


The problem is quite simple – they want to implement three methods:
In this article, they will compare the implementations of the above problem using various mechanisms provided in further Java language versions. In the end, they will compare results with a native image of Java code compiled using GraalVM. For simplicity, they will focus on implementations and running time results for extract words method. The code presented below will be tested on two machines:
Intel® Core™ i7-8850H CPU @ 2.60GHz × 12 15,5 GiB
Intel® Core™ i5-8400H CPU @ 2.50GHz × 8 15,5 GiB
Input data that we will use in the following implementations is a text file containing about 25 000 words.
Let’s start with implementation of the extract words method using StringTokenizer available since Java 1.0.

The running time on the test data is about 0.020 ms – for now, it doesn’t tell as a lot about the performance – is the solution efficient enough or can we do it better? Now let’s see an implementation using standard library 1.5. We can simplify our code using the Scanner class which gives us methods to read a file and split the content into tokens by the specified separator.

The running time of the above solution is 0.099 ms – it turns out that the Scanner is based on a regular expression which causes the performance issue and we get 5 times slower implementation compared to StringTokenizer. In the following implementation, we will add features from Java 8 – the Paths class.

The time results we have received are worse than the previous implementation – about 0,0912 ms. In the next attempt, we will switch to Java 8 and we will use the power of streams.

Now the running time is about 0.057 ms – it is better than our last solution implemented in Java 1.7 but almost 3 times slower than the first code. It looks like streams add extra run-time overhead but there is still hope – now we will use parallel streams.
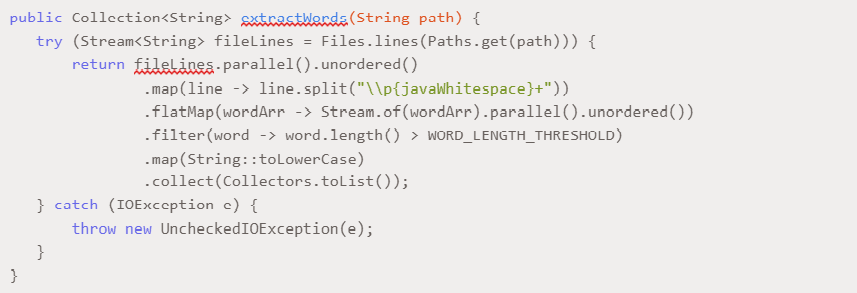
Now is the moment of truth, is this solution faster than all previous ones? The running time is 0.072 ms – it turns out that our parallel implementation is slower than the single-threaded solution. This result shows that the use of concurrency does not always mean increased performance.
Jonathan showed them how to compile Java code to native images using GraalVM. One of the main features of GraalVM is ahead-of-time compile Java (or any other JVM-based language) code to the standalone executable which includes all needed runtime special components. This executable has better performance than pure Java application. They’ve decided to test this tool ourselves using the same code above. The results of their tests are presented in the chart below.

They run native-image for two implementations (CalculatorJ2 and CalculatorJ8) and C++ version provided by Jonathan (the code is available in the repository). As you can see, Java 8 implementation after compilation to the native image is much faster than pure Java version. Interesting thing is, that the performance of implementation which uses StringTokenizer is comparable to a native C++ application. As you can see, performance growth is considerable.
All the source code and test data can be found on: https://github.com/jonatan-kazmierczak/words-frequency-calculator
They encourage to read more about GraalVM.

