review will give a positive or negative result after the run. This is completely outside the scope of operation of the described plugin because AI often has no insight into the structure and the code of the application for which the tests are written, even if they are in an open repository.
- Also, it can’t directly run or simulate automatic tests (or any other code or application).
- Therefore, during the review, you need to take into account that the code will only be formally assessed in terms of good code writing practices, the correct syntax for a given code or framework
- To use the plugin, you must be familiar with the basics of Azure DevOps and git and gitflow in general
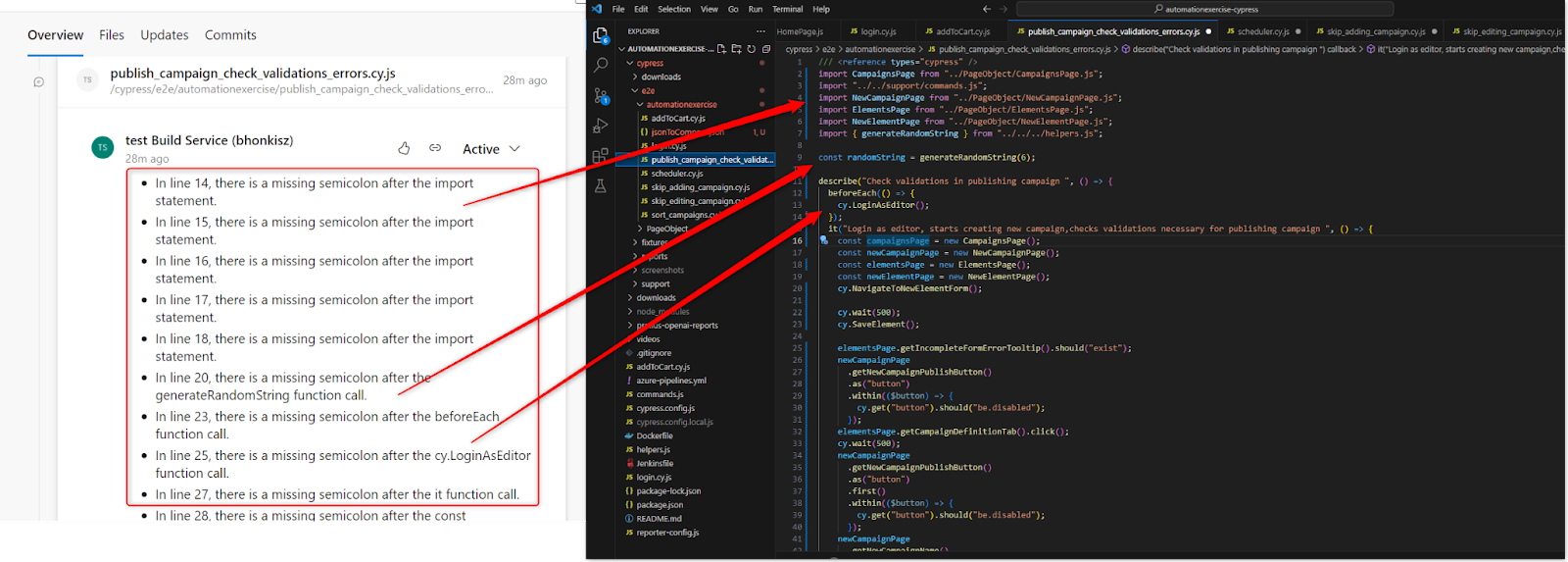
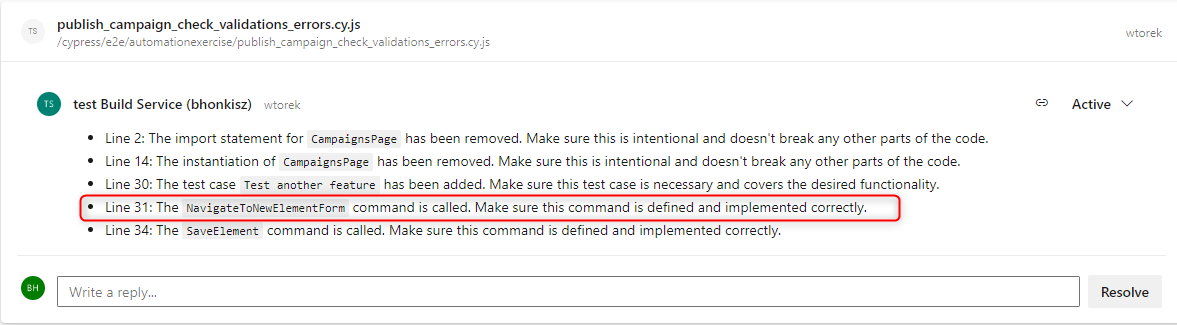
- ChatGPT may indicate areas potentially prone to errors, but it doesn’t go beyond the file that’s being checked, which can cause problems. For example:
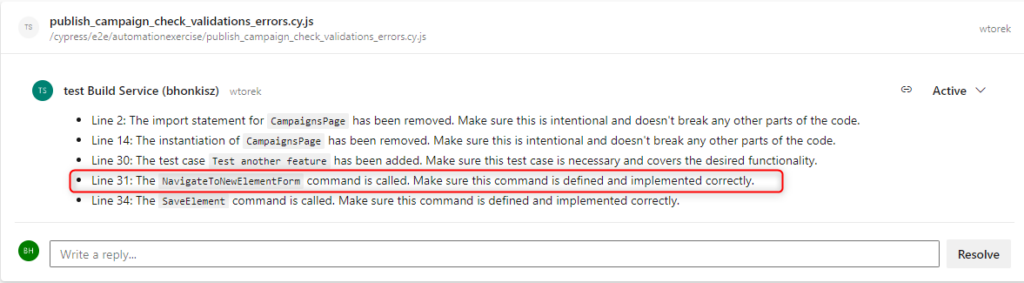
In the above example, we review the publish_campaign_check_validations_errors.cy.js file. The code review mentions that the NavigateToNewElementForm method is called. ChatGPT advises you to make sure the method is defined and correctly implemented, but this can be verified in the commands.js file.
- It’s not entirely clear in which line the error occurred – both for TS and JS. The line code indicated by AI is not the same as line in real-code. It’s a bit problematic when analyzing the code for comments. I tried to modify the default prompt sent to OpenAI, but unfortunately to no avail
- The plugin can’t review a large number of files due to token limitations. If a larger number of files are added, only some of them are subject to review
- In the case of long files, they are subject to review, but comments from OpenAI may be cut off at some point (also due to the token limit)
- Many times the comment pointed to the lack of a semicolon at the end of the line (this happened quite often for Cypress files), or other similar small problems (lack of closing brackets, etc.), which turned out to be inconsistent with the actual state of the code
- For formatting corrections, git diff containing the previous version is also sent, so the review may contain outdated comments
Conclusion: Pretius OpenAI Reviewer – current usefulness for test automation
The Pretius OpenAI plug-in can be used for code review tests, but certain limitations should be taken into account, as described above. It’s undoubtedly a future-proof tool, especially in the context of continuous development in the field of artificial intelligence that has – and still is – taking place around the world in recent years.
The plugin will be useful primarily for test tips or descriptions of what has been changed. OpenAI cannot catch all inconsistencies and it’s also prone to various errors and limitations. Some of them can be overcome by increasing the token limit (and it’s advisable to do so), but others – unfortunately – are innate to the current nature of evolving AI.
The tool will be useful if the user wants to review their own code. The person must understand its operation thoroughly, and know the exact context and purpose of the entire code because it’s necessary to separate valuable and useful information from unfounded comments.
Potentially, the plugin can also be used to help less experienced testers learn to write automated tests. While it’s unlikely to be useful for complete beginners who want to start learning automation from scratch, it may be helpful for people who already have some experience and familiarity with “automatics” and who want to explore the topic further.
| Pretius OpenAI Reviewer – automatic tests scenario |
| Pros |
Cons |
| Innovative approach |
Numerous limitations, described above |
| Ease of use – clear instructions |
Large number of unfounded comments |
| Great development possibilities – for example, moving the plugin to the GPT-4 model, which is much better compared to version 3.5 |
Won’t replace human testers (though, is it a con? 😉) |
| May help you speed up your work |
|