
Today most commercial application are developed as web application, so it is important to integrate ETL processing with Java code.
Pentaho Data Integration can be used to:
There are three ways to start Pentaho jobs and transformations:
When working with Pentaho to develop transformations and jobs you can use standalone graphical application called Spoon. It provides easy to use graphical interface for development and testing. Unfortunately, because of GUI, it can’t be executed from web application.
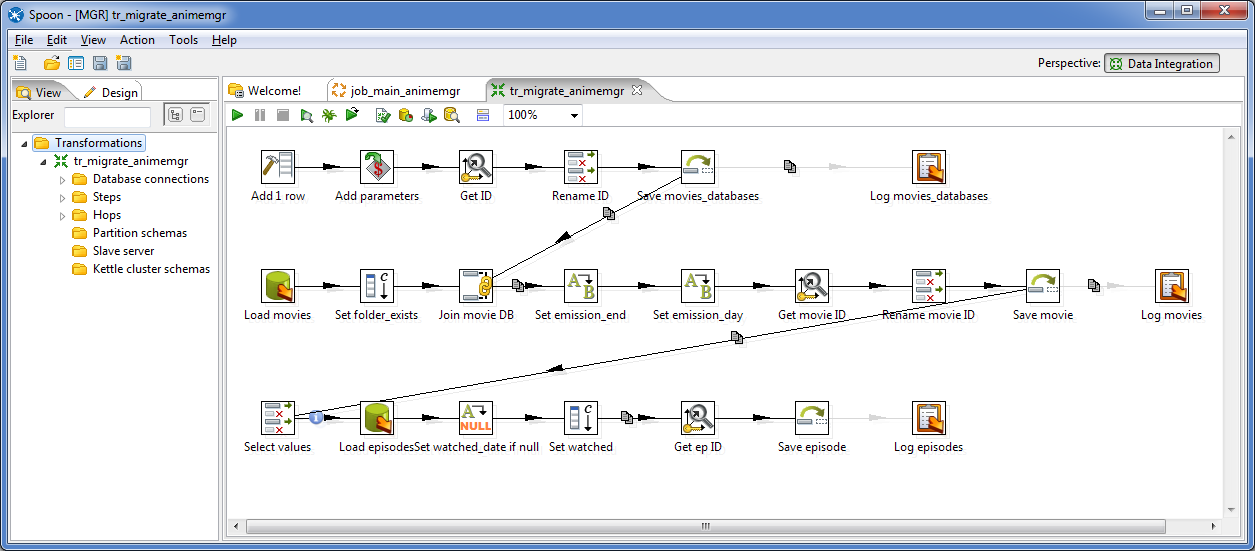
Sample transformation in Spoon
Pentaho is delivered also with “kitchen” console application, which can be executed from command line as follows:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
> kitchen.bat /rep=MGR /job=job_main_animemgr
2015/08/11 10:06:03 – Kitchen – Start of run.
2015/08/11 10:06:07 – job_main_animemgr – Start of job execution
2015/08/11 10:06:07 – job_main_animemgr – Starting entry [tr_migrate_animemgr]
2015/08/11 10:06:07 – tr_migrate_animemgr – Loading transformation from repository [tr_migrate_animemgr] in directory [/]
2015/08/11 10:06:08 – tr_migrate_animemgr – Dispatching started for transformation [tr_migrate_animemgr]
2015/08/11 10:06:08 – Save episode.0 – ERROR (version 5.1.0.0, build 1 from 2014–06–19_19–02–57 by buildguy) : An error occurred duri
ng initialization, processing will be stopped:
2015/08/11 10:06:08 – Save episode.0 – Error occured while trying to connect to the database
2015/08/11 10:06:08 – Save episode.0 –
2015/08/11 10:06:08 – Save episode.0 – Error connecting to database: (using class org.apache.derby.jdbc.EmbeddedDriver)
2015/08/11 10:06:08 – Save episode.0 – Database ‘database’ not found.
...
2015/08/11 10:06:09 – Kitchen – Finished!
2015/08/11 10:06:09 – Kitchen – ERROR (version 5.1.0.0, build 1 from 2014–06–19_19–02–57 by buildguy) : Finished with errors
2015/08/11 10:06:09 – Kitchen – Start=2015/08/11 10:06:03.595, Stop=2015/08/11 10:06:09.152
2015/08/11 10:06:09 – Kitchen – Processing ended after 5 seconds.
|
This way jobs can be run by cron or executed periodically from application. Main disadvantage is that you need to monitor and parse output stream from console, if you need to get output status or stacktrace.
To run jobs from web application the easiest way is to use Carte Server. It supports communication with GET requests and XML response.
New job can be run by sending GET request to URL:
|
1
|
(host)/kettle/runJob?level=DebugLevel&xml=y&job=JOB_NAME
|
In result Carte server response with status and unique job id:
|
1
2
3
4
5
|
<webresult>
<result>OK</result>
<message>Job started</message>
<id>dccebded-0abc-4bab-9864-e10e94892d2e</id>
</webresult>
|
Unique job id must be stored to get details of a running job.
Job details can be downloaded also as an XML file. Carte server must be requested with job name and id:
|
1
|
(host)/kettle/jobStatus/?xml=y&name=JOB_NAME&id=JOB_ID
|
where JOB_NAME is job file name in repository (without kjb extension), JOB_ID is unique job id returned by previous runJob command.
Example XML response:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
<?xml version=“1.0” encoding=“UTF-8”?>
<jobstatus>
<jobname>job_main_animemgr</jobname>
<id>212ec8ee-4367-47aa-9034-52cf437e4f0e</id>
<status_desc>Finished (with errors)</status_desc>
<error_desc />
<logging_string><![CDATA[H4sIAAAAAAAAANWZW0…GgAA]]></logging_string>
<first_log_line_nr>0</first_log_line_nr>
<last_log_line_nr>469</last_log_line_nr>
<result>
<lines_input>0</lines_input>
<lines_output>0</lines_output>
<lines_read>0</lines_read>
<lines_written>0</lines_written>
<lines_updated>0</lines_updated>
<lines_rejected>0</lines_rejected>
<lines_deleted>0</lines_deleted>
<nr_errors>1</nr_errors>
<nr_files_retrieved>0</nr_files_retrieved>
<entry_nr>1</entry_nr>
<result>N</result>
<exit_status>0</exit_status>
<is_stopped>N</is_stopped>
<log_channel_id />
<log_text>2015/08/10 13:39:59 – tr_migrate_animemgr – Loading transformation from repository [tr_migrate_animemgr] in directory [/]
2015/08/10 13:39:59 – tr_migrate_animemgr – Dispatching started for transformation [tr_migrate_animemgr]
2015/08/10 13:39:59 – Get ep ID.0 – ERROR (version 5.1.0.0, build 1 from 2014-06-19_19-02-57 by buildguy) : Unable to connect to database:
2015/08/10 13:39:59 – Get ep ID.0 – Error occured while trying to connect to the database
2015/08/10 13:39:59 – Get ep ID.0 –
2015/08/10…</log_text>
<result-file></result-file>
<result-rows></result-rows>
</result>
</jobstatus>
|
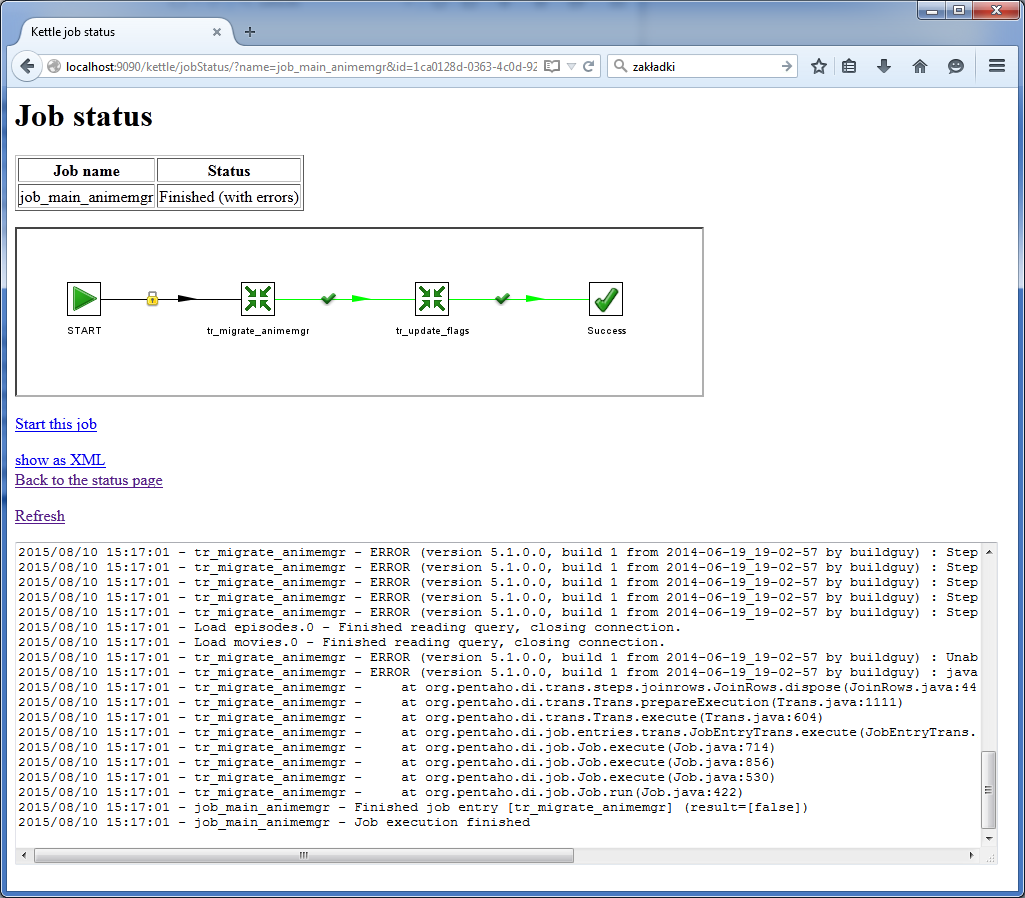
Result contains status (status_desc), full stacktrace of transformation (log_text) and statistics informations like lines read from file or saved to database, that can be used to debugging.
To integrate Carte server with Java standalone or web application we can use Apache HTTP Client with XML parser.
Sample method to retrieve XML document from url could look like this:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
public Document getDocumentFromUrl(String url, String description) {
HttpClient httpClient = HttpClientBuilder.create().build();
try {
HttpGet httpGet = new HttpGet(url);
HttpResponse httpResponse = httpClient.execute(httpGet);
HttpEntity responseEntity = httpResponse.getEntity();
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(responseEntity.getContent());
doc.getDocumentElement().normalize();
return doc;
} catch (Exception e) {
logger.error(“{} error: {}”, description, e.getMessage());
}
return null;
}
|
Starting application is achieved by sending GET request with job file name and parsing output, looking for unique id of started job:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
public String startPentahoJob(String jobName) {
Document doc = getDocumentFromUrl(getPentahoStartJobUrl(jobName), “Starting task “ + jobName);
String status = getFirstElementByTagName(doc, “result”);
if (STATUS_OK.equals(status)) {
String pentahoJobId = getFirstElementByTagName(doc, “id”);
return pentahoJobId;
} else if (status != null) {
logger.error(“Pentaho start job {} failed, status: {}, message: {}”, jobName, status, getErrorMessage(doc));
return null;
}
logger.error(“Pentaho start job {} connection error, message: {}”, jobName, getErrorMessage(doc));
return null;
}
|
Checking status is more complex, because of asynchronous nature of XML communication. Application must poll status of job in intervals to find out if job finished running. In web application it should be executed by cron/scheduler.
Response contains status description in natural text, so we need to find out if status is final (success or error) or job is still running. Carte returns final statuses:
| Value in status_desc | Description |
|---|---|
| OK | Job started with success |
| Finished | Job finished with success |
| Finished (with errors) | Job finished with execution errors |
| Stopped | Job stopped by user |
| Stopped (with errors) | Job stopped by user with execution errors |
Example java code:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
public String getPentahoJobStatus(String jobName, String objectId) {
createStatusMap();
Document doc = getDocumentFromUrl(getPentahoGetStatusUrl(jobName, objectId), “Task status “ + jobName);
String pentahoStatusDesc = getFirstElementByTagName(doc, “status_desc”);
String taskStatus = statusMap.get(pentahoStatusDesc);
String stackTrace = getFirstElementByTagName(doc, “log_text”);
if (TASK_ERROR.equals(taskStatus)) {
logger.error(“Job {} ended with status {}, descr: {}”, jobName, taskStatus);
logger.error(“Stack trace: n{}”, stackTrace);
} else if (!TASK_END.equals(taskStatus)) {
logger.info(“Job {} is still running with status {}”, jobName, pentahoStatusDesc);
taskStatus = TASK_RUNNING;
} else if (taskStatus == null) {
logger.error(“Task status {} cannot get job status”, jobName);
taskStatus = TASK_CONN_ERROR;
}
return taskStatus;
}
|
Pentaho Data Integration is powerful platform that can be easily combined with java applications.
It allows developers to create fast, multi-threading ETL processes for business data processing.
Example project (with sources used in this article) can be downloaded from: Pentaho example project




